







目录
1. 线性回归模型的定义
线性回归模型是一种用于建模因变量(目标变量)与一个或多个自变量(特征)之间线性关系的统计方法。它是机器学习中最基础且最常用的模型之一,广泛应用于预测、分析和解释数据。
2. 线性回归模型的数学原理
线性回归模型试图找到自变量(X)和因变量(Y)之间的线性关系,公式如下:
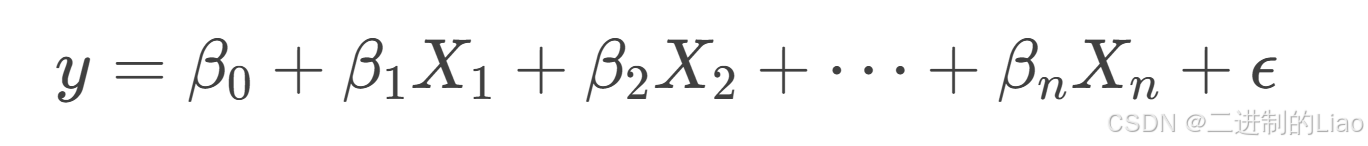
-
Y:因变量(目标值)。
-
X1,X2,…,Xn:自变量(特征)。
-
β0:截距(常数项)。
-
β1,β2,…,βn:自变量的系数。
-
ϵ:误差项。
对于简单线性回归(只有一个自变量),公式简化为:
![]()
3. 线性回归的应用领域及示例
*线性回归适用场景的特点【重点】:
- 变量之间存在线性关系
- 需要快速建模和解释
- 数据量适中,特征数量不多
- 目标是预测或分析因果关系
各领域应用示例(金融、市场营销、社会科学、环境科学)
金融领域应用示例:
- + 预测股票价格或收益率
- + 分析资产风险与回报的关系(资本资产定价模型,CAPM)。
- + 信用评分模型
市场营销领域应用示例:
- + 预测广告投入对销售额的影响
- + 分析价格变化对需求的影响
- + 客户生命周期价值预测
社会科学领域应用示例:
- + 研究教育水平与收入之间的关系
- + 分析人口特征对投票行为的影响
- + 预测犯罪率与社会经济因素的关系
环境科学领域应用示例:
- + 预测气温变化对农作物产量的影响。
- + 分析污染物浓度与环境因素的关系。
- + 研究气候变化对生态系统的影响。
4. *线性回归的核心假设 【重点】
- 线性关系 :因变量与自变量之间存在线性关系。
- 误差项的正态性 :误差项ϵ服从均值为0的正态分布。
- 误差项的独立性 :误差项之间相互独立,无自相关性。
- 同方差性 :误差项的方差恒定,不随自变量的变化而变化。
5. 线性回归的目标
通过最小化误差项的平方和(即最小二乘法),找到最优的模型参数(β0,β1,…,βn),使得预测值与实际值之间的差异最小。
P.S:什么是最小二乘法?(选看)
最小二乘法是线性回归模型中最常用的参数估计方法,其核心思想是通过最小化预测值与实际值之间的误差平方和,找到最优的模型参数。
最小二乘法的目标是找到一组模型参数(如线性回归中的截距β0和系数β1,β2,…,βn),使得预测值与实际值之间的误差平方和最小。
对于线性回归模型:
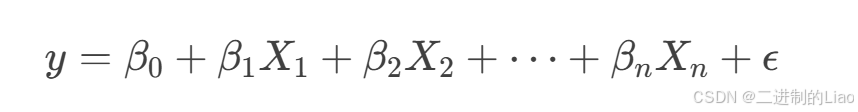
误差平方和(Sum of Squared Errors, SSE)定义为:
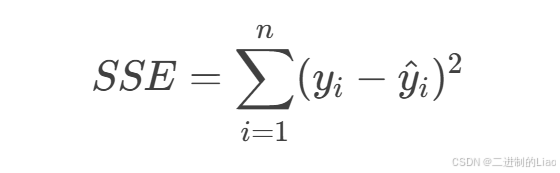
-
yi:第i个实际值。
-
y^i:第i个预测值,
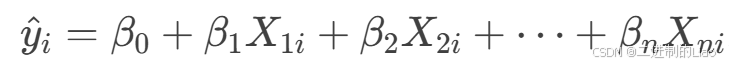
-
n:样本数量。
线性回归最小二乘法求解过程
最小二乘法通过求解以下优化问题找到最优参数:
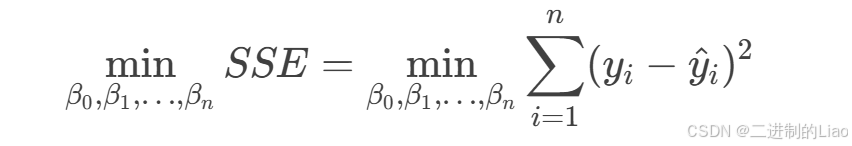
-
对每个参数(β0,β1,…,βn)求偏导,并令导数为零。
-
通过求解方程组,得到参数的最优解。
7. 总而言之,(作者的絮叨)
线性回归的数学核心是最小二乘法,而最小二乘法就是通过最小化误差平方和,找到最优的模型参数,使得模型能够最好地拟合数据。
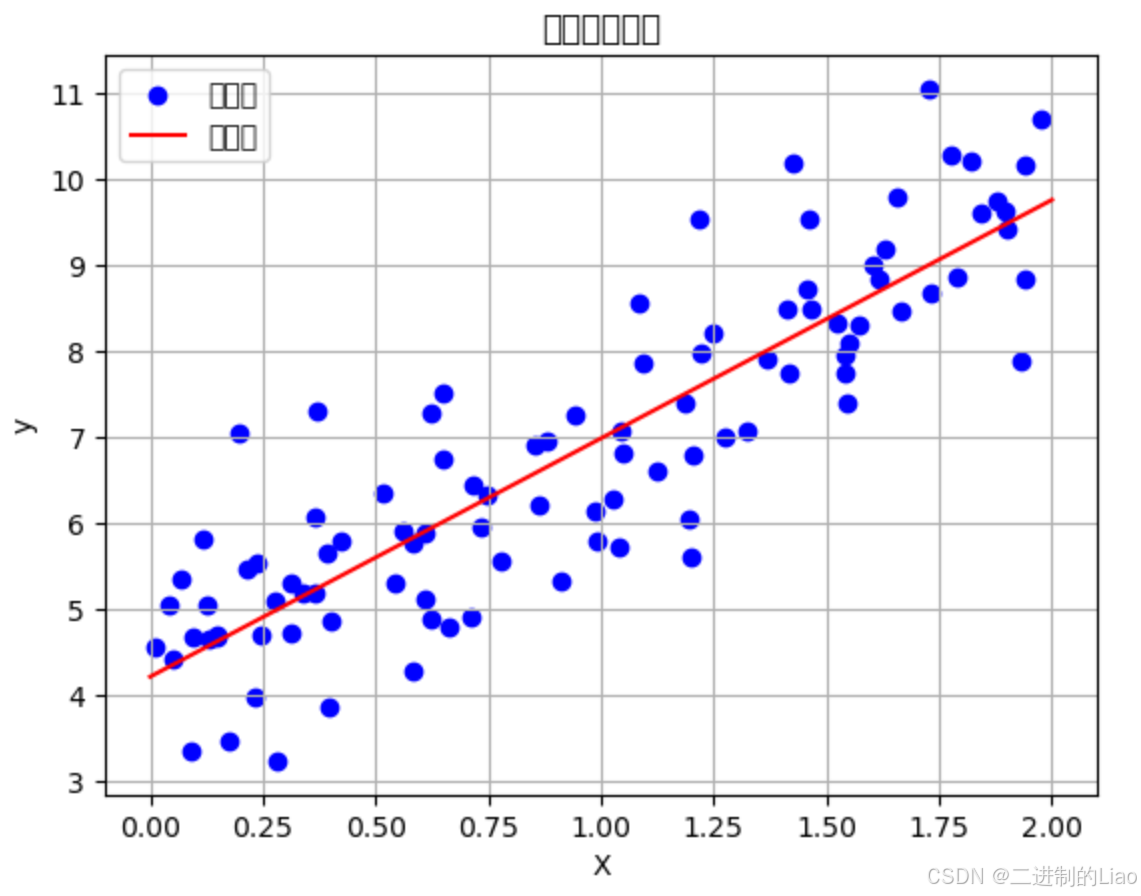
它是线性回归的基础,最基础的单变量简单线性回归就是小学初中学的一元线性方程组(如下图),一个简单的直线,用一个直线很难去概况现实中一个时间的变化关系,但是其原理是许多其他模型(如广义线性模型)的核心思想。
8. 线性回归的代码实现
1. 绘制单变量简单线性回归图
即一元线性回归图(固定公式)
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# 生成随机数据
np.random.seed(42) # 设置随机种子,确保结果可重复
X = 2 * np.random.rand(100, 1) # 生成100个随机点作为自变量X
y = 4 + 3 * X + np.random.randn(100, 1) # 生成因变量y,加入一些随机噪声
# 创建线性回归模型并拟合数据
model = LinearRegression()
model.fit(X, y)
# 预测
X_new = np.array([[0], [2]]) # 生成两个点用于绘制回归线
y_pred = model.predict(X_new)
# 绘制数据点和回归线
plt.scatter(X, y, color='blue', label="数据点") # 绘制原始数据点
plt.plot(X_new, y_pred, color='red', label="回归线") # 绘制回归线
