






实验目的:
掌握flink的安装与运行
实验内容:
1. 安装虚拟机,虚拟机上安装操作系统(LINUX)
2. 安装flink
3. 运行flink自带案例浏览器访问http://localhost:8081查看节点情况
实验要求:
(1)登录实训平台,或自己安装虚拟机,安装flink
(2)运行flink/example 的批处理示例WordCount 或者其他
(3)安装netcat,执行nc -l 9000,类似linux的nc -l 9000命令,连接主机的9000端口;
(4)运行flink/example 的流处理示例SocketWindowsWordCount
(5) dashboard显示新增的job;
(6) 执行ncat -l 9000命令的窗口,输入一些字符,并查看统计的结果;
P.s:
若自己安装虚拟机,则Flink的运行需要得到Java环境的支持,在安装Flink之前,请先参照相关资料安装Java环境(比如Java8),再到Flink官网下载安装包,并保存在Linux系统中(例:使用hadoop用户名登录了Linux系统,并且安装文件被保存到了“/home/hadoop/Downloads”目录下)。
实验过程
1.登录实训平台。
2.运行flink/example 的批处理示例WordCount 或者其他
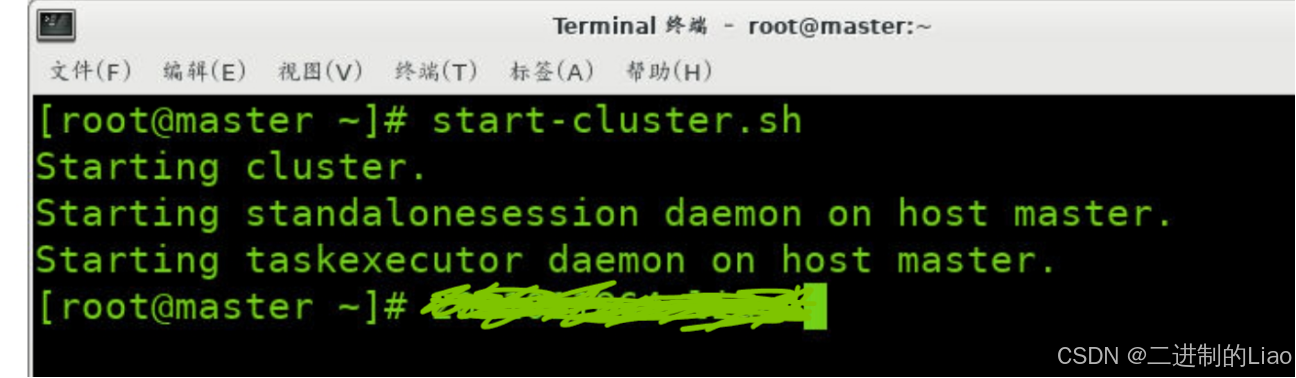
start-cluster.sh运行结果:
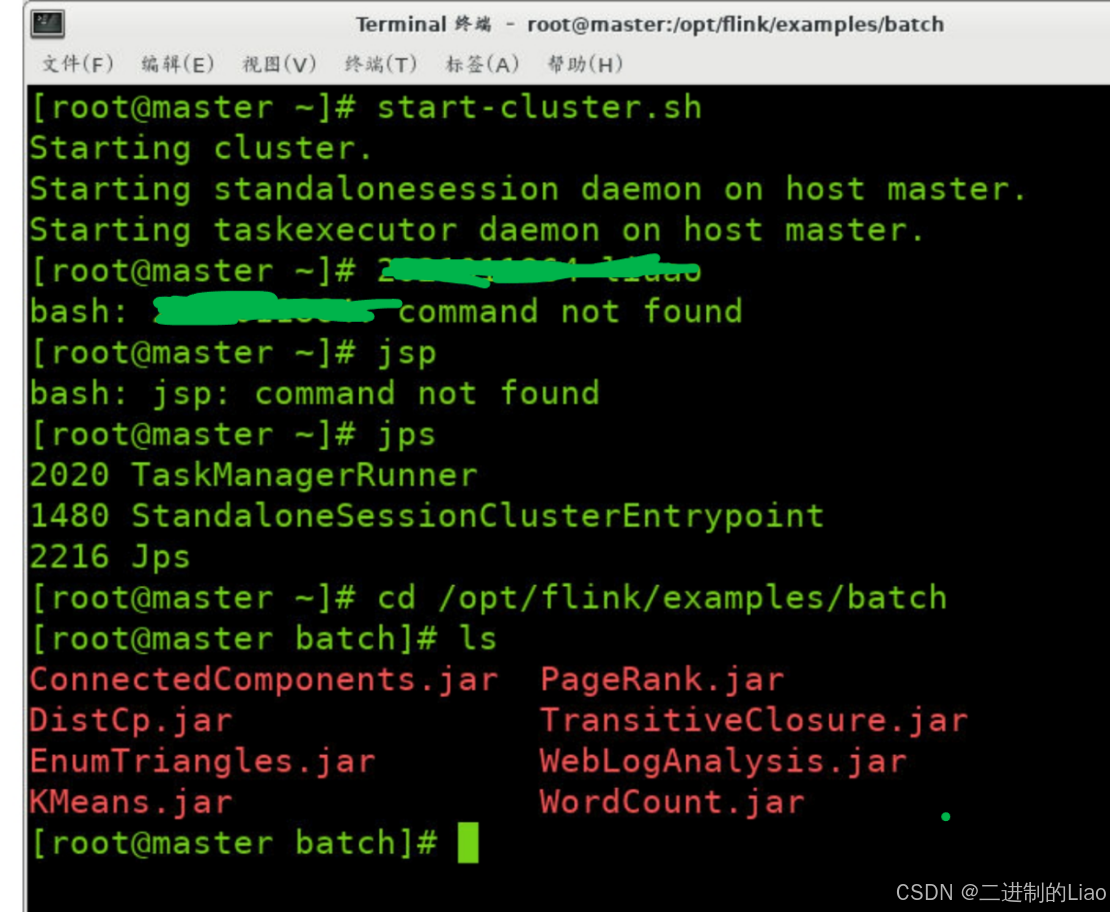
jps
cd /opt/flink/examples/batch
