







 本文介绍了Python的sys、time、datatime、random、hashlib等标准库的使用,包括模块搜索路径、传参、时间处理、随机数生成、加密等功能。还讲解了第三方模块的安装方法,以及正则表达式的定义、作用、特点和常用元字符,最后介绍了Python re模块的使用和量词的应用。
本文介绍了Python的sys、time、datatime、random、hashlib等标准库的使用,包括模块搜索路径、传参、时间处理、随机数生成、加密等功能。还讲解了第三方模块的安装方法,以及正则表达式的定义、作用、特点和常用元字符,最后介绍了Python re模块的使用和量词的应用。
sys模块
搜索路径
当你导入一个模块,Python解析器对模块位置的搜索顺序是:
1、当前目录
2.如果不在当前目录,Python则搜索在shell变量PYTHONPATH下的每个目录
3.如果都找不到,Python会察看默认路径。UNIX下,默认路径一般为/user/local/lib.python
模块搜索路径存储在system模块的sys.path变量中。变量里包含当前目录,PYTHONPATH和由安装过程决定的默认目录
import sys
print(sys.path)
print(sys.version)
print(sys.argv)
'''
['E:\\...\\pythom code\\second\\user', 'E:...\\second', 'E:...\\second\\article', 'D:\\software\\Python39\\python39.zip', 'D...\\Python39\\DLLs','D:...\\Python39\\lib', 'D:\\software\\Python39', 'D:\\software\\Python39\\lib\\site-packages']
3.9.2 (tags/v3.9.2:, Feb 19 2021, 13:44:55)
['E:/.../pythom code/second/user/sousuolujing1.py', '100']
'''sys.path:系统会在哪些目录下搜索你要加载的模块
右键article包,点击Mark Directory As,点击Sources Root,就可以把article包作为搜索路径
argv用于传参
点击下三角,点击Edit Configurations,点击Parameters就可以传参,设置了100后就显示上一段代码的结果
time模块
时间戳
重点:
time() sleep() strftime('格式') %Y%m%d...
import time
#执行代码的间隔
t=time.time()
print(t)
time.sleep(1)
t1=time.time()
print(t1)
#将时间戳转换为字符串
s=time.ctime(t)
print(s)
#将时间戳转换为元组
t=time.localtime(t)
print(t)
print(t.tm_mday)
#将元组转为时间戳
tt=time.mktime(t)
print(tt)
#将元组的时间转换成字符串
s=time.strftime('%Y-%m-%d %H:%M:%S')#默认取当前时间
print(s)
#将字符串转成元组的方式
r=time.strptime('2021/06/05','%Y/%m/%d')
print(r)
'''
1622885309.5279844
1622885310.5310378
Sat Jun 5 17:28:29 2021
time.struct_time(tm_year=2021, tm_mon=6, tm_mday=5, tm_hour=17, tm_min=28, tm_sec=29, tm_wday=5, tm_yday=156, tm_isdst=0)
5
1622885309.0
2021-06-05 17:28:30
time.struct_time(tm_year=2021, tm_mon=6, tm_mday=5, tm_hour=0, tm_min=0,
tm_sec=0, tm_wday=5, tm_yday=156, tm_isdst=-1)
'''datatime模块 time模块升级版
tip:ctrl+f进行搜索 api文档
import datetime
import time
print(datetime.time.hour)#返回值是对象
print(time.localtime().tm_hour)
print(datetime.date.day)
d=datetime.date(2019,6,6)
print(datetime.date.ctime(d))
#datatime timedata
print(datetime.date.today())
#时间差
timedel=datetime.timedelta(hours=2)
print(timedel)
now=datetime.datetime.now()#得到当前的日期和时间
print(now)
result=now-timedel
print(result)
#缓存:数据redis 作为缓存
#redis.set(key,value,时间差) 会话:session
timedel1=datetime.timedelta(weeks=2)
result=now+timedel1
print(result)
'''
<attribute 'hour' of 'datetime.time' objects>
20
<attribute 'day' of 'datetime.date' objects>
Thu Jun 6 00:00:00 2019
2021-06-06
2:00:00
2021-06-06 20:39:11.540730
2021-06-06 18:39:11.540730
2021-06-20 20:39:11.540730
'''random模块
randrange(self, start, stop=None, step=1)
Choose a random item from range(start, stop[, step]).
