







Contextual Transformation Network for Lightweight Remote-Sensing Image Super-Resolution
论文地址
摘要:
当前的超分辨率网络通常通过设计轻量级结构来减少网络参数和多加操作,但轻量化卷积层往往被忽视。在这项工作中,我们观察到 3×3 卷积在大多数轻量级超分辨率网络中占据了很大比例的网络参数。这促使我们考虑通过用轻量级卷积替换 3×3 卷积来减轻超分辨率网络,同时保持性能。为此,我们提出了一个名为上下文转换层 (CTL) 的轻量级卷积层。它可以通过上下文特征提取模块产生有效的上下文特征,并通过上下文特征转换模块丰富提取的上下文特征。基于 CTL,我们构建了一个轻量级超分辨率网络,称为上下文转换网络 (CTN),用于遥感图像超分辨率。具体来说,我们使用两个 CTL 来构建一个上下文转换块 (CTB) 用于分层特征学习。与 CTB 交错使用上下文增强模块 (CEM) 来增强提取的特征表示。所有提取的特征都由上下文特征聚合模块处理,用于最终的遥感图像超分辨率。在名为 UC Merced 的遥感图像超分辨率基准上进行了大量实验。我们的方法取得了优于其他最先进方法的结果。为了展示我们的 CTL 的泛化能力,我们将 CTN 扩展到两个相关任务:自然图像超分辨率和自然图像去噪。自然图像超分辨率基准(即 Set5、Set14、B100、Urban100 和 Manga109)和自然图像去噪基准(即 SIDD 和 DND)的实验结果进一步证明了我们方法的优越性。代码可在https:/github.com/BITszwang/CTNet 上公开获得。
I. 引言
超单图像超分辨率(SISR)旨在从相应的低分辨率(LR)图像重建高分辨率(HR)图像,在计算机视觉界引起了广泛的研究关注。SISR 在遥感过程 [1]、[2]、图像和视频分析 [3]-[5]、智能手机照片 [6]、[7] 和医学成像分析 [8] 等各种应用中发挥着重要作用, [9].在遥感领域,由于卫星成像设备的限制,遥感图像的分辨率有限,不利于后续的遥感解译任务(如目标检测[10]、[11]、场景分类 [12]、[13] 等)。升级卫星成像设备可以提高遥感图像的分辨率,但这种方法成本很高。因此,利用SISR技术提高遥感图像的空间分辨率是一种有效的方法。
随着深度学习技术的成功,近年来RSISR得到了显着改进。已经提出了许多基于深度学习的遥感图像超分辨率(RSISR)方法[14]-[17]。例如,Haut 等人。 [14] 采用视觉注意机制来引导网络学习更有效的特征表示。潘等。 [16] 为 RSISR 的中值和大高档因子提出了一个残差密集反投影网络。董等。 [17] 设计一种密集采样机制来指导网络考虑多尺度特征以进行大规模 RSISR 重建。尽管上述方法取得了可喜的性能,但它们通常都具有复杂的网络结构,并且需要高性能计算平台来部署和运行。因此,研究轻量级的RSISR具有重要意义,它有望在模型大小和计算复杂性方面都具有效率。
最近的一些研究已经朝着这个研究方向进行了初步尝试。例如,[18] 和 [19] 中提出了递归神经网络,以通过递归卷积层重用网络参数。然而,这些方法通常需要非常深的网络才能实现令人满意的超分辨率性能,从而导致高计算复杂度。这限制了它们在实时场景中的应用。另一系列作品 [20]-[22] 考虑了轻量级网络设计的信息蒸馏。尽管这些方法大大提高了性能,但它们的模型仍然具有大量参数。
为了设计专用的轻量级超分辨率网络,我们从精心的实验分析中发现,现有模型需要大量的 3×3 卷积来表示特征并且这些卷积在整个网络中占据了很高比例的参数,如表一所示。