ls运行结果:
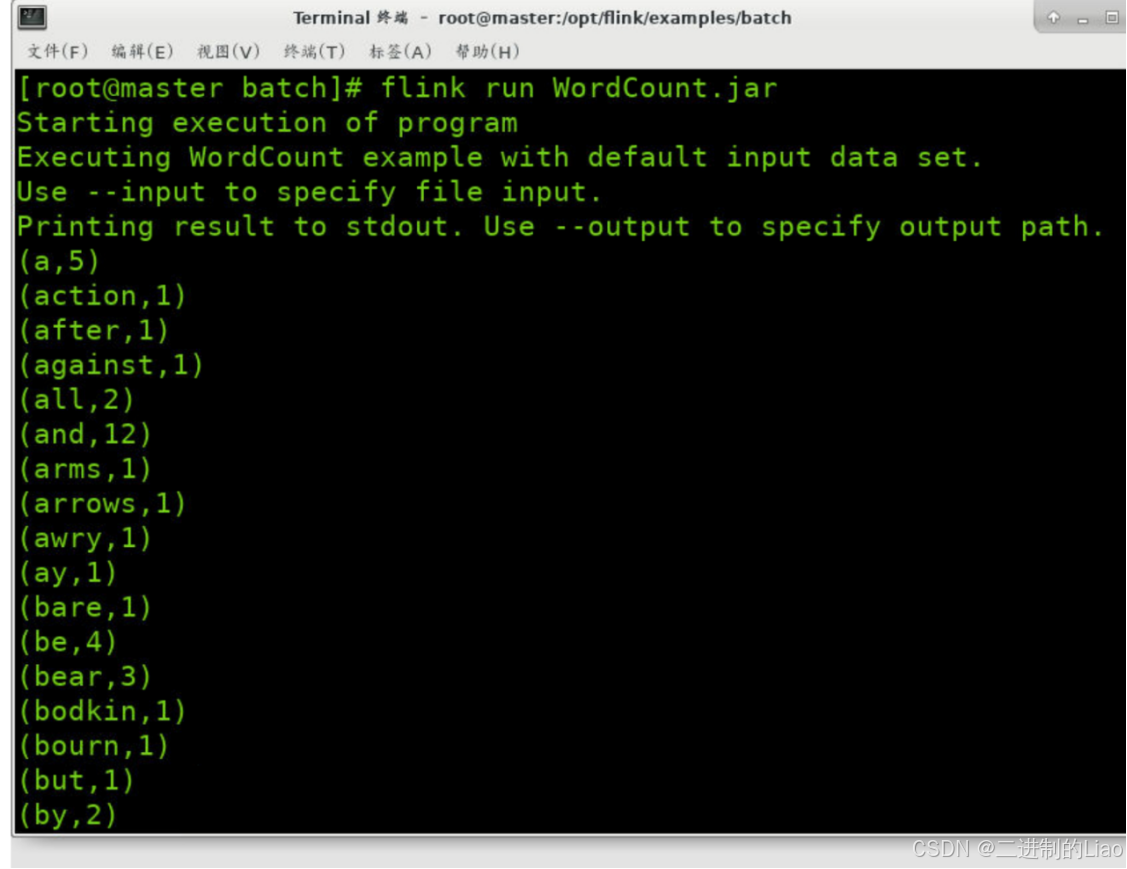
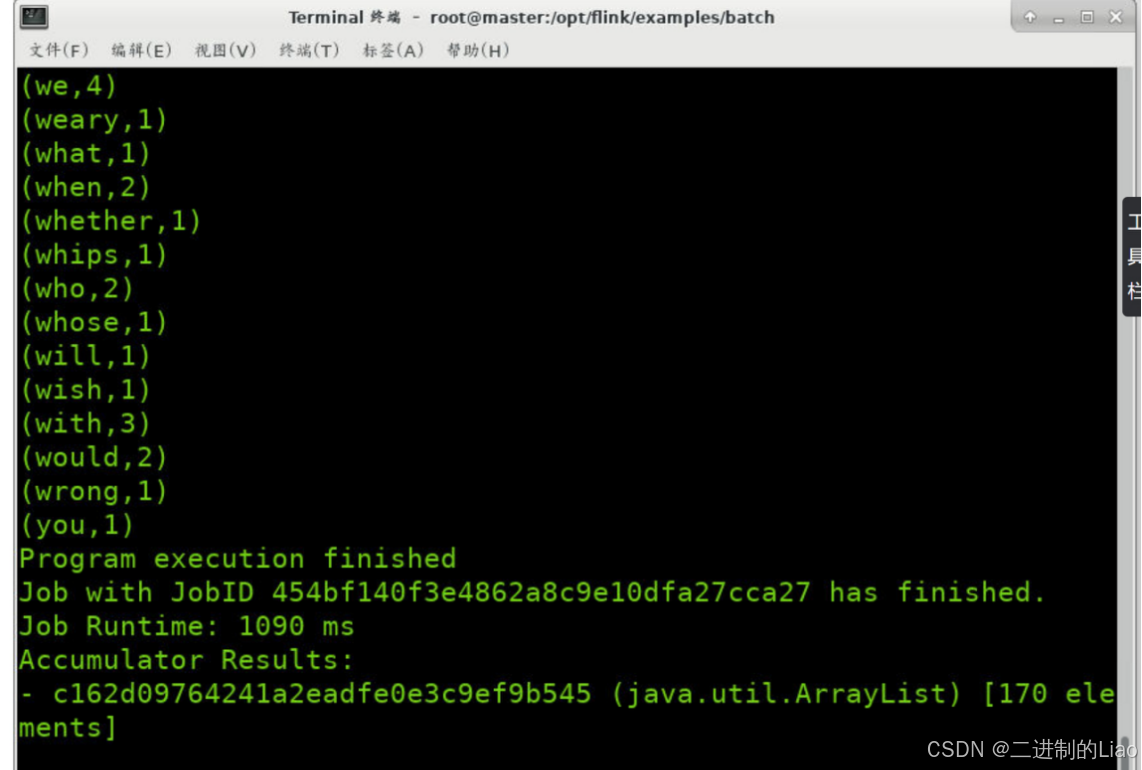
flink run WordCount.jar运行结果:
3. 安装netcat,执行nc -l 9000,类似linux的nc -l 9000命令,连接主机的9000端口;
(1)运行flink/example 的流处理示例SocketWindowsWordCount
