







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
每天学习一个小技巧,让枯燥无味的生活变得充实有趣吧~
上一期我们学习到了如何通过Ollama在本地部署我们需要的大模型,那我们如何进阶的学习和了解AI呢,这一期我们来学习如何通过Python调用我们本地部署好的大模型,让我们在研究AI的道路上愈发闪亮!!!
Ollama大模型接入
一、Python代码实现
这里展示了一段本地持续问答的代码,调用了本地的大模型,我们可以输入任意内容,并回收到大模型的回复。
import requests
import json
def chat_ollama():
while True:
str = input()
if str == 'exit': # 输入exit 可以帮助我们退出程序
break
url_chat = "http://localhost:11434/api/chat"
data = {"model":"gemma:2b", "stream":False, "messages":[{"role": "user", "content": str}]}
response = requests.post(url_chat, json=data)
response_dict = json.loads(response.text)
print(response_dict) # 大模型的全部内容整理成字典格式
print(response_dict["message"]["content"]) # 大模型的回复内容
chat_ollama()
if __name__ == '__main__':
chat_ollama()
我们将这一段代码运行,我使用的是Pycharm软件,选择当前文件,并点击三角号,我们就可以运行代码啦~

运行后,我们和他交流一下看看效果如何?
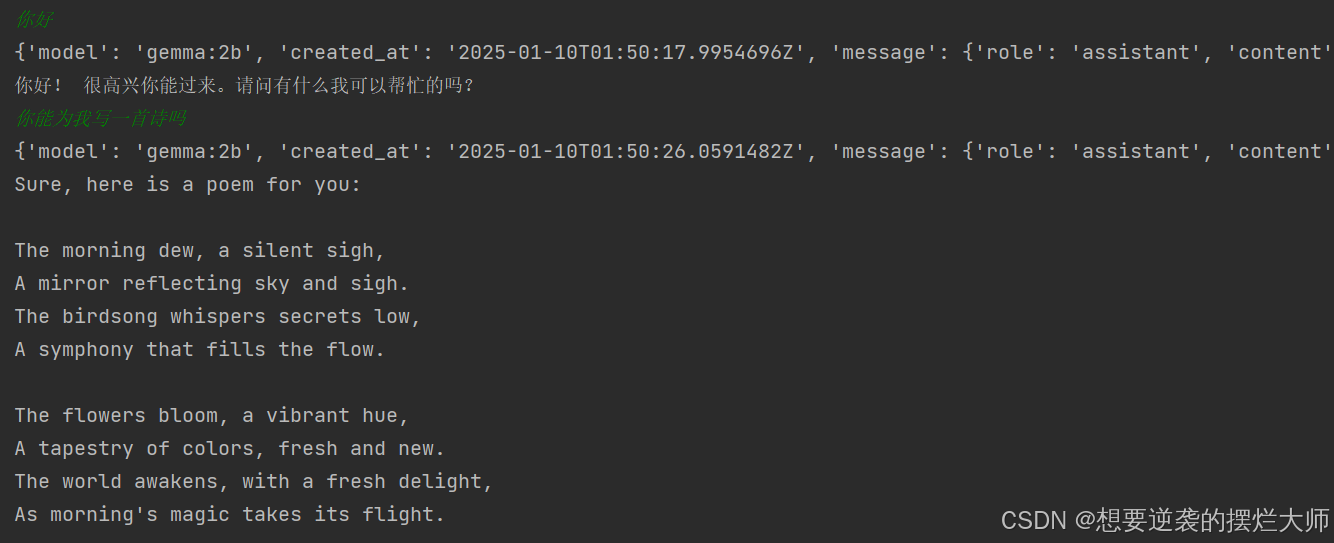
这里我们可以看到,大模型已经可以和我们进行持续对话了,绿色的是我们的输入内容,白色字是大模型对我们的回复。
二、FastApi搭建后端
概念