randint(self, a, b)
Return random integer in range [a, b], including both end points.
import random
ran=random.random()#0~1之间的随机小数
print(ran)
#Choose a random element from a non-empty sequence.
list1=['zhangsan','lisi','wangwu','zhaoliu']
ran=random.choice(list1)
print(ran)
#Shuffle list x in place, and return None.
pai=['红桃A','方块K','梅花2','JOKER']
result=random.shuffle(pai)
print(pai)
#验证码 大小写字母和数字的组合
def func():
code=''
for i in range(4):
ran1=str(random.randint(0,9))
ran2=chr(random.randint(65,90))
ran3=chr(random.randint(97,122))
r=random.choice([ran1,ran2,ran3])
code+=r
return code
code=func()
print(code)
'''
0.4278058256078079
wangwu
['JOKER', '红桃A', '方块K', '梅花2']
tjG5
'''标准库函数例chr() ord()
print(chr(65))#Unicode码--->str
print(ord('A'))#str--->Unicode码
print(ord('下'))
print(chr(19979))
'''
A
65
19979
下
'''hashlib模块 用于加密
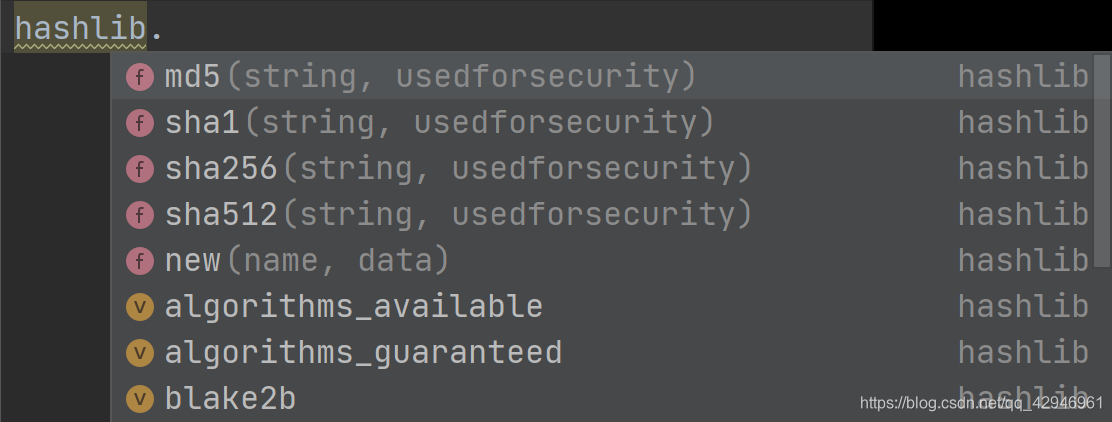 等加密算法
等加密算法
#加密算法
import hashlib
msg='机密'
#md5=hashlib.md5(msg) TypeError: Unicode-objects must be encoded before hashing
md5=hashlib.md5(msg.encode('utf-8'))
#不能直接送字符串,先编码
#单向加密,解不开
print(md5.hexdigest()) #hex:十六进制
sha_256=hashlib.sha256(msg.encode('utf-8'))
print(sha_256.hexdigest())
'''
b170d22754ccfe59ec50b3c4a30942d8
3fcc476715c11fd7bb3d8c449e74944fd025fb1c0bd8c9af9b910f23677efb4d
'''md5、sha256是单向的,解不开;base64双向可逆
数据库里的账号密码都是加密后的,用户输的密码加密后和数据库的比对
import hashlib
password='123456'
list1=[]
sha256=hashlib.sha256(password.encode('utf-8'))
list1.append(sha256.hexdigest())
pwd=input('输入密码:')
sha256=hashlib.sha256(pwd.encode('utf-8'))
pwd=sha256.hexdigest()
print(pwd)
print(list1)
for i in list1:
if pwd==i:
print('登录成功')
'''
输入密码:123456
8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
['8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92']
登录成功
'''第三方模块
 打开终端进行安装
打开终端进行安装
settings--->project interpreter--->+号 也可以下载
import requests
response=requests.get('https://www.baidu.com/')#响应
#获取源代码
print(response.text)
'''
<!--STATUS OK--><html> <head><meta http-equiv=content-type content...