yum install -y nc运行结果:
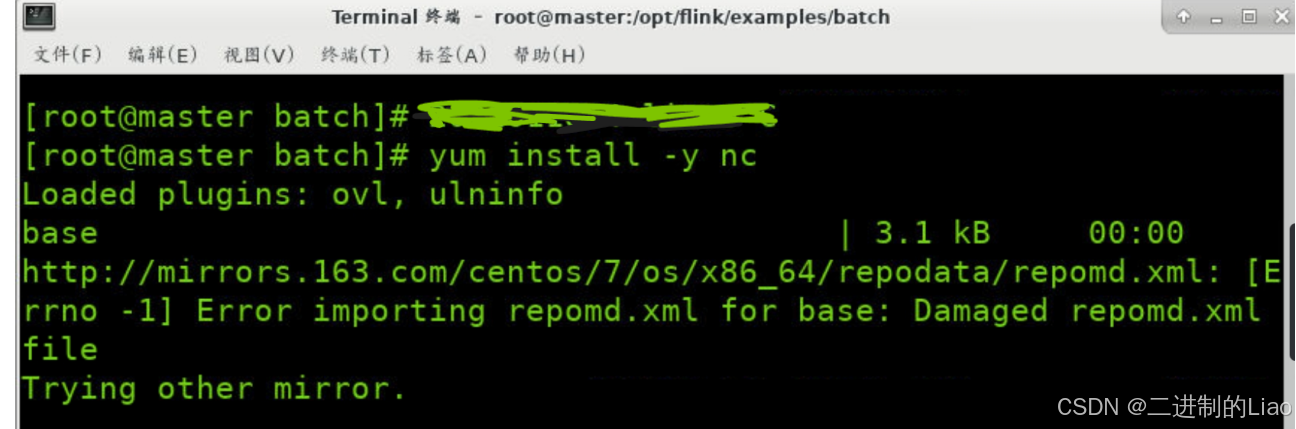
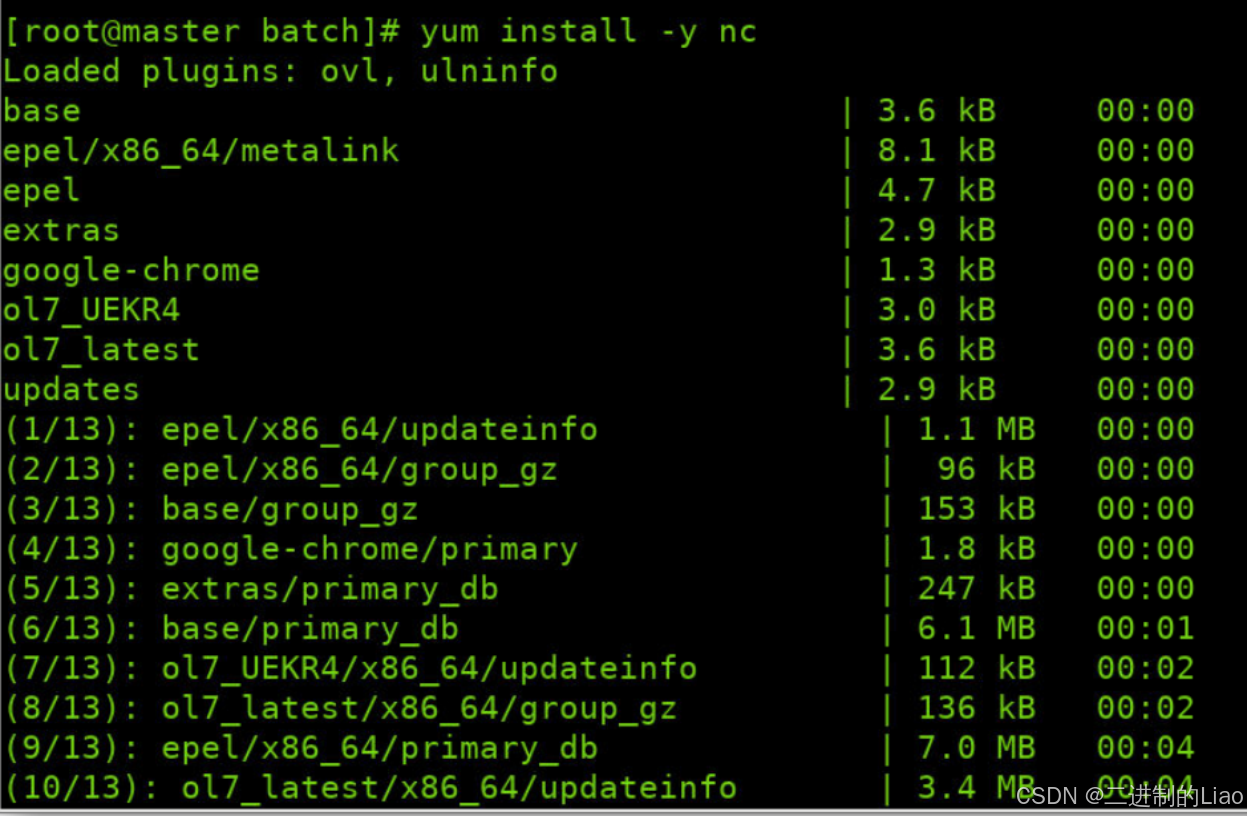
(2)开启9000端口监听
nc -l 9000
(3)新建一个终端窗口查看flink流处理实例
cd /opt/flink/examples/streaming
Ls运行结果:
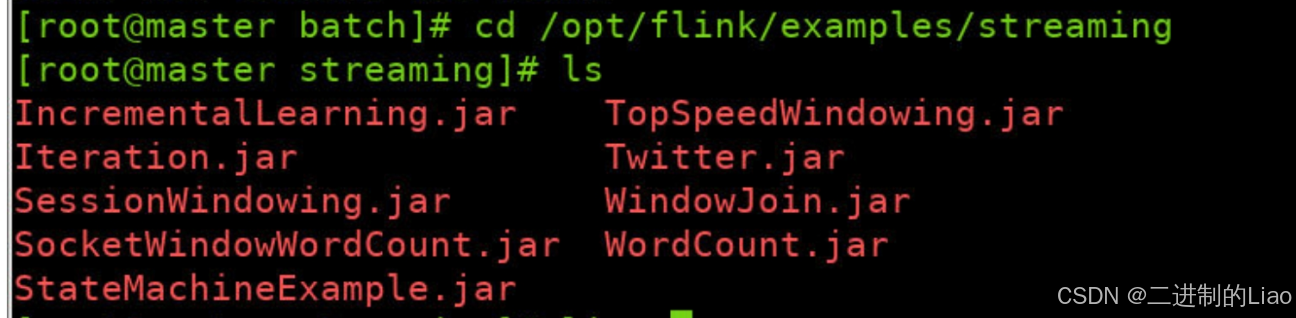
