









promQL语句和mysql数据库中select语句类似,都是用于查询某个对象下的数据信息
我们可以直接把promeheus中的"指标"看作是mysql中的"数据表"
通过查询指标,可以得到指标这个表中的存放的数据信息。并且可以通过筛选过滤来得到某个指标的详细信息
前言
#我们通过promQL语句查询得到的值主要有以下两种
1. "瞬时向量" #查询得到最新的值,(实时数据)通常用于报警、实时监控
2. "区间向量" #查询某一段时间范围内所有的样本值,多用于数据分析、预测
一. 瞬时向量
#查询磁盘总量
node_filesystem_size_bytes
#通过下图,可以看到直接通过查询指标的名称,可以查询这个指标(表)中所有的数据
#而我们获取到的这个值,是一个实时数据。你可以多点几下,可以发现后面的值一直在变返回
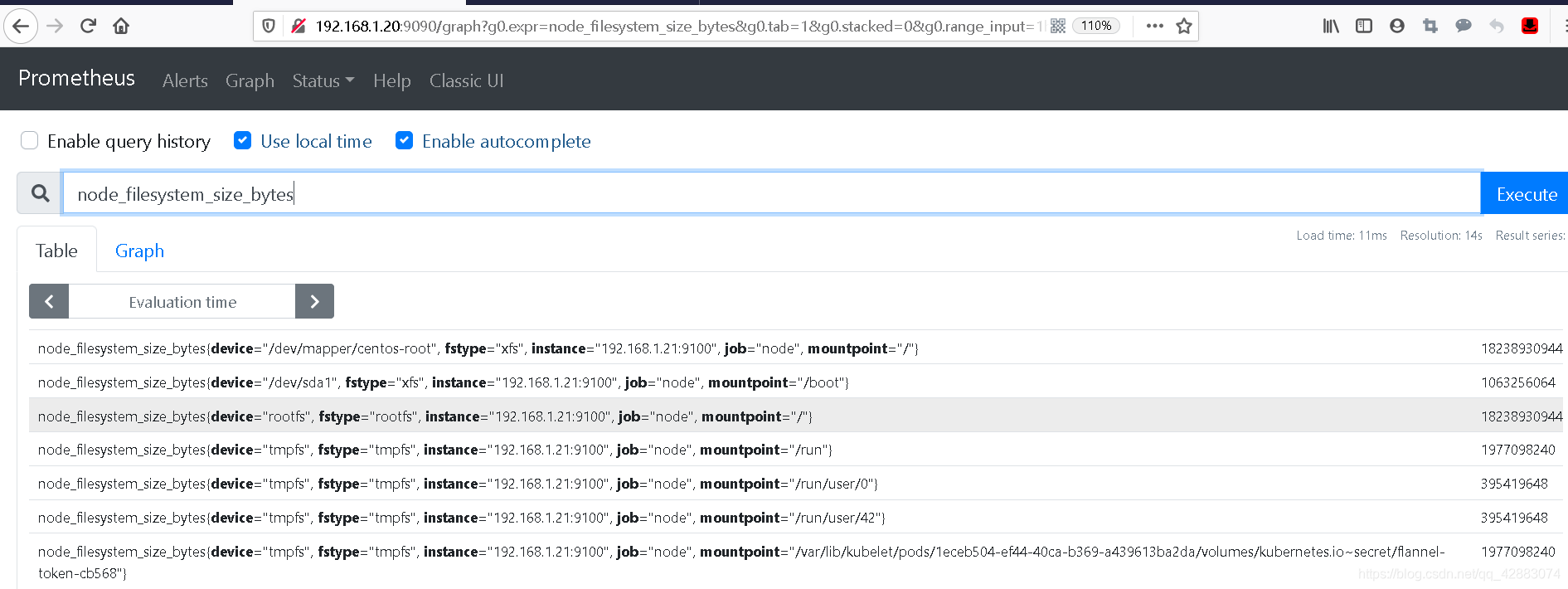
通过上面的查询我们获取到了该"指标(表)"下的所有数据
但很多时候希望可以获取单条的详细信息,而不是大量无用的信息
在promQL语句中,我们可以通过"标签"对查询的数据进行筛选
案例1 筛选过滤
#我们添加一个mountpoint="/"的标签 (显示/分区的信息)
#必须满足这个标签的值才会显示