FastAPI是一个现代、快速(高性能)的Python web框架,专门用于构建基于RESTful风格的API应用。它基于标准的Python类型提示,使用Python 3.6+构建。FastAPI的主要特点包括高性能、类型注解和自动文档生成、依赖注入系统和异步支持。
安装库
pip install fastapi uvicorn
代码实现
这里不会的小伙伴可以直接搬迁代码,或者根据自己需要适当的修改参数和方法以得到自己期待的效果哦~
下面我们来展示一下所需要的全部代码:
导入需要的库和基础的配置
import subprocess
import requests
app = FastAPI(title="Ollama API Interface")
# 基础配置
OLLAMA_BASE_URL = "http://localhost:11434"
DEFAULT_MODEL = "qwen2.5:7b"
所需类定义
class ChatMessage(BaseModel):
role: str
content: str
class ChatRequest(BaseModel):
model: str = DEFAULT_MODEL
messages: List[ChatMessage]
stream: bool = False
options: Optional[Dict[str, Any]] = None
class ChatResponse(BaseModel):
message: ChatMessage
model: str
done: bool = True
接口类实现
@app.post("/v1/chatContext", response_model=ChatResponse)
async def chatContext(request: ChatRequest):
print(request)
print(request.model)
"""聊天接口"""
try:
contextSplit = request.messages[:4]
# 将 ChatMessage 列表转换为字符串列表
context = [f"{message.role}: {message.content}" for message in contextSplit]
