






 本文深入讲解HTTP协议,包括如何防止JS获取Cookie、CDN的工作原理、常见网络攻击防范、HTTP请求方法、GET与POST的区别、fetch API使用、HTTP2.0新特性以及HTTP各版本对比。涵盖HTTP安全、性能优化、请求响应流程等多个方面。
本文深入讲解HTTP协议,包括如何防止JS获取Cookie、CDN的工作原理、常见网络攻击防范、HTTP请求方法、GET与POST的区别、fetch API使用、HTTP2.0新特性以及HTTP各版本对比。涵盖HTTP安全、性能优化、请求响应流程等多个方面。
一、如何让js拿不到cookie?
设置方法为: HttpOnly. 没错, 这是一个没有值的属性, 只要在 Set-Cookie里面附带了这个属性, 那么这个cookie就不能被js脚本所获取。
二、cdn的作用和原理
1、CDN 内容分发网络
- 概况:设置多个节点服务器,分布在不同区域中,便于用户进行数据传递和访问。当某一个节点出现问题时,通过其他节点仍然可以完成数据传输工作,可以提高用户访问网站的响应速度。
- “分布式存储”:将中心平台的内容分发到各地的边缘服务器,使用户能够就近获取所需内容,降低网络用时,提高用户访问响应速度和命中率。利用了索引、缓存等技术。
- “负载均衡”:对所有发送的请求进行访问调度,确定提供给用户的最终实际访问地址。
- “内容管理”:负责对存储内容的监管、数据分析等。为什么要用CDN?
浏览器从服务器上下载CSS、js和图片等文件时都要和服务器连接,而大部分服务器的带宽有限,如果超过限制,网页就半天反应不过来。而CDN可以通过不同的域名来加载文件,从而使下载文件的并发连接数大大增加。
2、为什么要用CDN?
-
jquery一类的库文件被广泛使用,如果访问你网站的用户的浏览器之前在访问别的网站时通过和你相同的CDN已经加载了jquery,由于该文件已经被缓存了,就不用重新下载了。
-
CDN具有更好的可用性,更低的网络延迟和丢包率。
-
CDN能提供本地的数据中心,这样一来,那些远离你网站主服务器的用户也能就近很快地下载文件。
-
很多商业付费的CDN能提供使用报告,这可以作为你自己网站分析报告的补充。
-
CDN能够分配负载,节省带宽,提高你网站的性能,降低网站托管的成本,通常是免费的。
三、cookie中httpOnly什么意思?
cookie中设置了HttpOnly属性,那么通过js脚本将无法读取到cookie信息,这样能有效的防止XSS攻击,窃取cookie内容,这样就增加了cookie的安全性。
HttpOnly的设置样例:
response.setHeader("Set-Cookie", "cookiename=value;Path=/;
Domain=domainvalue;Max-Age=seconds;HTTPOnly");
四、常见的网络攻击
1、xss跨站脚本攻击
XSS攻击全称Cross Site Script (跨站脚本攻击),其原理是攻击者向有XSS漏洞的网站中输入恶意的 HTML 代码,当用户浏览该网站时,这段 HTML 代码会自动执行,从而达到攻击的目的。
- xss攻击可以分成如下两种类型:
1、非持久型xss攻击:顾名思义,非持久型xss攻击是一次性的,仅对当次的页面访问产生影响。非持久型xss攻击要求用户访问一个被攻击者篡改后的链接,用户访问该链接时,被植入的攻击脚本被用户游览器执行,从而达到攻击目的。
2、持久型xss攻击:持久型xss,会把攻击者的数据存储在服务器端,攻击行为将伴随着攻击数据一直存在。
- 也可以分成如下三类:
反射型:经过后端,不经过数据库。
存储型:经过后端,经过数据库。
DOM:不经过后端,DOM- xss是通过url传入参数去控制触发的。
- 解决办法
1、 一种方法是在表单提交或者url参数传递前,对需要的参数进行过滤。
2、 过滤用户输入的 检查用户输入的内容中是否有非法内容。如<>(尖括号)、”(引号)、 ‘(单引号)、%(百分比符号)、;(分号)、()(括号)、&(& 符号)、+(加号)等。、严格控制输出。
3、 cookie设置httpOnly。
4、 对所有要动态输出到页面的内容,通通进行相关的编码和转义。
2、sql注入攻击
通过sql命令伪装成正常的http请求参数,传递到服务器端,服务器执行sql命令造成对数据库进行攻击。例如把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。
3、 csrf跨站伪造请求攻击:其实就是攻击者盗用了你的身份,以你的名义发送恶意请求。
具体方案:1、验证referer字段,这个字段主要是反映了访问某个网页只能有referer发起请求,所以通过referer验证,可以抵御一部分csrf攻击。2、在请求地址中加token验证,攻击者发送恶意请求时,通过token验证来进行身份验证,而token必须是一个攻击者猜不到的,很难去模拟出来的,具体来说可以放在表单的hidden字段中。3、在htttp请求头中定义字段,其实就是将2中说得token字段放入请求头,解决了每次在请求头中加入token的不便,同时在其也不会记录在地址栏里,降低了token泄露的风险。。。。
五、http请求方法
HTTP1.0 定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP1.1 新增了六种请求方法:OPTIONS、PUT、PATCH、DELETE、TRACE 和 CONNECT 方法。
| 序号 | 方法 | 解释 |
|---|---|---|
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
| 9 | PATCH | 是对 PUT 方法的补充,用来对已知资源进行局部更新 。 |
六、get与post区别
GET 用于获取信息,是无副作用的,是幂等的,且可缓存; POST 用于修改服务器上的数据,有副作用,非幂等,不可缓存。
GET和POST 的区别详细解说
-
GET 和 POST 只是 HTTP 协议中两种请求方式(异曲同工),而 HTTP 协议是基于 TCP/IP 的应用层协议,无论 GET 还是 POST,用的都是同一个传输层协议,所以在传输上,没有区别。
-
报文格式上,不带参数时,最大区别就是第一行方法名不同, 仅仅是报文的几个字符不同而已。