node_filesystem_size_bytes{mountpoint="/"}
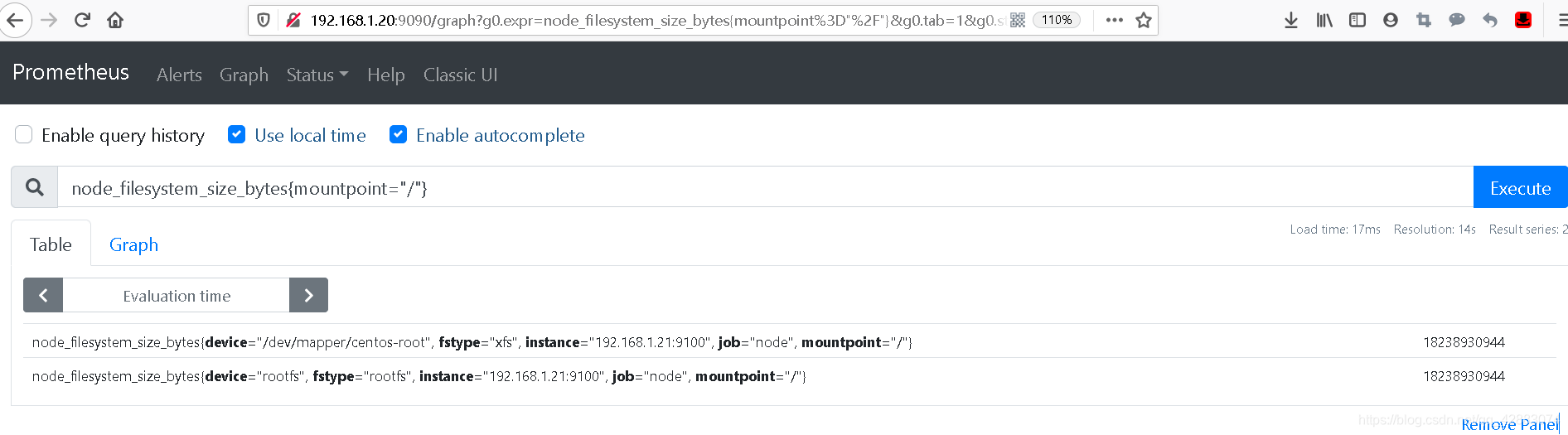
案例2 多层筛选
上图可以看到符合该条件的信息只有两条,但第二条rootfs明显是我们不需要的,我们可以再此过滤
#在上面的基础上我们再追加一个device != "rootfs"
#注意,这里使用的是"!=" 不等于
node_filesystem_size_bytes{mountpoint = "/",device != "rootfs"}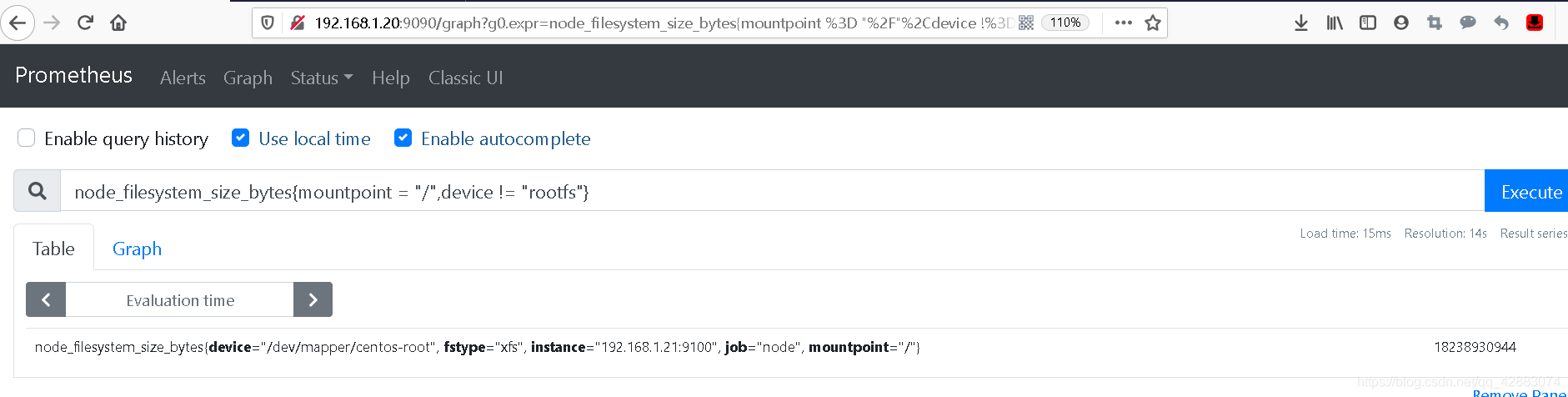
案例3 算数运算
我们通过筛选得到了一个单独的值,但这个数值并不方便理解。 我们将他转换一下
node_filesystem_size_bytes{mountpoint = "/",device != "rootfs"} / 1024 / 1024 / 1024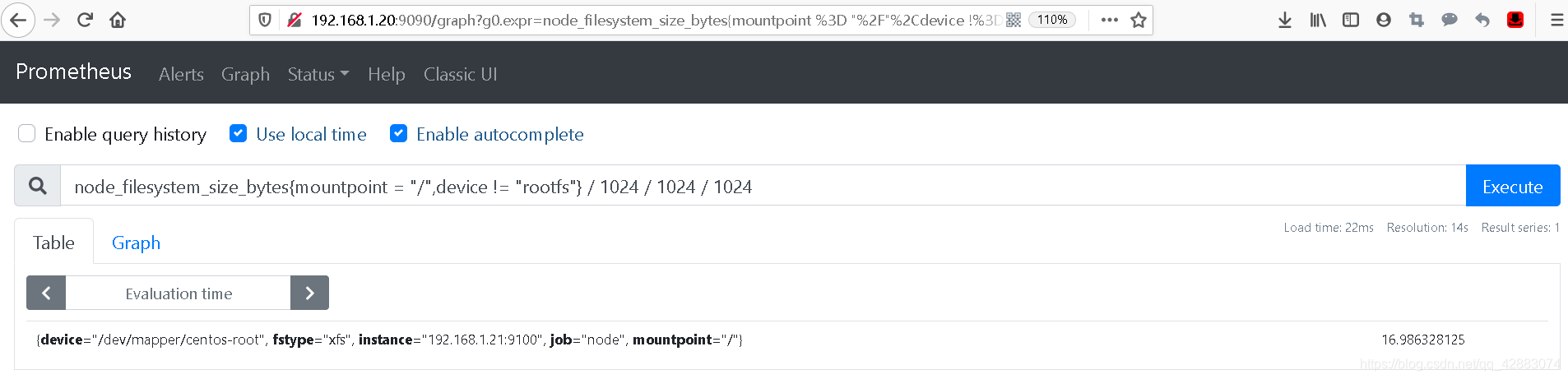
#得到如下的信息
{device="/dev/mapper/centos-root", fstype="xfs", instance="192.168.1.21:9100", job="node", mountpoint="/"} 16.986328125