# prompt = request.messages[-1].content # 将对话历史和当前提示组合成一个长的上下文
# 将对话历史和当前提示组合成一个长的上下文
prompt = "\n".join(context) + "\n" + request.messages[-1].content
print(context)
print(prompt)
async with httpx.AsyncClient() as client:
response = await client.post(
f"{OLLAMA_BASE_URL}/api/generate",
json={
"model": request.model,
"prompt": prompt,
"stream": request.stream,
**(request.options or {})
},
timeout=120.0
)
response.raise_for_status()
data = response.json()
print(data)
return ChatResponse(
message=ChatMessage(
role="assistant",
content=data.get("response", "")
),
model=request.model
)
except httpx.HTTPError as e:
raise HTTPException(
status_code=500,
detail=f"httpx.HTTPError == Failed to communicate with Ollama: {str(e)}"
)
except Exception as e:
raise HTTPException(
status_code=500,
detail=f"Error processing request: {str(e)}"
)
程序启动入口(python代码主函数)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
不会写Python的同学也不要灰心,遇事不决就问AI,AI会帮我们生成我们所需要的相关内容~
三、预览效果
接下来就是见证奇迹的时刻了,我们既然有了这么多的功能,那我们运行后如何使用这个接口呢?如何在这个接口内得到我们所需要的答案呢?
首先,我们需要本地访问FastApi的服务:localhost:8080/docs
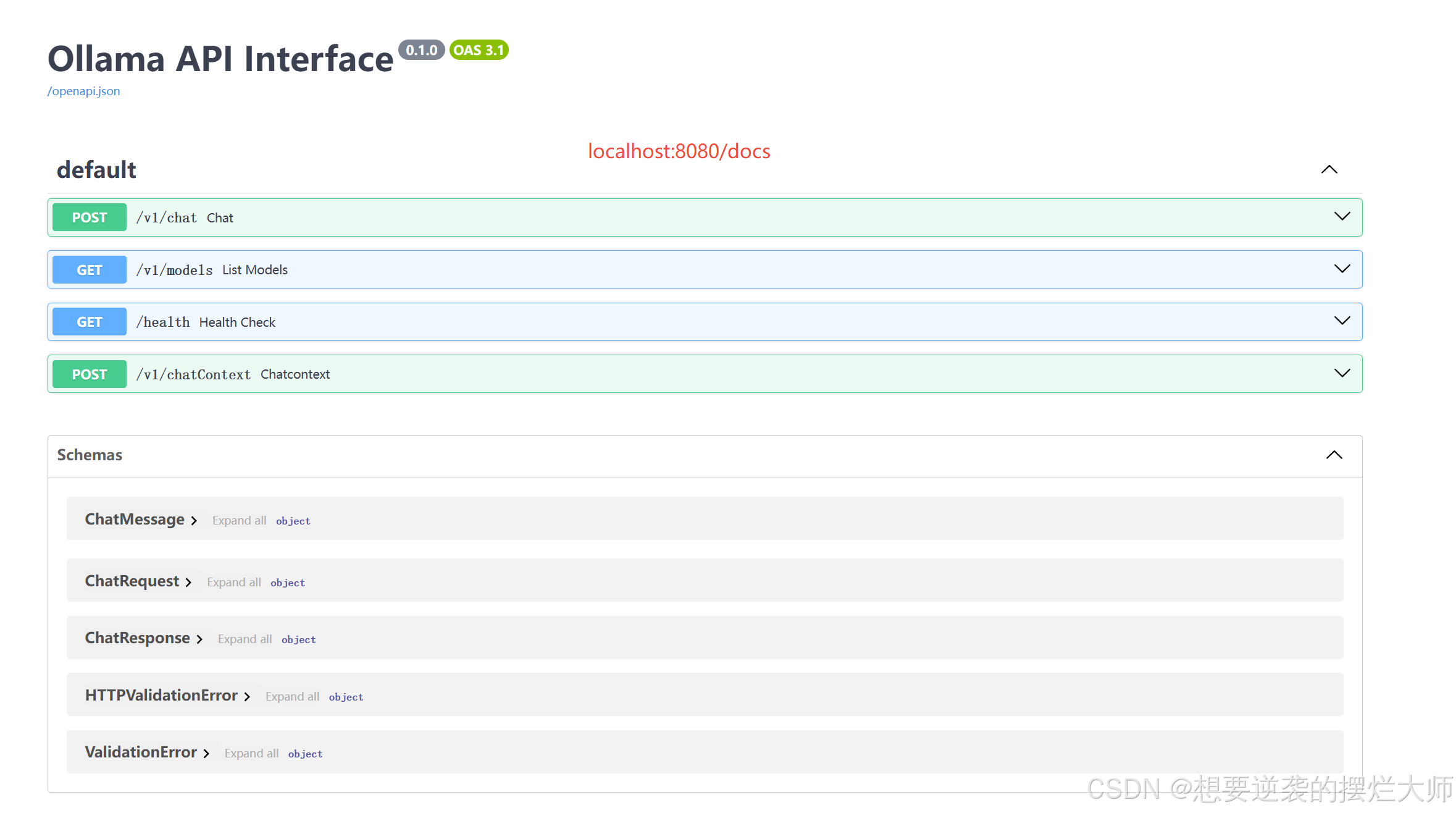
我们打开需要的接口,并输入我们的问题,可以看到大模型给我们的回复:
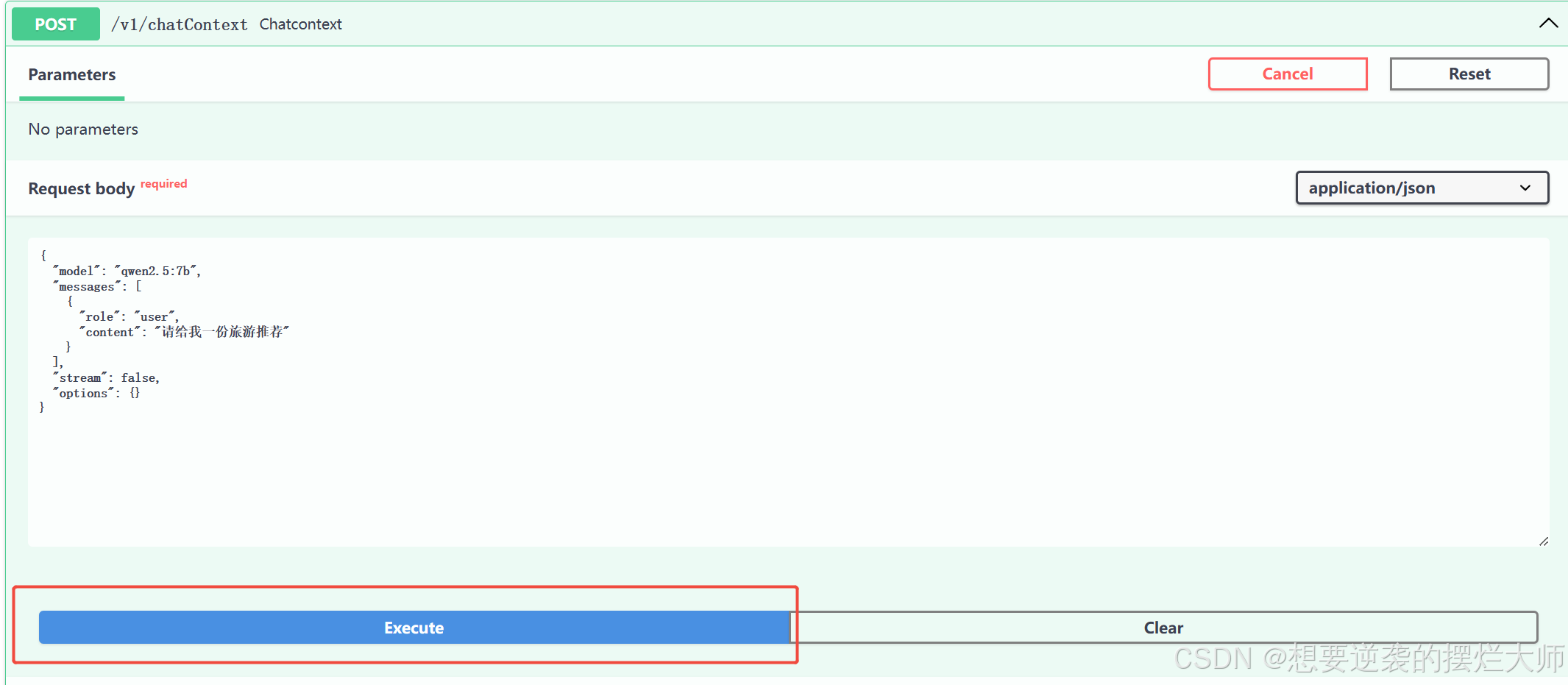

我们可以通过这个页面对我们的接口进行功能测试,也可以对他传递多轮对话,结果如下:
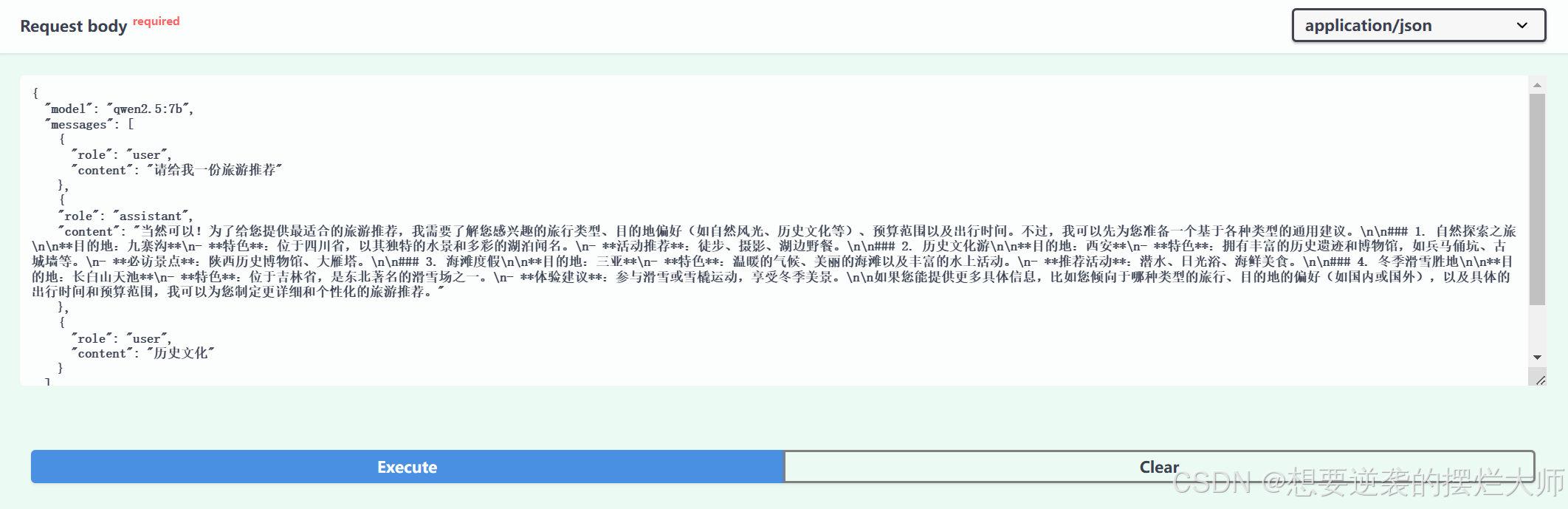

我们可以看到,它不仅回复了我们相关历史文化,还结合了上下文,对我们想要的旅游推荐进行了响应,至此,我们所有的功能都已经完成了,快和你的小伙伴炫耀一下吧~
四、遇到的问题
大模型的调用是十分耗费我们性能的,只使用CPU对我们的使用来讲十分不友好,那我们如何解决大模型调用慢的问题呢?
1.大模型调用慢,超时如何解决
概念:
1、CUDA(Compute Unified Device Architecture)是NVIDIA推出的一款通用并行计算平台和编程模型,允许开发者利用GPU进行高性能计算。它提供了一组工具、库和语言扩展,使得开发者能够为GPU编写程序,从而利用GPU的并行处理能力来加速计算密集型任务。CUDA适用于科学计算、机器学习、图像处理和视频处理等领域。
2、cuDNN(CUDA Deep Neural Network library)是NVIDIA为深度学习设计的GPU加速库。它基于CUDA构建,提供了深度学习中常用操作的高效实现,如卷积、池化、归一化和激活函数等。cuDNN旨在提高深度学习模型训练和推理过程的效率,通过利用GPU的并行计算能力来加速这些操作。cuDNN可以集成到高级机器学习框架中,如TensorFlow和PyTorch,以提供GPU加速。
解决方案:
根据上面看到的我们可以借助CUDA和CUDNN这两个工具帮我们加速大模型的加速,借助GPU帮助我们提升速度,那我们如何去安装呢?