'''正则表达式
1.正则表达式的定义
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则宇符串”,这个“规则宇符串”用来表达对字符串的一种过滤逻辑
正则表达式是对字符串(包括普通字符(例如,a到z之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则宇符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串
正则表达式,又称正规表示式、正规表示法、正规表达式、规则表达式、常规表示法(英语:Regular Expression,在代码中常简写为regex、regexp或RE)。Regular Expression的“Regular”一般被译为“正则”、“正规”、“常规”。此处的“Regular”即是“规则”、“规律”的意思
正则在所有语言中都有的内容。
2.正则表达式的作用和特点
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
1.给定的字符串是否符合正则表达式的过滤逻辑(称作“匹配”);
2.可以通过正则表达式,从字符串中获取我们想要的特定部分。
正则表达式的特点是:
1.灵活性、逻辑性和功能性非常强
2.可以迅速地用极简单的方式达到字符串的复杂控制
3.对于刚接触的人来说,比较晦涩难懂
场景:
如何判断一个字符串是手机号呢?
判断邮箱为163或者126的所有邮件地址
假如你在写一个爬虫,你得到了一个网页的HTML源码。其中有一段
<html><body><h1>hello worldh1</body></html>
你想要把这个hello world提取出来,但你这时如果只会python的字符串处理,那么第一反应可能是
s = "<htm1><body><h1>hello world</h1></body></html>
start_index = s.find('<h1>')
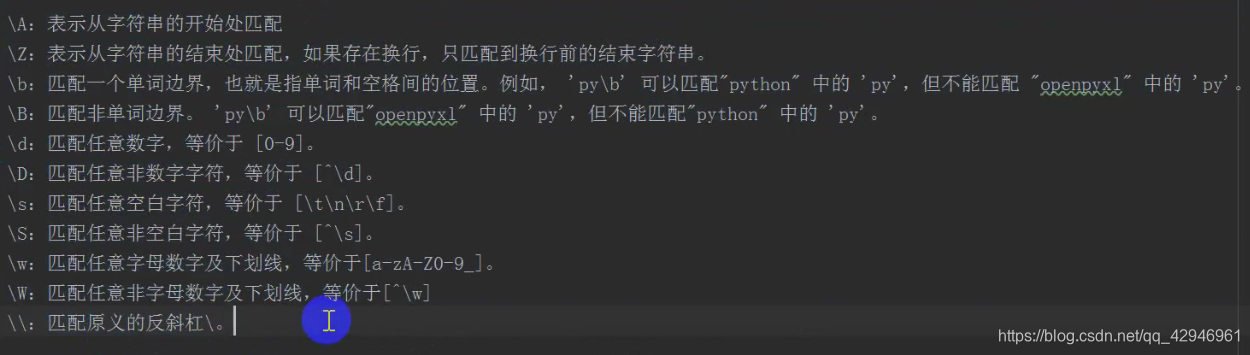
\A:表示从字符串的开始处匹配
\Z:表示从字符串的结束处匹配,如果存在换行,只匹配到换行前的结束字符串。
(b:匹配一个单词边界,也就是指单词和空格间的位置。例如, 'prlb’可以匹配"python”中的'py',但不能匹配“genox!”中的'py'.\B:匹配非单词边界。'pylb’可以匹配"openpyxl”中的‘py',但不能匹配"python”中的 'py'。
\d:匹配任意数字,等价于[0-9]。
\D:匹配任意非数字字符,等价于[\d]。
\s:匹配任意空白字符,等价于[ltinlr\f。
\S:匹配任意非空白字符,等价于[Ns]。
\w:匹配任意字母数字及下划线,等价于[a-zA-Z0-9_]。
\W:匹配任意非字母数字及下划线,等价于[^\w]
python re模块
正则验证的是字符串
import re
msg='张三李四王五赵六'
#过滤
pattern=re.compile('赵六')
result=pattern.match(msg)#从头开始匹配,不匹配返回none
print(result)
#正真的正则
#使用正则re模块方法:match
s='张三李四王五赵六'
result=re.match('张三',s)#封装了上面的内容
print(result)
result=re.search('赵六',s)
#search进行正则字符串匹配方法,匹配整个字符串
print(result)
#span:匹配的位置
print(result.span())
#使用group提取匹配的内容
print(result.group())
print(result.groups())
'''
None
<re.Match object; span=(0, 2), match='张三'>
<re.Match object; span=(6, 8), match='赵六'>
(6, 8)
赵六
()
'''
import re
#[]表示一个范围
s='哈哈2a'
result=re.search('[0-9][a-z]',s)
print(result)
s='哈哈22'
result=re.search('[0-9][a-z]',s)
print(result)
#a2b h6k 前后是字母,中间是数字,如何提取?