#我们回主机上查看
[root@k8s-node01 ~]# df -h | grep /$
/dev/mapper/centos-root 17G 5.8G 12G 35% /
#可以看到是很接近的,四舍五入的是17小知识
#当我们使用下面语句查询时
node_filesystem_size_bytes{instance="192.168.1.21:9100"}
#实际上是以下面的形式运行的
{__name__="node_filesystem_size_bytes",instance="192.168.1.21:9100"}
案例4 模糊匹配
我们并不是在所有的情况下都需要单个信息,当节点信息过多的时候。
我们有时会进行一些模糊的匹配机制来获取多个资源的值
#和上面的语法类似,不同的是将 (=,!=) 替换为了(=~,!~)
#如下
#匹配到的ip都会显示
node_filesystem_size_bytes{instance=~"(192.168.1.20:9100|192.168.1.21:9100|192.168.1.22:9100)"}
#匹配到的ip都不会显示
node_filesystem_size_bytes{instance!~"(192.168.1.20:9100|192.168.1.21:9100|192.168.1.22:9100)"}二. 区间向量
上面我们通过promQL查询到的数据会返回一个样本值,这个值我们称之为"瞬时向量"
而我们想要获取一段时间范围内的数据时,我们则需要使用"区间向量表达式"
#首先我们要先了解一下时间范围的单位
#缩写 #单位
s Seconds 秒
m Minu 分
h Hours 时
d Days 天
w Weeks 周
y Years 月案例1 获取2分钟内磁盘可用容量的值
#在结尾添加[2m]
node_filesystem_free_bytes{mountpoint = "/",device != "rootfs"}[2m]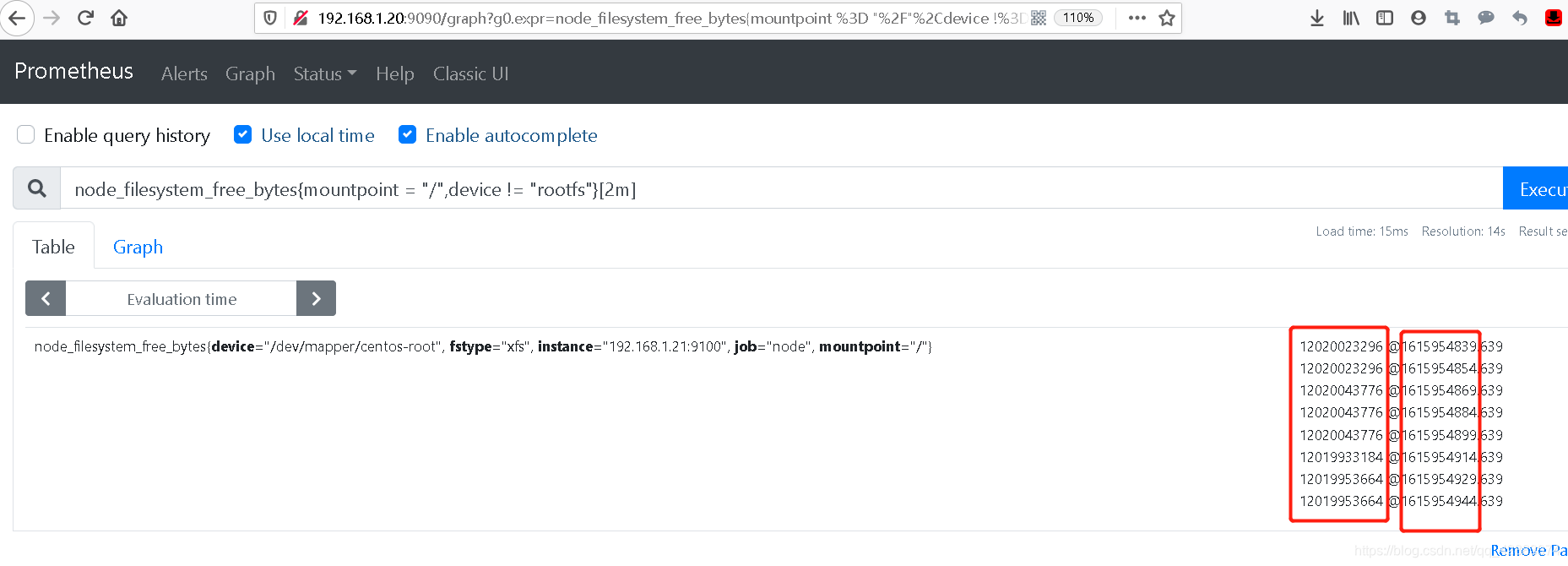
可以看到,他会返回在2分钟内磁盘变化的值,前面标记的是磁盘可用的空间后面是磁盘最大空间
案例2 范围查询的偏移量(offset)
上面我们查询到了2分钟内的数据,但是我们现在反过来。
我们要查询2分钟之前的数据、或者昨天的数据做统计,就需要用到"偏移量"
#查询1小时前的最后两分钟的磁盘可用大小