资源网页:
CUDA
CUDNN
根据网页下载对应我们所需的工具型号:
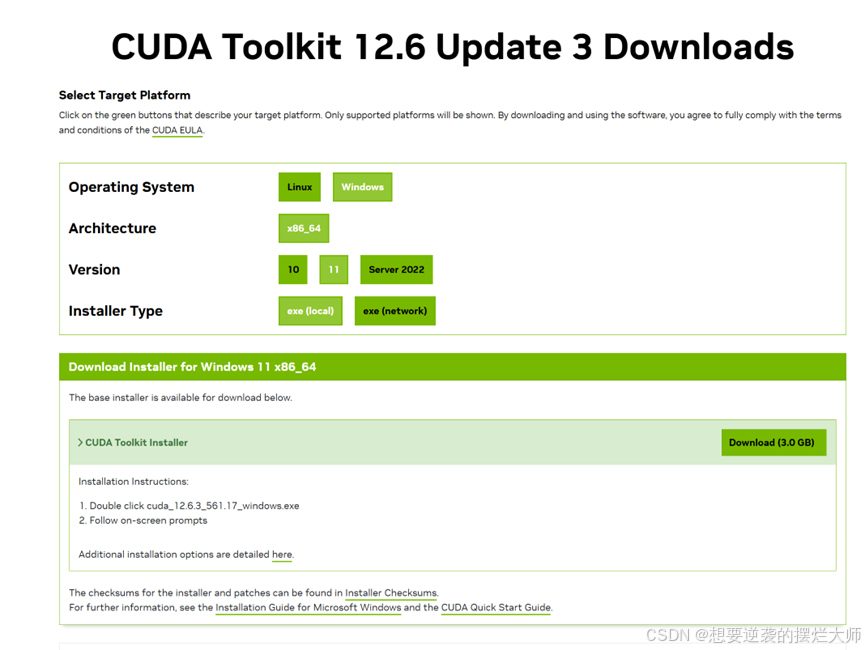
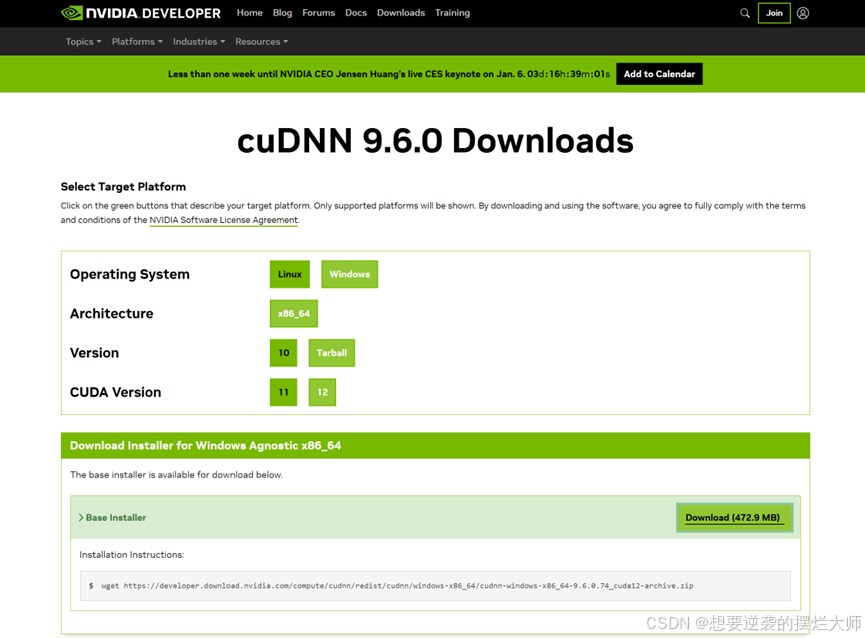
更详细的安装请参考:如何在Win11上搭建一个GPU环境
总结
AI已经慢慢走入了我们生活的方方面面,我们可以借助这些强大的AI工具为我们有趣的生活添砖加瓦!
有用的网址Up:
FastApi:官方文档

















 1106
1106

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