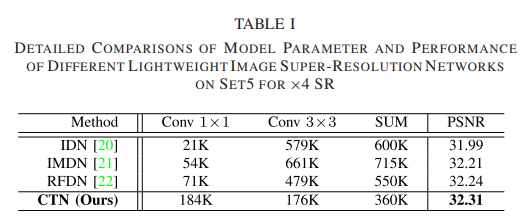
例如,在 IMDN [21] 中,92.4% 的参数来自 3 × 3 卷积,而 RFDN [22] 和 87.1% 的参数IDN [20] 为 96.5%。鉴于这些卷积通常是多余的,因此有希望在保持模型性能的同时减轻它们。使用 1×1 卷积代替 3×3 卷积可以减少网络参数,但 1×1 卷积由于感受野有限无法有效捕获图像上下文信息,从而损害超分辨率质量。为此,我们的工作旨在通过合并更多的上下文信息来补偿 1×1 卷积的输出特征。通过这种方式,我们的网络避免了对 3×3 卷积的强依赖,而没有明显的性能损失,从而形成了一个轻量级但强大的网络。
为此,我们设计了一个轻量级的卷积层,称为上下文转换层 (CTL),以实现轻量级- 权重 RSISR。 CTL包括两个模块,即上下文特征提取和上下文特征转换。前者旨在提取局部上下文特征,主要通过 1×1 卷积实现,而后者通过高效的深度卷积进一步丰富局部上下文表示。受益于这些设计,与普通的 3×3 卷积相比,我们的 CTL 可以用少量的网络参数获得更全面的特征表示。
基于 CTL,我们为轻量级 RSISR 构建了上下文转换网络(CTN),如图所示在图 2 中。CTN 的核心是上下文转换块 (CTB),每个块都被设计为两个堆叠的 CTL。这些块依次应用于分层特征提取。在每个 CTB 之后,我们应用上下文增强模块 (CEM) 来进一步增强提取的特征。为了为 RSISR 实现更全面的特征表示,我们最终聚合了来自每个 CTB 的层次特征,并通过上下文特征聚合模块将它们融合在一起以进行最终预测。与其他最先进的轻量级超分辨率网络相比,我们的 CTN 可以用更少的参数实现更好的重建性能(见图 1)。
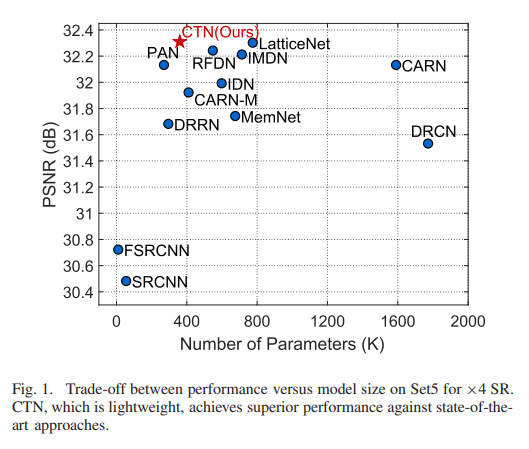
此外,我们通过相关任务展示了 CTN 的优势和泛化能力自然图像超分辨率和自然图像去噪。事实证明,我们的模型可以很好地概括这些任务,并在常用基准测试中展示出高质量的恢复性能。
总而言之,我们的贡献有以下三方面。
1)我们提出了一种以轻量级方式提取上下文特征的 CTL。与普通的卷积层相比,CTL可以减少数量
2)我们提出了一个上下文特征聚合模块,以自适应和轻量级的方式聚合不同的上下文特征。
3)基于CTL和上下文特征聚合模型,我们提出了一种名为CTN的轻量级RSISR网络。我们的方法在常用的超分辨率基准测试上取得了优于其他最先进的方法的结果。
二 相关工作
三、提议的方法
在本节中,我们将首先介绍我们的 CTN 的概述。然后,详细演示了上下文特征转换和聚合组件。接下来,我们对 CTN 进行了一些有见地的讨论,最后展示了对其他任务的扩展。
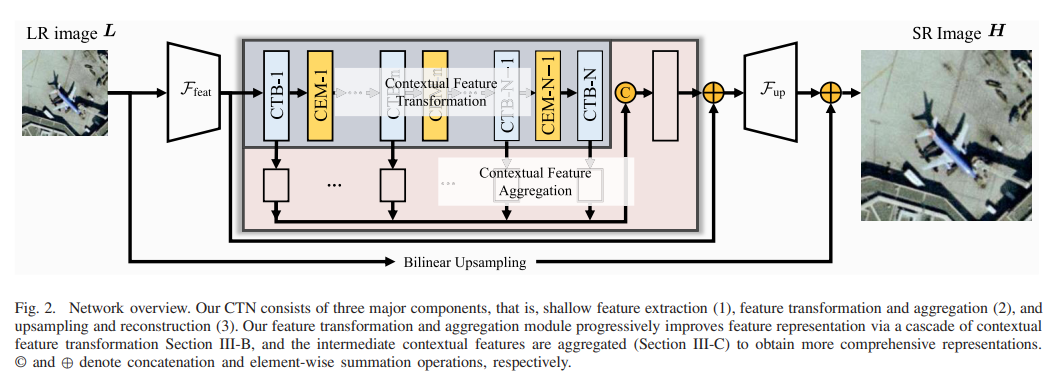
A. Network Architectur网络架构
在这项工作中,我们为 RSISR 提出了一个完全端到端的可训练网络,即 CTN。如图 2 所示,我们的网络被设计为三个紧密耦合组件的统一:浅层特征提取 Ffeat、特征转换和聚合 Fta,以及上采样和重建 Fup。特别地,给定一个空间大小为 H × W 的低分辨率图像 L ∈ RH×W×3,我们的模型获得 HR 预测 H 如下:
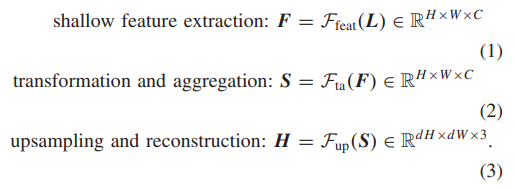
浅层特征提取:F = Ffeat(L) ∈ RH×W×C (1)变换和聚合:S = Fta(F) ∈ RH×W×C 上采样和重构:H = Fup(S) ∈ RdH×dW×3。