4.运行flink 实例SocketWindowWordCount.java
flink run SocketWindowWordCount.jar –port 9000运行结果:

5.dashboard显示新增的job;
访问localhost:8081
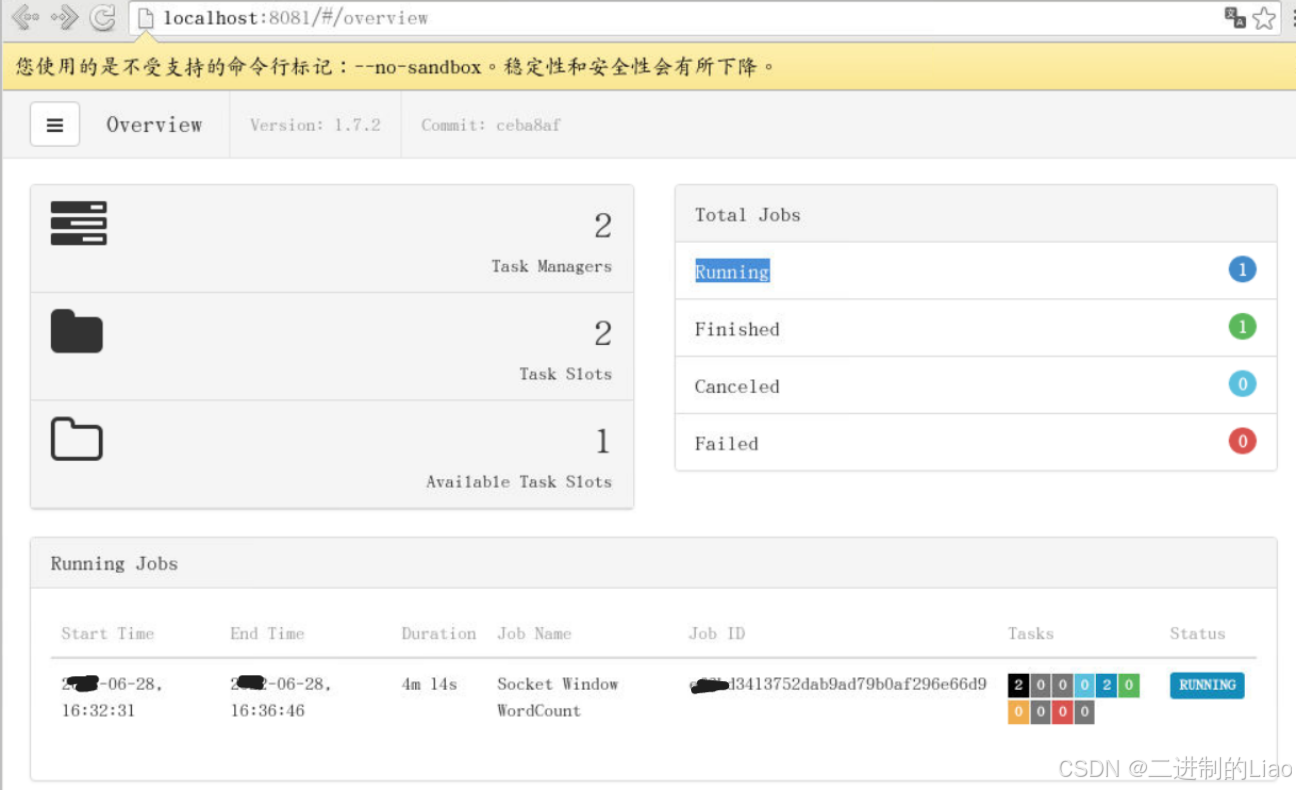


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