-
POST 方法请求报文第一行是这样的 POST /url HTTP/1.1 GET 方法请求报文第一行是这样的 GET /url HTTP/1.1。
-
带参数时报文的区别呢? 在约定中,GET 方法的参数应该放在 url 中,POST 方法参数应该放在 body 中。
-
HTTP 协议没有 Body 和 URL 的长度限制,对 URL 限制的大多是浏览器和服务器的原因。浏览器原因就不说了,服务器是因为处理长 URL 要消耗比较多的资源,为了性能和安全(防止恶意构造长 URL 来攻击)考虑,会给 URL 长度加限制。
-
从传输的角度来说,他们都是不安全的,因为 HTTP 在网络上是明文传输的,只要在网络节点上捉包,就能完整地获取数据报文。要想安全传输,就只有加密,也就是 HTTPS。
-
POST 方法会产生两个 TCP 数据包?
有些文章中提到,post 会将 header 和 body 分开发送,先发送 header,服务端返回 100 状态码再发送 body。HTTP 协议中没有明确说明 POST 会产生两个 TCP 数据包,而且实际测试(Chrome)发现,header 和 body 不会分开发送。所以,header 和 body 分开发送是部分浏览器或框架的请求方法,不属于 post 必然行为。
七、fetch详解
1. 使用Fetch获取数据很容易
fetch('https://api.github.com/users/chriscoyier/repos');
Fetch会返回Promise,所以在获取资源后,可以使用.then方法做你想做的。
fetch('https://api.github.com/users/chriscoyier/repos')
.then(response => {/* do something */})
//如果console.log(response),会得到下列内容
{
body: ReadableStream
bodyUsed: false
headers: Headers
ok : true
redirected : false
status : 200
statusText : "OK"
type : "cors"
url : "http://some-website.com/some-url"
__proto__ : Response
}
解释:
-
我们从GitHub请求的资源都存储在body中,作为一种可读的流。所以需要调用一个恰当方法将可读流转换为我们可以使用的数据。
-
Github返回的响应是JSON格式的,所以调用response.json方法来转换数据。
-
还有其他方法来处理不同类型的响应。如果请求一个XML格式文件,则调用response.text。如果请求图片,使用response.blob方法。
-
所有这些方法(response.json等等)返回另一个Promise,所以可以调用.then方法处理我们转换后的数据。
fetch('https://api.github.com/users/chriscoyier/repos')
.then(response => response.json())
.then(data => {
// data就是我们请求的repos
console.log(data)
})
2. 使用fetch发送数据
fetch('some-url', options);
第一个参数是设置请求方法(如post、put或del),Fetch会自动设置方法为get。
第二个参数是设置头部。因为一般使用JSON数据格式,所以设置ContentType为application/json。
第三个参数是设置包含JSON内容的主体。因为JSON内容是必须的,所以当设置主体时会调用JSON.stringify。
实践中,post请求会像下面这样:
let content = {some: 'content'};
// The actual fetch request
fetch('some-url', {
method: 'post',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify(content)
})
3. fetch处理异常
1、用catch方法
fetch('https://api.github.com/users/chrissycoyier/repos')
.then(response => response.json())
.then(data => console.log('data is', data))
.catch(error => console.log('error is', error))
//如果console.log此次响应,会看出不同:
{
body: ReadableStream
bodyUsed: true
headers: Headers
ok: false // Response is not ok
redirected: false
status: 404 // HTTP status is 404.
statusText: "Not Found" // Request not found
type: "cors"
url: "https://api.github.com/users/chrissycoyier/repos"
}
4、对fetch进一步封装
上面响应告诉我们Fetch不会关心AJAX是否成功,他只关心从服务器发送请求和接收响应,如果响应失败我们需要抛出异常。因此,初始的then方法需要被重写,比如响应成功会调用response.json,最简单方法是检查response是否为ok。
fetch('some-url')
.then(response => {
if (response.ok) {
return response.json()
} else {
// Find some way to get to execute .catch()
}
})
一旦我们知道请求是不成功的,我可以throw异常或rejectPromise来调用catch。
// throwing an Error
else {
throw new Error('something went wrong!')