msg='abd7fda8fs3bj8bs'
#找到一个匹配的就结束检索
result=re.search('[a-z][0-9][a-z]',msg)
print(result.group())
#匹配整个字符串
result=re.findall('[a-z][0-9][a-z]',msg)
print(result)
#a2a a33a a444a
msg='a7aby88vgygv999hhu'
result=re.findall('[a-z][0-9]+[a-z]',msg)
print(result)
# +号针对[0-9],≥1
'''
<re.Match object; span=(2, 4), match='2a'>
None
d7f
['d7f', 'a8f', 's3b', 'j8b']
['a7a', 'y88v', 'v999h']
''''{m}'用于验证将前面的模式匹配m次
'{m,}'用于验证将前面的模式匹配m次或者多次 >=m
'{m,n}'用于验证将前面的模式匹配大于等于m次并且小于等于n次
import re
#qq号码验证,5~11位,不能以0开头
qq='65'
result=re.match('[1-9][0-9]+',qq)
print(result)
#不对,只有两位但匹配了
qq='64345'
result=re.match('^[1-9][0-9]{4}$',qq)#固定了位数,5位
#加了开头和结尾,即整体进行匹配
print(result)
qq='6432454328545'
result=re.match('^[1-9][0-9]{4,10}$',qq)
print(result)
'''
<re.Match object; span=(0, 2), match='65'>
<re.Match object; span=(0, 5), match='64345'>
None
'''练习:用户名可以是字母或者数字,不能是数字开头,用户名长度必须6位以上 [0-9a-zA-Z]
import re
username='001admin'
result=re.match('[a-zA-Z][0-9a-zA-Z]{5,}',username)
print(result)
username='admin001'
result=re.match('[a-zA-Z]\w{5,}',username)
print(result)
username='admin001#'
result=re.match('[a-zA-Z]\w{5,}',username)
print(result)
username='admin001#$'
result=re.match('[a-zA-Z]\w{5,}$',username)
print(result)
msg='aa*py ab.txt bb.py kpyk.png'
#result=re.findall('py\b',msg) 字符串中\b会转义
result=re.findall(r'\w+.py\b',msg)
# . :任意字符
print(result)
result=re.findall(r'\w*\.py\b',msg)
#用原生的.
print(result)
'''
None
<re.Match object; span=(0, 8), match='admin001'>
<re.Match object; span=(0, 8), match='admin001'>
None
['aa*py', 'bb.py']
['bb.py']
'''量词
* >=0
+ >=1
? 0,1
import re
#分组
#匹配数字0-100数字
n='50'
result=re.match('[1-9]?\d',n)
print(result)
n='09'
result=re.match('[1-9]?\d',n) # ?:可以有可以没有
print(result)
n='100'
result=re.match(r'[1-9]?\d?$|100$',n)
# |:或者
print(result)
#验证输入的邮箱 163 126 qq
email='64832733@qq.com'
result=re.match(r'\w{5,20}@(163|126|qq)\.(com|cn)',email)
#(word|word|...)或者是整体一个单词 [abc]表示一个字母而不是一个单词
print(result)
email='64832733@q1q.com'
result=re.match(r'\w{5,20}@(163|126|qq)\.(com|cn)$',email)
print(result)
'''
<re.Match object; span=(0, 2), match='50'>
<re.Match object; span=(0, 1), match='0'>
<re.Match object; span=(0, 3), match='100'>
<re.Match object; span=(0, 15), match='64832733@qq.com'>
None
'''


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









