







 本文探讨了如何在Flask应用中使用Kafka实现异步处理用户注册请求,通过Kafka的生产者-消费者模型提高并发能力和扩展性,避免了单线程处理带来的阻塞问题。
本文探讨了如何在Flask应用中使用Kafka实现异步处理用户注册请求,通过Kafka的生产者-消费者模型提高并发能力和扩展性,避免了单线程处理带来的阻塞问题。
文章目录
- 在看这个文章之前,建议先学习 kafka的工作原理 这个系列视频讲得很好,虽然基于
Java但是理解原理并不用区分语言。只需要看懂工作原理即可。
案例信息介绍
- 假设我的网站需要高并发地处理 user 注册这个简单的功能。
- 前端会发送
{"user_id": xxxx, "psw":xxx}的信息到后端完成创建- 前端用
postman来模拟 - 后端用
flask框架来简单演示
- 前端用
- 下面我用一张大致的图来表示代码的架构:
- 前端的原始数据进入后端之后,后端要用
kafka的架构在有序地处理 user 的请求,在这个任务中所有 user 的请求都是 register,因此我们就创建一个kafka的 topic 专门用来处理 user 的这类请求 - 同时由于 kafka 是通过队列的方式 异步地处理 user 的请求,所以当 kafka 处理完 user 的请求后,我们需要找到这个处理结果并返回给对应的 user
如果大家对于 异步处理 user 请求和同步处理没有概念,那么下面一章我先给大家讲一下同步处理请求和异步处理的区别
- 前端的原始数据进入后端之后,后端要用
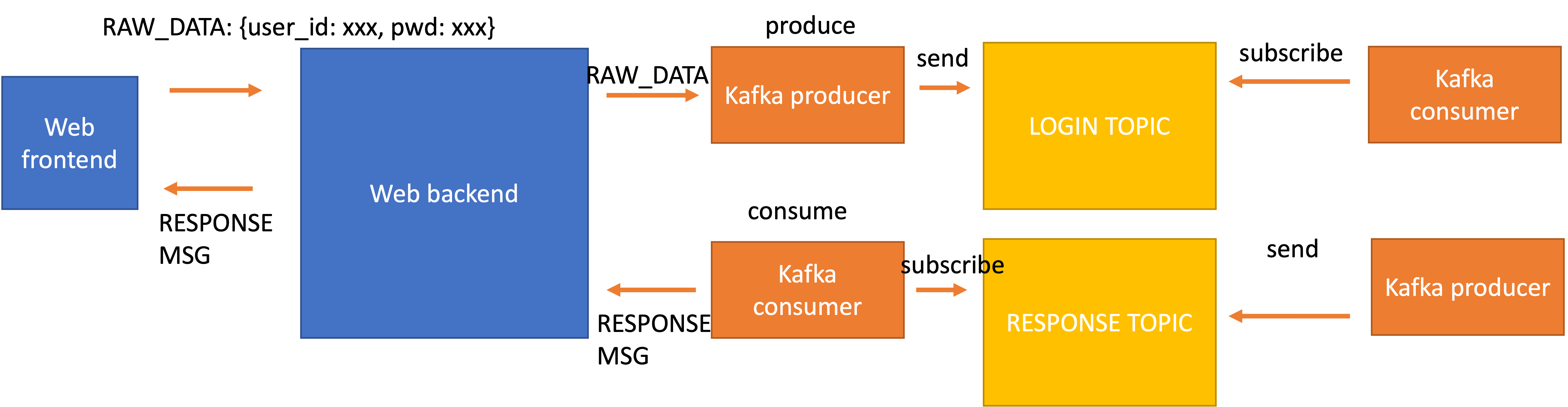
后端异步处理请求和后端同步处理请求
同步方式
"""
@file: app.py.py
@Time : 2024/3/30
@Author : Peinuan qin
"""
import threading
import json
from flask import Flask, jsonify, request
from flask_cors import CORS
from ext import FLASK_HOST, FLASK_PORT
app = Flask(__name__)
CORS(app)
@app.route("/login", methods=['POST'])
def create_user_post():
data = request.json
"""
register user code ....
"""
return jsonify({
"status": 200, "msg": "success"})
if __name__ == '__main__':
app.run(host=FLASK_HOST, port=FLASK_PORT, debug=True)
- 上述方式可以看到我的
create_user_post负责接受前端的数据并且即刻处理,处理之后将结果返回前端jsonify({"status": 200, "msg": "success"}),这个过程是一行接着一行发生的,如果中途出现了很耗时的操作,那么程序会一直等着。 - 在 Flask 应用中,如果
"register user code ...."处理需要20秒,这确实会阻塞处理该请求的线程,直到该过程完成。由于 Flask 开发服务器默认是单线程的,这意味着在这20秒内,服务器将无法处理来自其他用户的任何其他请求。 - 为了允许 Flask 同时处理多个请求,你可以启用多线程模式。这可以通过在
app.run()中设置threaded=True来实现app.run(host=FLASK_HOST, port=FLASK_PORT, debug=True, threaded=True)。这样,Flask 将能够为每个请求启动一个新的线程,从而允许同时处理多个请求。但这仍然并不是一种很好的方法,因为整个服务器来看,不具备扩展性。 假设我们服务器为每个 user 的请求开一个线程,那么服务器资源是有限的,当服务器宕机,也并不能很快的恢复这就导致扩展性很差。
异步方式
import threading
import json
from flask import Flask, jsonify, request
from flask_cors import CORS
from ext import FLASK_HOST, FLASK_PORT, users_streams, LOGIN_TOPIC, producer, logger, ResponseConsumer
from kafka_create_user import kafka_consumer_task
app = Flask(__name__)
CORS(app)
@app.route("/login", methods=['POST'])
def create_user_post():
data = request.json
# 发送数据到Kafka
producer.produce(LOGIN_TOPIC, key=str(data['user_id']).encode("utf-8"), value=json.dumps(data).encode("utf-8"))
producer.flush()
logger.info("send message to consumer")
return jsonify({
"msg": "你好,请求正在处理"})
- 我们先忽略其他的代码,只看这一部分。
- 这里相当于我们接受 user 的请求之后,通过 kafka 把处理请求的需要转移到外部的服务器集群上去了。而 kafka 的特性在于非常高的可扩展性。增加 kafka 的节点就可以线性地将任务处理的数量提高。
- 如果你看我上面给的那张图,
kafka可以通过无限制增加consumer的数量来提高数据的处理能力。而后端的服务器需要做的就是把这些数据不断地派发出去,这个步骤相比于直接在后端将所有的请求处理来说可以忽略不计。
环境文件目录
.
├── app.py
├── ext.py
├── kafka_create_user.py
└── requirements.txt
配置
.env
- 首先构建一个配置文件
.env来存放基础的配置信息
FLASK_HOST=0.0.0.0
FLASK_PORT=9300
# LOGIN 这个 topic 是用来处理用户注册这个业务的
LOGIN_TOPIC=LOGIN
# RESPONSE_TOPIC 则是用来构建 response 来返回前端成功或者失败
RESPONSE_TOPIC=RESPONSE_TOPIC
requirements.txt
kafka-python==2.0.0
colorlog==6.7.0
configparser==5.3.0
flask==2.3.2
flask_basicauth==0.2.0
Flask-JWT-Extended==4.6.0
Flask-Limiter==3.5.1
Flask-PyMongo==2.3.0
requests==2.31.0
gunicorn==21.0.0
pymongo==4.6.0
pdfminer.six==20231228
flask_cors==4.0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1752
1752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