这里,d(d > 1)是一个超分辨率尺度因子,C 表示通道数。 F 和 S 分别表示来自 Ffeat 和 Fta 的特征表示。我们分别使用[60]中的 3×3 卷积和上采样块实现 Ffeat 和 Fup。为了实现轻量级 RSISR,我们贡献了特征转换和聚合模块 Fta,它能够以轻量级方式学习综合特征表示.具体来说,该模块由两个基本组件组成:上下文特征转换(第 III-B 节)和上下文特征聚合(第 III-C 节)。上下文特征转换主要是与拟议的CTB和CEM一起实施。上下文特征聚合是通过串联操作的分组卷积实现的。
B. 上下文特征转换 Contextual Feature Transformation
为了学习全面的层次特征表示,我们提出了一个级联的 CTB,它们与 CEM 交错。该架构如图 2 所示。正式地,在第 n 个级联阶段,学习过程可以写为
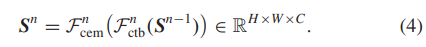
在这里,Fncem和Fnctb分别表示第n个CEM和第n个CTB。在方程(4)中,输入Sn−1首先由轻量级CTB Fn ctb处理以获得全面的特征表示,并通过结合局部上下文知识在CEM Fn cem中进一步增强这些特征表示。
1)上下文转换块(CTB)是CTN用于学习分层特征的基本组件。如图3(a)所示,参照[38],每个CTB以残差的方式由两个连续的CTL组成,以避免信息丢失。其数学表达式如下:
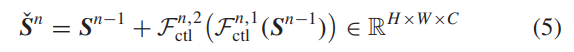
其中,Fn,1ctl和Fn,2ctl表示两个CTL,Sˇ n是第n个CTB块的输出。如图3(b)所示,每个CTL包含两个模块:上下文提取Fce和上下文转换Fct。我们将详细介绍上述两个组件。
a) 上下文提取:如图3(c)所示,它是上下文提取模块的结构。给定第n个CTB中第b个CTL的输入特征Sn,b∈RH×W×C (当b = 1时,C = C;当b = 2时,C = C/2),它将按照以下函数进行处理:
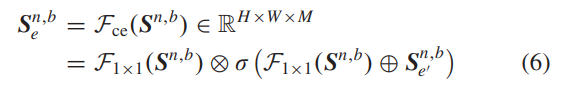
其中,σ表示sigmoid操作。F1×1是一个1×1的卷积层。⊕表示元素级别的加和,⊗表示元素级别的乘法。M = C/R 表示特征通道数,其中R是通道缩减比率。Sn,b e ∈ RH×W×M编码了局部上下文信息,该信息通过三个连续层获得:平均池化→1×1卷积→双线性上采样。在平均池化层中,核大小和步幅均设置为2。
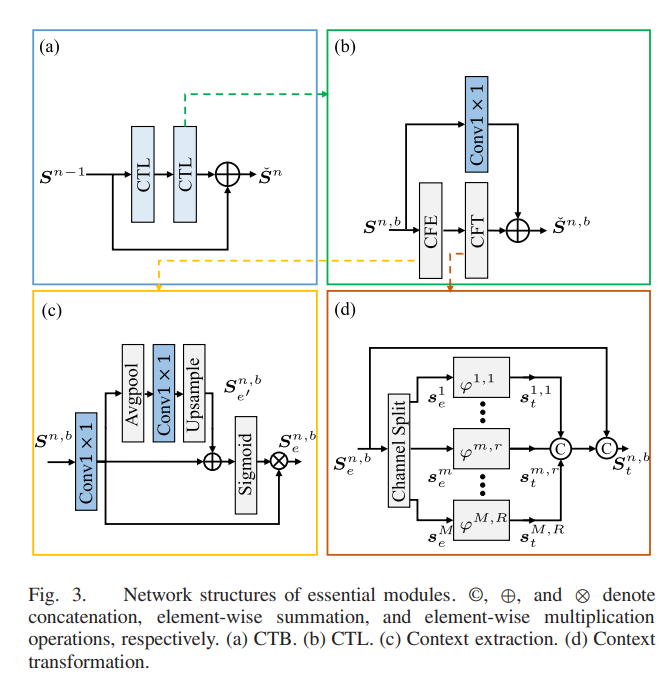
b) 上下文转换:上下文转换模块被提出用于转换提取出来的特征,以丰富上下文特征表示。受[61]的启发,我们应用一组线性变换来进行特征转换,以丰富上下文特征表示,具体如下:
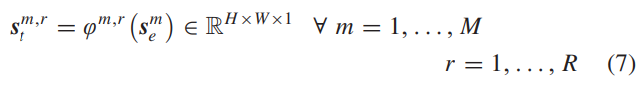
其中,sm e是Sn,b e中的第m个本征特征图,ϕm,r表示用于生成第r个特征表示sm,r t的第r个线性变换。总共有T = M × (R - 1)个线性变换,以及一个恒等映射操作用于保留本征特征映射,如图3(d)所示。因此,通过使用(7),我们可以得到Sn,b t的计算方式如下:
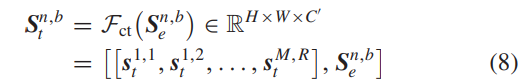
其中,[·]表示连接操作。然而,由于对Fct的输出缺乏监督,我们无法保证提取的具有上下文感知的特征Sn,b t是有信息的。因此,引入一个1×1的卷积层以残差方式添加到CTL中,用于增强上下文感知特征表示。因此,第n个CTB中的第b个CTL可以表示为:
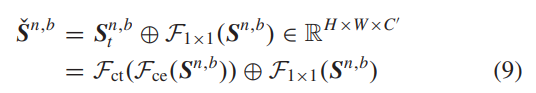