node_filesystem_free_bytes{mountpoint = "/",device != "rootfs"}[2m] offset 1h
#不过本地查看,也没什么太大的浮动。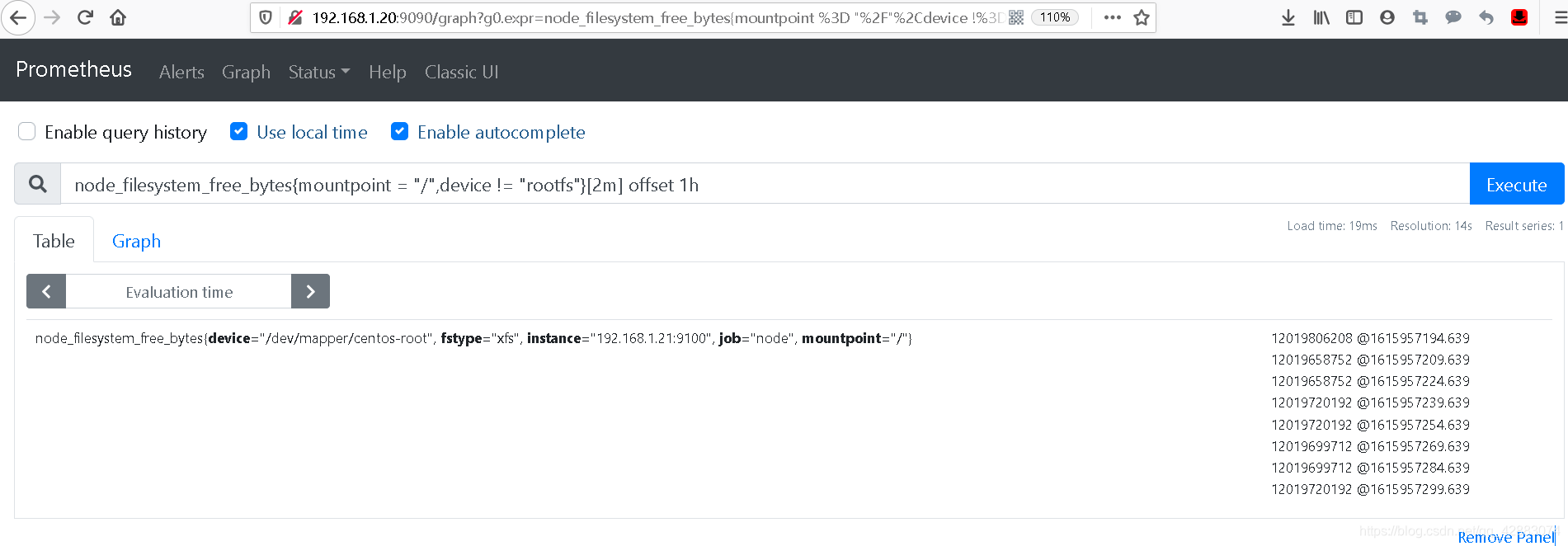
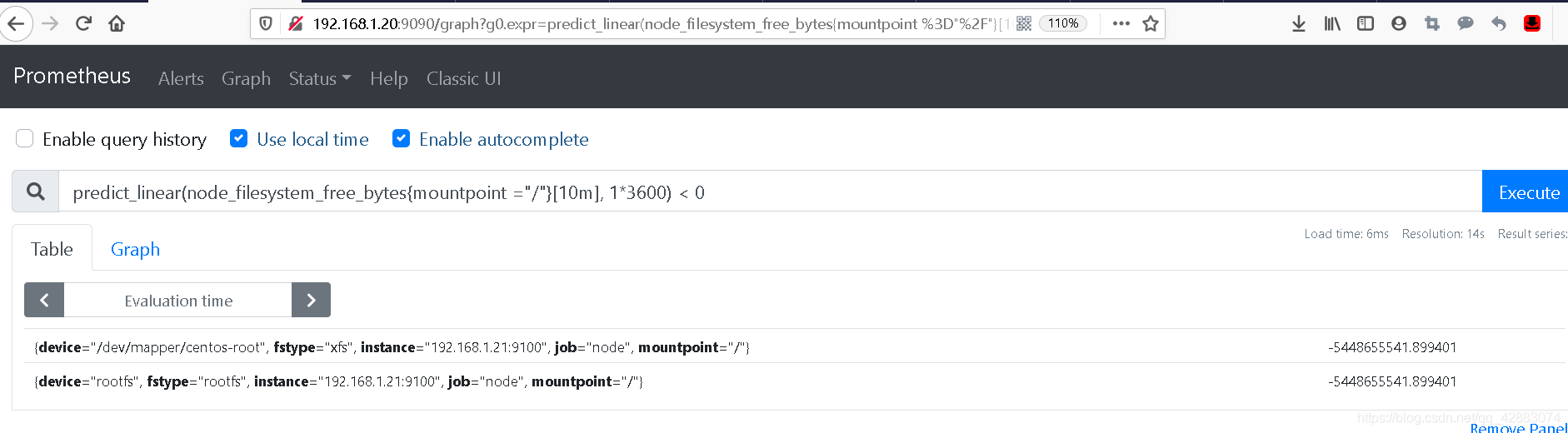
我们可以通过predict_linear() 去预测磁盘多久会用完 (当返回的值小于0时可以设置报警)
#这里我们根据磁盘可用量在10分钟内的增长值,去预测1个小时内会不会占满
predict_linear(node_filesystem_free_bytes{mountpoint ="/"}[10m], 1*3600) < 0
#不出意外应该不会查询到任何东西
#自然增长没那么快,我这里磁盘容量大小是17G,我们去创建一个大文件做测试
dd if=/dev/zero of=file bs=5000M count=1 #写入一个5G的文件
刚开始的时候,我们不是很清楚要写些什么,可以先看看grafana上面的模板的语句进行参考

















 670
670

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









