







 本文深入探讨线性回归模型的原理与应用,包括模型理解、性能验证、特征选择及模型对比。涵盖处理长尾分布数据、交叉验证、模型调参技巧,并介绍reduce_mem_usage函数以优化内存使用。
本文深入探讨线性回归模型的原理与应用,包括模型理解、性能验证、特征选择及模型对比。涵盖处理长尾分布数据、交叉验证、模型调参技巧,并介绍reduce_mem_usage函数以优化内存使用。
内容:
线性回归模型:
线性回归对于特征的要求;
处理长尾分布;
理解线性回归模型;
模型性能验证:
评价函数与目标函数;
交叉验证方法;
留一验证方法;
针对时间序列问题的验证;
绘制学习率曲线;
绘制验证曲线;
嵌入式特征选择:
Lasso回归;
Ridge回归;
决策树;
模型对比:
常用线性模型;
常用非线性模型;
模型调参:
贪心调参方法;
网格调参方法;
贝叶斯调参方法;
Trick:
reduce_mem_usage 函数通过调整数据类型,帮助我们减少数据在内存中占用的空间
def reduce_mem_usage(df):
""" iterate through all the columns of a dataframe and modify the data type
to reduce memory usage.
"""
start_mem = df.memory_usage().sum()
print('Memory usage of dataframe is {:.2f} MB'.format(start_mem))
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype('category')
end_mem = df.memory_usage().sum()
print('Memory usage after optimization is: {:.2f} MB'.format(end_mem))
print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem))
return df
通过作图我们发现数据的标签(price)呈现长尾分布,不利于我们的建模预测。原因是很多模型都假设数据误差项符合正态分布,而长尾分布的数据违背了这一假设。参考博客:https://blog.youkuaiyun.com/Noob_daniel/article/details/76087829
拟真实业务情况
交叉验证在某些与时间相关的数据集上反而反映了不真实的情况。通过2018年的二手车价格预测2017年的二手车价格,这显然是不合理的,因此我们还可以采用时间顺序对数据集进行分隔。在本例中,我们选用靠前时间的4/5样本当作训练集,靠后时间的1/5当作验证集,最终结果与五折交叉验证差距不大
L2正则化在拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』
L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。如下图,我们发现power与userd_time特征非常重要。
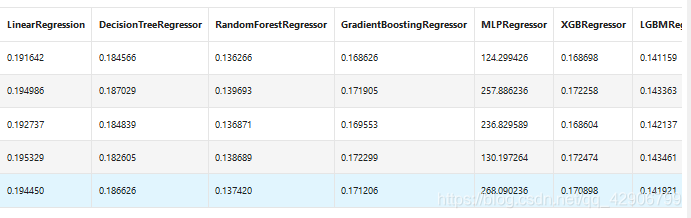
模型调参
三种常用的调参方法如下:
贪心算法 https://www.jianshu.com/p/ab89df9759c8
网格调参 https://blog.youkuaiyun.com/weixin_43172660/article/details/83032029
贝叶斯调参 https://blog.youkuaiyun.com/linxid/article/details/81189154

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









