







Q-Former是一种融合视觉和语言模型的方法,用于BLIP-2中结合预训练的图像编码器和大型语言模型。Q-Former通过可学习的查询(软提示)将视觉语义表示转化为文本语义。它使用跨注意力机制,通过可学习的查询从图像编码器聚合视觉特征。该架构受到Flamingo的感知器重采样器启发。
Q-Former 简介
Q-Former 是 BLIP2 框架中用于实现视觉语义与大规模语言模型(LLM)语义高效融合的关键模块。其主要思想在于利用一组可学习的“软提示”(Learnable Queries),直接将经过预训练的视觉编码器提取到的视觉特征,通过交叉注意力(Cross Attention)的机制转化为更适合后续 LLM 理解的视觉语义表示,从而有效地减少信息转换过程中可能产生的细粒度信息损失。

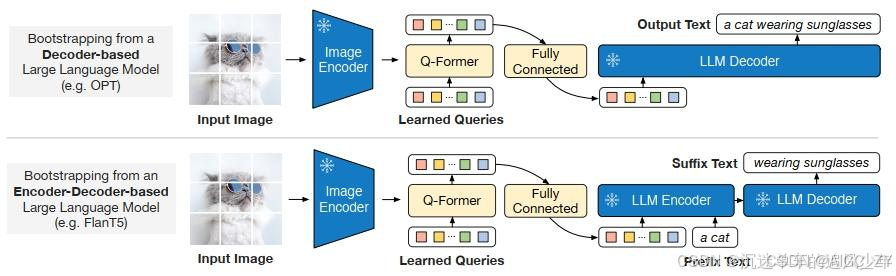
视觉和语言需要一个能对接的桥梁。Q-Former旨在冻结的视觉模型和大型语言模型之间进行视觉-语言对齐,以学习与文本最相关的视觉表示,并使这种表示能够被大语言模型所解释。
·阶段一:视觉-语言表示学习,迫使Q-Former学习和文本最相关的视觉表示。
·阶段二:视觉到语言生成式学习,将Q-Former的输出连接到冻结的大语言模型,迫使Q-Former学习到的视觉表示能够为大语言模型所解释。
Q-Former的结构
Learnable queries + self-attention + cross-attention + FFN
其实就差不多是transformer的encoder

核心思想
-
直接的语义迁移
传统方法通常通过图像描述(Captioner)将视觉信息转换为文字,再输入到 LLM 中进行处理,这在多个阶段上都会丢失原始视觉的细粒度信息。Q-Former 则直接利用视觉编码器得到的特征,加上可学习的软提示,将视觉语义以向量形式迁移到文本语义空间,从而达到更低的信息损失。 -
可学习的软提示
Q-Former 中引入的 “Learnable Queries” 类似于 prompt tuning 的思想。这些查询向量在训练中不断优化,起到辅助信号的作用,帮助将视觉特征更好地转化为语言特征。 -
交叉注意力机制
模块通过交叉注意力机制,将视觉编码器输出的视觉特征(作为 Key 和 Value)与可学习的查询(作为 Query)进行信息融合,最终输出一个固定长度的 “Transferred vision representation”。这种设计部分受到了 Flamingo 中 Perceiver Resampler 的启发。
训练策略

Q-Former 的训练分为两个阶段:
-
第一阶段:跨模态表征融合
在这一阶段中,利用图像-文本对数据,通过以下三种损失函数进行训练:- 对比损失(ITC):确保视觉和文本特征在共享空间内具有较高的匹配度。
- 匹配损失(ITM):通过正负样本评分强化细粒度的语义对齐。
- 生成损失(ITG):通过特定的 mask 策略控制不同部分的交互,防止信息泄漏,确保生成过程的有效性。
-
第二阶段:与 LLM 联合训练
将第一阶段得到的视觉语义输出通过全连接层接入 LLM,根据 LLM 的架构(如 decoder-only 或 encoder-decoder)采用不同策略进行进一步的生成式预训练,从而构建多模态大语言模型(MLLM)。
总结
Q-Former 通过直接在高维向量空间中进行视觉与文本语义的融合,不仅减少了传统方法中多阶段转换带来的信息损失,同时在参数量较少的情况下显著提升了模型在多项任务上的 zero-shot 表现。虽然当前 BLIP2 模型在 in-context learning 和 LLM 固有缺陷方面仍存在挑战,但 Q-Former 为多模态模型设计提供了一个具有启发性的解决方案。

















 1910
1910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