其中,第n个CTB中第b个CTL的输出和输入特征分别表示为Sˇ n,b和Sn,b。
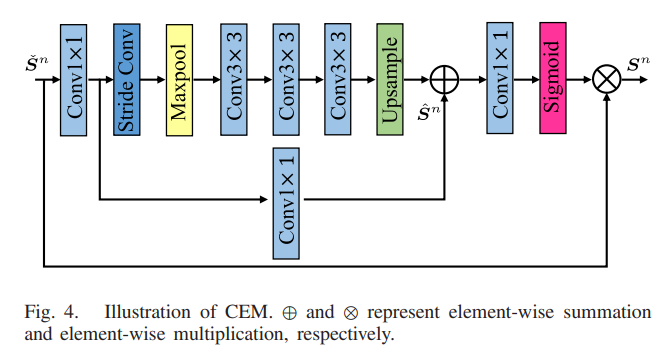
2)上下文增强模块:虽然CTB被用于提取上下文特征,但是浅层的CTB具有有限的感受野,因此不能捕获足够的上下文信息用于后续特征学习。可以进一步扩大CTB的感受野,以便提取更多的上下文信息用于RSISR。这里,我们采用了一个基于增强空间注意机制的CEM [22],如图4所示。每个CEM的实现如下:
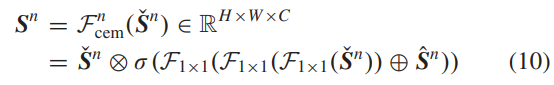
其中,第n个 CEM 的输出和输入分别表示为Sn和Sˇn。Sˆn ∈ RH×W×C 表示上下文增强特征,由六个连续操作实现,包括步幅卷积→最大池化→3×3卷积→3×3卷积→3×3卷积→双线性上采样。在步幅卷积层中,内核大小为3,步幅为2。在最大池化层中,内核大小为7,步幅为3。由于 CEM,CTN 可以高效地获取足够的上下文信息,有助于网络重建更清晰的视觉结果。
C. 上下文特征聚合
以往的方法[21],[22]通常采用连接操作来直接聚合不同层级的特征,并应用融合层来减少聚合特征的通道数。虽然它们取得了令人满意的性能,但融合层通常占用大量的网络参数,这是不可忽视的。为此,我们提出了一个上下文特征聚合模块,采用分组卷积和标准的1×1卷积来自适应地聚合分层特征。首先,将每个Sˇ n根据通道维度分成(C / N)组。然后,通过(C / N)个分组卷积来处理分组特征:
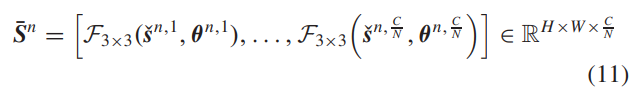
其中,sˇn,i ⊆ Sˇ n 是被分为第 i 组的输入特征的子集。F3×3 表示深度卷积 3×3 层。θ n,(C/N) 是第 (C/N) 个 F3×3 的学习权重。之后,我们使用连接操作来聚合 S¯n,聚合的上下文特征为 S¯ = [S¯1,S¯2,…,S¯N] ∈ RH×W×C。最后,采用 1×1 卷积层处理 S¯,并将结果与浅层特征 F 融合,具体实现如下:
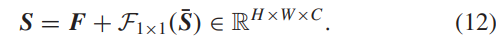
请注意,我们的上下文特征聚合模块并不是直接采用concatenate操作的特殊情况。具体来说,为了考虑分层特征对于遥感图像超分辨率的贡献,我们首先使用分组卷积提取信息表示,然后通过通道concatenate操作进行聚合。与加权求和不同,我们的上下文特征聚合模块可以保持代表性的分层特征,这对于接下来的图像重建更加有帮助。
D. 讨论
1)CTL 如何减少网络参数?:
我们的 CTL 从两个方面减少了参数的数量:
1)为了获得有效的上下文表示,我们利用与精心设计的非参数操作相关的 1×1 卷积来进行上下文建模。
2)为了获得丰富的上下文表示,我们采用一组深度卷积来增加上下文特征的多样性。在上述两种策略的帮助下,我们的模型以更少的网络参数实现了有希望的性能。
2)与其他轻量级超分辨率模块的区别:图 5 展示了不同的轻量级超分辨率模块。
a)信息蒸馏块。:信息蒸馏块被广泛应用于许多轻量级超分辨率网络[20]-[22]。如图5(a)所示,它根据通道维度将输入特征分成两部分。一部分通过以下卷积处理以扩大感受野,而另一部分则保持并与提取的大感受野特征连接。然而,由于特征处理分支的实现,网络参数量对于现实场景来说仍然很大。
b)自校准卷积。:Zhao et al。 [60]采用改进的自校准卷积[62]构建LR特征学习的基本块,如图5(b)所示。两个操作分别处理输入特征。一种操作是用于特征维护的卷积。另一个操作是设计的自校准卷积到获取远程上下文信息。两个操作的输出在特征表示的通道维度中连接。与使用信息蒸馏块 [20]-[22] 实现的网络相比,具有自校准卷积的网络的参数减少了,但最终的 SR 性能也下降了。