plt.xlabel("X") # X轴标签
plt.ylabel("y") # Y轴标签
plt.title("一元线性回归") # 图表标题
plt.legend() # 显示图例
plt.grid(True) # 显示网格
plt.show() # 显示图表运行结果图:
2.线性回归模型示例代码
此代码使用代码随机生成数据作为原始数据,有数据集时把”#生成示例数据“部分替换成目标数据即可。
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 生成示例数据
np.random.seed(42)
X = 2 * np.random.rand(100, 1) # 自变量(特征)
y = 4 + 3 * X + np.random.randn(100, 1) # 因变量(目标值),加入噪声
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
# 输出模型参数
print("截距(β0):", model.intercept_)
print("系数(β1):", model.coef_)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("均方误差(MSE):", mse)
# 可视化结果
plt.scatter(X_test, y_test, color='blue', label="实际值")
plt.plot(X_test, y_pred, color='red', label="预测值")
plt.xlabel("X")
plt.ylabel("y")
plt.title("线性回归模型")
plt.legend()
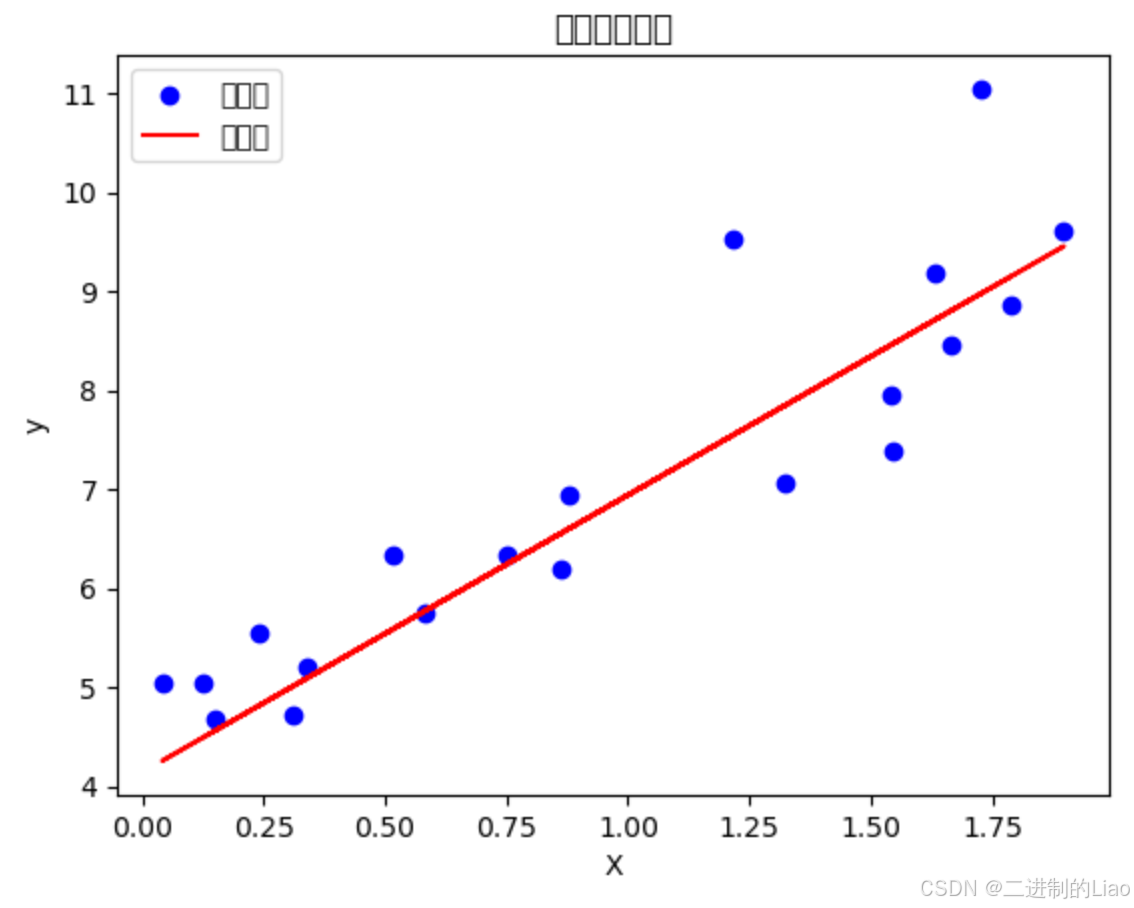
plt.show()运行结果图:

代码说明
- 使用
np.random.rand生成自变量XX。因变量yy通过公式y=4+3X+噪声y=4+3X+噪声生成,模拟真实数据。 - 使用
LinearRegression拟合数据,找到最佳截距(β0β0)和系数(β1β1)。 - 对测试集进行预测,并计算均方误差(MSE)评估模型性能。
- 绘制实际值和预测值的对比图,直观展示模型效果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