}
// rejecting a Promise
else {
return Promise.reject('something went wrong!')
这里选择Promise.reject,是因为容易扩展。抛出异常方法也不错,但是无法扩展,唯一益处在于便于栈跟踪。
所以,到现在代码应该是这样的:
fetch('https://api.github.com/users/chrissycoyier/repos')
.then(response => {
if (response.ok) {
return response.json()
} else {
return Promise.reject('something went wrong!')
}
})
.then(data => console.log('data is', data))
.catch(error => console.log('error is', error));
在这个例子中,我们知道资源是不存在。所以我们可以返回404状态或Not Found原因短语,然而我们就知道如何处理。
为了在.catch中获取status或statusText,我们可以reject一个JavaScript对象:
fetch('some-url')
.then(response => {
if (response.ok) {
return response.json()
} else {
return Promise.reject({
status: response.status,
statusText: response.statusText
})
}
})
.catch(error => {
if (error.status === 404) {
// do something about 404
}
})
5、fetch设置超时时间
其实为fetch添加超时时间很简单,需要用到Promise.race()方法,该方法Promise.race() 将多个Promise包装成一个新的Promise实例。新的promise状态的取决于最先改变的那个promise的状态,那个率先改变的Promise实例返回值就传递给p的回调函数。
var p = Promise.race([p1,p2,p3]);
Promise.race方法的参数如果不是Promise实例,就会先先调用Promise.resolve方法,将参数转为Promise实例,再进一步处理。
实例代码:
Promise.race([
fetch(URL),
new Promise(function(resolve,reject){
setTimeout(()=> reject(new Error('request timeout')),2000)
})])
.then((data)=>{
//请求成功
}).catch(()=>{
//请求失败
});
解释:
代码中用Promise.race()将fetch和一个新的Promise包装在了一起,新的Promise和fetch谁率先返回就把该Promise实例返回值传递给下面的.then()或者是.catch()。
代码里我们新建的Promise实例里设置了超时时间2000毫秒,如果超过2000毫秒fetch的请求还没有结束,这时已经达到了新的Promise的超时时间,就会返回请求失败,从而触发catch方法里指定的回调函数。
八、http2.0新特性
1. 二进制分帧
HTTP 2.0在应用层跟传送层之间增加了一个二进制分帧层,从而能够达到在不改动HTTP的语义,HTTP方法,状态码,URI以及首部字段的情况下,突破HTTP 1.1的性能限制,改进传输性能,实现低延迟和高吞吐量。
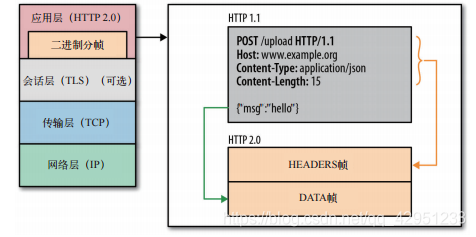
如上图,在二进制分帧层上,HTTP 2.0会将所有传输的信息分割为更小的消息和帧,并对它们采用二进制格式的编码,其中HTTP 1.1的首部信息会被封装到Headers帧,而request body被封装到图中所示的DATA帧。相当于把部分数据塞进了二进制分帧层里,改进传输性能。
2. 多路复用(MultiPlexing)
即连接共享,即每一个request都是是用作连接共享机制的。一个request对应一个id,这样一个连接上可以有多个request,每个连接的request可以随机的混杂在一起,接收方可以根据request的 id将request再归属到各自不同的服务端请求里面。
HTTP2.0多路复用有多好?
HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。
HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。
3. header压缩
HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
假定一个页面有100个资源需要加载(这个数量对于今天的Web而言还是挺保守的), 而每一次请求都有1kb的消息头(这同样也并不少见,因为Cookie和引用等东西的存在), 则至少需要多消耗100kb来获取这些消息头。HTTP2.0可以维护一个字典,差量更新HTTP头部,大大降低因头部传输产生的流量。具体参考:HTTP/2 头部压缩技术介绍
4. 服务端推送(server push)
HTTP2.0也具有server push功能。服务端推送能把客户端所需要的资源伴随着index.html一起发送到客户端,省去了客户端重复请求的步骤。正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。
九、http1.0、http1.1、http2.0的区别
1、HTTP1.0和HTTP1.1的一些区别
-
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
-
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
-
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
-
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
2、HTTP2.0的多路复用和HTTP1.X中的长连接复用有什么区别?
-
HTTP/1.0 一次请求-响应,建立一个连接,用完关闭;每一个请求都要建立一个连接;
-
HTTP/1.1 Pipeling解决方式为,若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞;
-
HTTP/2多个请求可同时在一个连接上并行执行。某个请求任务耗时严重,不会影响到其它连接的正常执行。
3、HTTPS与HTTP的一些区别
-
HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
-
HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
-
HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
-
HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。

















 165
165

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