c)格块。:Luo 等人。 [56]构建了一个名为 Lattice block 的高效轻量级图像超分辨率模块,如图 5(c)所示。它可以看作是两个卷积的各种组合,为图像超分辨率提供了丰富的特征表示。然而,格块的参数大于信息蒸馏块和自校准卷积,这促使我们设计一个参数更少的有效 SR 块。
d)上下文转换层。:图 5(d)说明了我们提出的 CTL。它与自校准卷积具有相同的结构,但它们背后的动机不同。自校准卷积拥有一个上下文学习分支,它提供上下文信息来指导特征分支学习。相比之下,CTL 设计了一个特定的上下文转换分支,可以生成具有理想参数的丰富的上下文表示。上述轻量级模块的更详细的性能比较可以在第 V-B.节中看到
3 )为什么 CTN 对 RSISR 表现良好?:
与自然图像相比,遥感图像具有不同的场景,每个场景通常拥有一个复杂的对象分配。同时,遥感图像的对象比自然图像小。所有这些都对 RSISR 提出了挑战。我们提出的 CTN 可以从两个方面很好地解决上述挑战。具体来说,CTB可以生成多样的层次特征,有助于不同遥感场景和物体的重建。 CEM 可以使用更多上下文信息增强特征表示,这对小对象重建很有用。以上两个模块都是轻量级实现的。因此,CTN 的网络参数比当前最先进的 RSISR 网络更小。第五节 A 中的实验结果证明了我们方法的有效性。
四、CTNI的扩展
在本节中,我们描述了CTN对自然图像超分辨率和自然图像去噪的扩展。前者侧重于从LR输入重建HR自然图像。自然图像超分辨率自然图像超分辨率与遥感图像超分辨率非常相似。他们都被赋予一个LR图像来重建一个HR图像。这两个任务之间的区别在于图像的内容。具体而言,自然图像超分辨率旨在超分辨具有复杂多样纹理的各种自然物体,这对CTN提出了挑战。因此,为了评估我们方法的泛化能力,我们直接应用 CTN,没有任何修改自然图像超分辨率。不同方法的详细性能比较和分析可以在V-B节中看到。
B. 自然图像去噪我们的 CTN 可以灵活地适应自然图像去噪任务,并进行一些修改。由于图像去噪的输入和输出的空间大小相同,因此我们不需要上采样模块来放大特征空间大小,并将其从CTN中删除。为了与其他图像去噪方法进行公平比较,我们仅采用L1损耗来优化我们的网络[63]。特别地,给定空间大小为H×W的∈RH×W×3中的噪声图像,CTN可以获得干净的预测Ic如下:
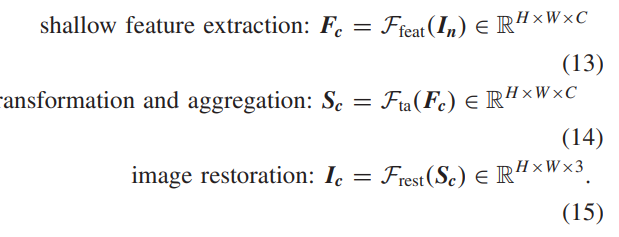
这里,C▁表示通道号。Fc▁和▁Sc▁分别表示来自▁Ffeat▁和▁Fta▁的特征表示。我们分别使用▁3×3▁卷积实现▁Ffeat▁和▁Frest。不同图像去噪方法的详细性能比较可以在第▁V-C▁节中看到。
V. 实验
在本节中,我们将在主要任务 RSISR(第 V-A 节)上将 CTN 与最先进的 RSISR 方法进行比较。然后,我们探讨了CTN在自然图像超分辨率(第V-B节)和自然图像去噪(第V-C节)方面的性能。对于每个任务,我们分别说明数据集、实现细节和实验结果。最后,为了更深入地了解我们的模型,我们在V-D部分进行了详细的消融研究。
A. 主要任务:遥感图像超分辨率
1)数据集:我们在加州大学默塞德分校 [70] 数据集上进行实验以评估我们的 CTN。加州大学默塞德分校数据集由 21 个类别的遥感场景组成,每个类别有 100 个图像。所有图像均为 256 × 256 像素,空间分辨率为 0.3 m/像素。继 [14]、[34]、[71] 之后,我们将数据集分为两部分:一部分用作训练集,另一部分用作测试集。训练集和测试集分别有1050张图像.
2)指标:选择PSNR和SSIM作为图像超分辨率评估指标,所有超分辨率结果都在RGB通道上评估。我们还分析了模型的网络参数(参数)和多重添加操作(M-Adds)的数量。请注意,M-Add的计算对应于256×256 HR图像。
3)实现细节:我们的 CTN 是用 N = 16 个 CTB 和 N-1 = 15 个 CEM 实现的。我们为×2 SR 和×3 SR 使用一个上采样块,为×4 SR 使用两个上采样块。按照[34],×2 SR、×3 SR 和×4 SR 的HR 图像的块大小分别设置为96×96、144×144 和192×192。我们应用水平翻转和随机旋转 90°、180° 和 270° 进行数据扩充。 Adam 优化器用于训练批量大小为 16 的网络。初始学习率设置为 0.0001。该网络总共训练了 2000 个 epoch,学习率将在 400 个 epoch 后减半。所有实验均在单个 NVIDIA RTX 2080 Ti GPU 卡上进行。
4)定量结果:我们的比较方法包括两部分:单图像超分辨率方法(即 SC [64]、SRCNN [65] 和 FSRCNN [66] ])以及遥感图像超分辨率方法(即 LGCNet [67]、DMCN [68]、DCM [14]、DRCA [69] 和 HSENet [34])。比较结果报告在表II中。我们观察到,与其他 RSISR 方法相比,我们的 CTN 实现了更好或相当的性能。表 III 还总结了 UC Merced 数据集上每个类别的 ×3 SR 的 PSNR。我们发现 CTN 在类建筑物和港口方面的性能大大优于 DRCA [69] 和 HSENet [34],这需要足够的局部上下文信息来区分对象和重建图像细节。这些有希望的结果进一步证明了我们方法的有效性。
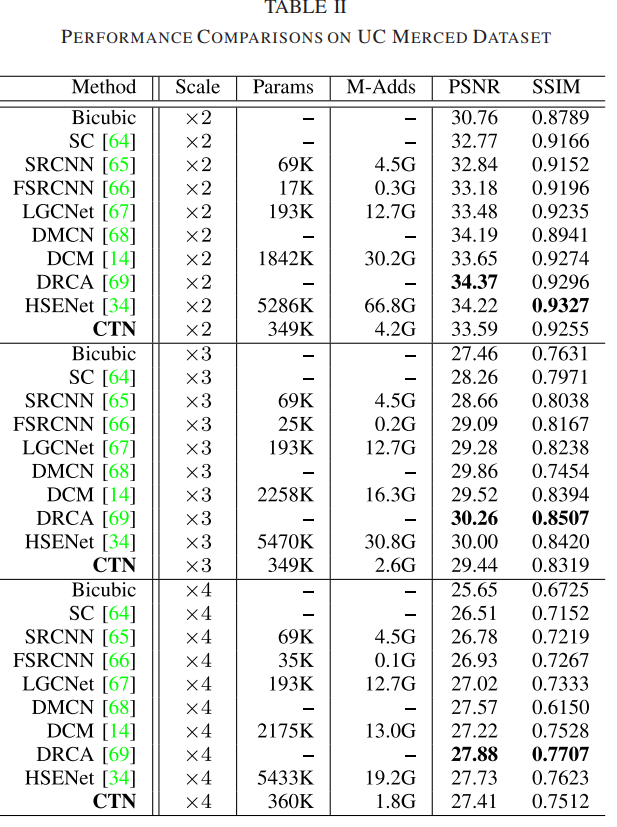
5)定性结果:图 6 显示了 UC Merced 数据集上的×3 和×4 视觉结果。与其他 SR 方法相比,CTN 可以生成具有清晰边缘和轮廓的令人满意的视觉结果,这证明了我们 CTN 的有效性。
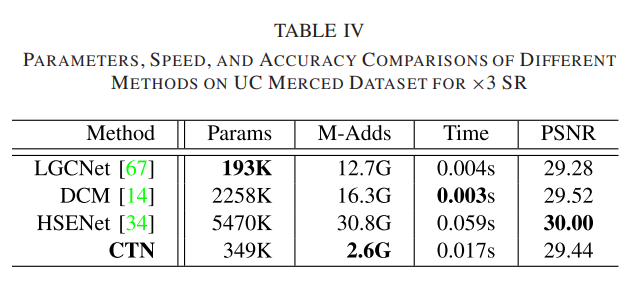
6)推理速度和模型复杂性:我们评估了前馈过程中不同 RSISR 方法的推理速度×3 SR 的 UC Merced 测试集。为了公平比较,不同模型的评估在同一实验平台上进行。详细比较见表四。与其他RSISR方法相比,我们的CTN在计算效率和性能之间实现了权衡。由于CTN主要由卷积层构建,因此我们模型的模型复杂度计算如下:
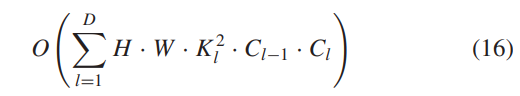
其中 Kl 表示第 l 个卷积层的核大小。第 l 个卷积层的输入和输出通道号分别表示为 Cl−1 和 Cl。D是我们CTN的深度。
B. 附加任务:自然图像超分辨率
1)
C. 附加任务:自然图像去噪
1)
D. 消融研究
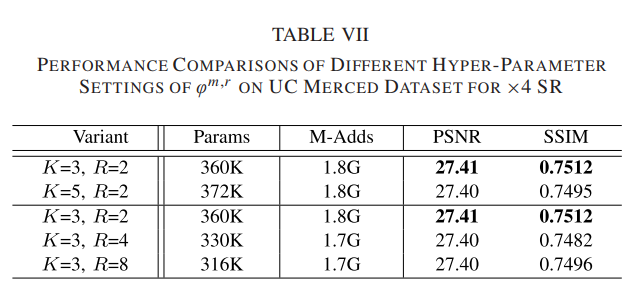
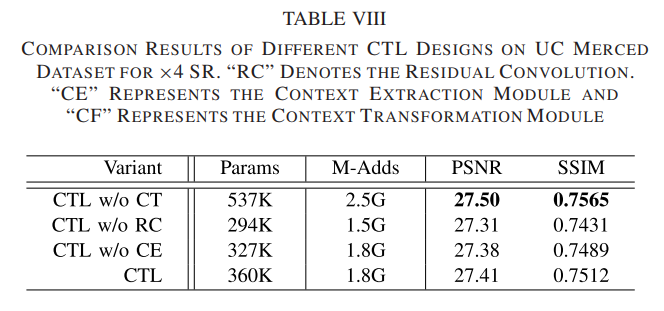
1)上下文转换层的功效:探索CTL中φm,r的超参数设置,即核大小K和通道约简率R。我们首先修复 R = 2 并探索 K 设置。如表七所示,随着K的增加,重建精度降低。原因是CTL中φm,r的核大小较大,增加了深度神经网络的优化难度。因此,我们选择 K = 3 作为 φm,r 的默认核大小。然后,我们探索 R 设置。较大的 R 带来更多的线性变换,以帮助 CTL 生成更多的上下文特征。然而,从表 VII 中,我们观察到重建精度并没有随着 R 的增加而持续提高。这是因为大 R 减少了基本上下文特征 Sn,b 的数量,这影响了线性变换操作生成的特征的多样性。因此,我们选择 R = 2 作为 φm,r 的通道缩减率。然后,我们探索CTL的设计。设计了三个基线模型[即,使用 3×3 卷积层替换上下文转换模块(w/o CT),去除剩余的 1×1 卷积(w/o RC)并使用标准的 1×1 卷积替换上下文提取模块(w/o CE)]。表 VIII 中报告了性能比较。在没有上下文转换模块的情况下,CTN 在 PSNR 方面实现了 0.09-dB 的改进,但新模型的网络参数增加了近 50%,这证明了上下文转换的有效性。在没有残差卷积的情况下,PSNR 值从 27.41 降低到 27.31 dB。不使用上下文提取的 CTL 的性能在 PSNR 和 SSIM 方面也不如 CTL,这进一步证明了局部上下文信息对于 RSISR 的重要性。
- Efficacy of Contextual Transformation Block:我们探索了一个 CTB 中不同数量的 CTL 的性能(如表 IX 所示)和 CTN 中不同数量的 CTB 的性能(如表 X 所示)。
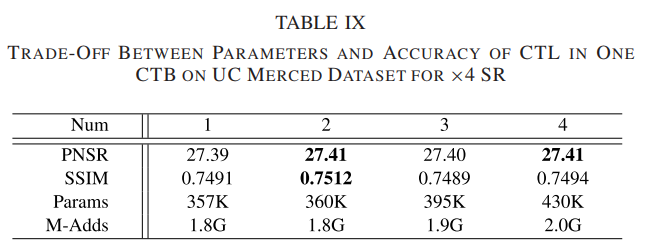
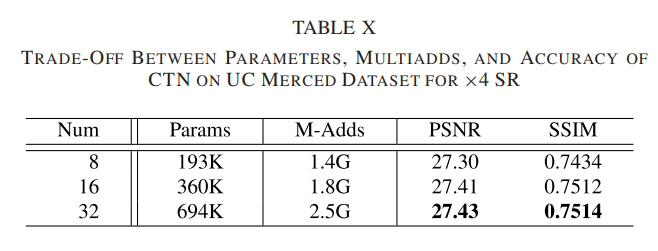
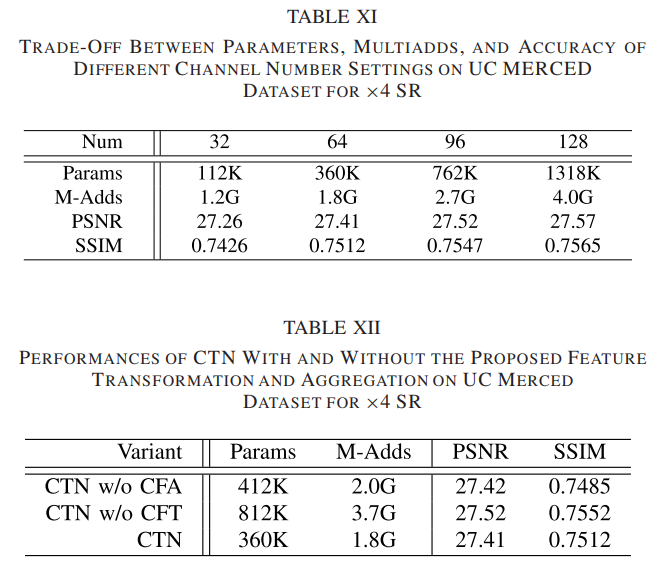
从表 IX 可以看出,随着 CTL 数量的增加,重建精度得到提高,但很快达到饱和。更多的 CTL 不会带来任何性能提升,因为网络很难优化。考虑参数和精度之间的权衡,我们使用两个 CTL 来构建 CTB。然后,我们分析了 CTN 中 CTB 的不同数量设置的影响,结果报告在表 X 中。我们观察到更多的 CTB 带来了性能改进,但计算成本也在急剧增加。因此,CTN 是用 N = 16 个 CTB 实现的。最后,我们报告了不同通道数设置的性能,如表 XI 所示。我们观察到随着通道数的增加,重建精度也提高了。然而,参数急剧增加,这偏离了我们的目标。因此,我们将特征的通道数设置为 64.3) 特征转换和聚合的影响:我们设计了两个模型变体来探索特征转换和聚合的影响。第一个变体(w/o CFA)移除分组卷积并直接使用连接操作来聚合不同的上下文特征。对于第二个变体(w/o CFT)将设计的 CTL 替换为 3×3 卷积。表 XII 中列出了性能比较。具体来说,PSNR 值在不使用上下文特征聚合的情况下有微小变化,但网络参数从 360 增加到 412 K,这证明了所提出的特征聚合方法的有效性。未使用上下文特征变换的模型参数比CTN大两倍,但重建精度没有获得显着提高,证明了所提特征变换方法的有效性。
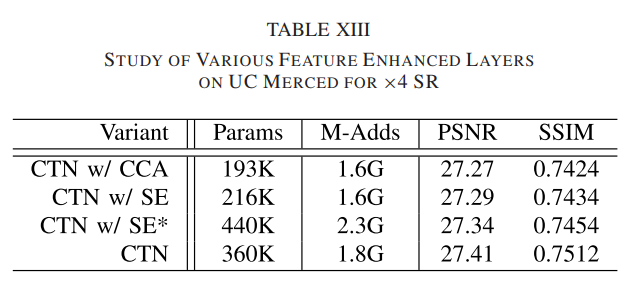
- 上下文增强模块的功效:表 XIII 报告了消融结果,包括对比感知通道注意层 [21](带 CCA)和挤压和激发层 [84](带 SE)。尽管对比度感知通道注意力层在自然图像超分辨率上表现良好,但我们发现使用它的 CTN 实现了最低的重建精度。原因可能是对比感知通道注意层中的全局对比操作没有充分利用上下文信息。使用挤压和激励层的 CTN 比使用对比感知通道注意层的 CTN 表现更好,但在 PSNR 和 SSIM 方面不如 CTN。为了证明性能提升不是由网络参数的增加引起的,我们构造一个名为 CTN w/ SE* 的模型变体,它将 CTN w/ SE 的通道数从 64 更改为 96。参数从 216 增加到 440 K。但是,性能也不如 CTN(27.34 dB 对 27.41 dB),并且网络参数大于 CTN(440 K 对 360 K)。虽然用于CTN 的CEM 增加了一些multiads 操作,但与其他变体相比,CTN 的完整实现实现了最好的图像重建精度。
结论
在这项工作中,我们提出了一种新模型,称为 CTN,用于轻量级 RSISR。我们引入了一个新的特征提取块来使用 CTL 学习丰富的上下文特征,它以轻量级的方式提取和丰富上下文特征表示。提取的上下文特征由 CEM 和上下文特征聚合模块进一步处理以产生更全面的表示,这些表示随后被送入上采样和重建模块以生成 HR。我们在 UC Merced 数据集上将 CTN 与其他最先进的方法进行了比较。实验结果表明,CTN 取得了优于其他竞争者的性能。得益于CTL高效特征学习的有效性,CTN在自然图像超分辨率和自然图像去噪方面均表现出色,进一步证明了我们模型的优越性。

















 1877
1877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









