



JMeter 接口测试的参数化是实现高效、强大自动化测试的核心技能。它允许使用不同的数据多次执行同一个请求,模拟真实用户的多样性,并发现更深层的问题。
以下是对 JMeter 参数化方法的全面梳理,从基础到高级,并配有最佳实践。
参数化核心思想
*分离:将测试数据与测试逻辑(脚本)分离。
*动态替换:在请求发出前,从数据源中读取数据并替换掉脚本中的占位符。
类别一:从外部文件读取参数(最常用)
**1. CSV 数据文件设置 (CSV Data Set Config)
这是 最经典、最强大、最常用 的参数化方法。
*配置路径:添加 > 配置元件 > CSV 数据文件设置
*核心参数:
*文件名:CSV文件的完整路径(建议使用绝对路径)。
*文件编码:如 UTF-8,防止中文乱码。
*基本使用步骤:
1.创建一个 .csv 或 .txt 文件(如 user_data.csv)。
2.文件内容如下(逗号分隔):
username,password,product_id
user1,pass123,1001
user2,pass456,1002
user3,pass789,1003
3.在 JMeter 中添加一个 CSV 数据文件设置 元件。
4.配置元件:
*文件名:D:\test_data\user_data.csv
*变量名称:username,password,product_id(与文件列头对应)。
4.在线程组中,添加你的 HTTP 请求(如登录请求)。
5.在请求中将需要参数化的地方替换为 ${变量名},如 ${username}, ${password}。
类别二:在 JMeter 内部直接设置参数
2. 用户定义的变量 (User Defined Variables)
这种方法适合定义一些全局、静态、不常变化的参数。
*配置路径:添加 > 前置处理器 > 用户定义的变量(也可以放在测试计划或线程组下)。
*特点:
*静态/全局:通常在所有线程中共享。
*使用场景:配置 HTTP 请求默认值(如服务器名称、端口)。
注意:由于它通常在测试开始前就初始化,所以所有线程看到的初始值都是一样的*。如果勾选了“每迭代重置一次”,则会在每次循环时重置为初始值。
*最佳实践:将其作为 “默认配置” 使用,复杂的动态数据仍需配合 CSV 文件。
3. 函数助手 (Function Helper)
用于生成动态的、唯一的数据,如随机数、时间戳。
*配置路径:菜单栏 > 工具 > 函数助手对话框。
*常用函数:
*__Random:生成随机数。
*__RandomString:从给定字符中生成随机字符串。
*__time:生成当前时间戳。
*__threadNum:获取当前线程编号。
*__UUID:生成全局唯一的ID,非常适合注册等场景。
*如何使用:
1.打开 函数助手。
2.选择一个函数(如 __Random)。
3.设置参数(如最小值 1,最大值 1000)。
4.点击“生成”按钮,会生成一个函数字符串,如 ${__Random(1,1000, productID)},可直接在请求参数中使用。
上面的方法主要解决了数据来源的问题,但要真正模拟现实场景,我们还需要掌握两种高级策略:
类别三:关联参数与动态生成
此类别主要解决两个问题:
1.参数组合:如何确保来自同一行的数据(如正确的用户名和密码)在同一个循环中被使用。下面是两种典型的应用场景:
4. 用户参数 (User Parameters)
与前几种方法相比,用户参数 前置处理器更适合需要在同一个循环中配对使用多个参数的情况。
5. JDBC Request(从数据库取数)
当参数数据存储在数据库中时,可以使用此方法。
*配置路径:添加 > 配置元件 > JDBC Connection Configuration(先配置数据库连接)。
*使用场景:测试一个电商下单流程,需要在同一个迭代中使用相同的用户名、密码、商品ID。
实战演示:模拟用户登录并浏览商品
目标:使用不同用户账号登录,然后查看随机的商品。
1.准备数据文件 (test_data.csv)
username,password,product_id
test_user01,123456,8001
test_user02,abcdef,8002
测试计划结构:
测试计划
├─ JDBC Connection Configuration (配置数据库连接,可选)
├─ 线程组 (Thread Group)
│├─ 计数器 (Counter,用于生成动态ID,可选)
├─ CSV 数据文件设置 (指向 `test_data.csv`)
├─ HTTP请求 - 登录 (使用 `${username}`, `${password}`)
├─ HTTP请求 - 查看商品 (使用 `${product_id}`)
└─ 查看结果树
参数化配置:
*登录请求:
*路径:/api/login
*参数:username=${username}, password=${password})
在这个例子中,我们综合运用了多种参数化方法:
***CSV 数据文件设置** 提供了核心的测试账户。
***计数器** 可以用于生成递增的ID,作为注册或其他业务的参数。
***随机函数** 用于模拟用户查看不同商品的行为。
---
### **最佳实践与注意事项**
1.**首选 CSV 数据文件设置**: 对于大量、复杂的测试数据,这是最灵活、性能最好的选择。
2.**文件名使用绝对路径**: 避免在分布式测试时找不到文件。
3.**巧妙运用多种方法**:一个完整的测试计划通常会组合使用多种参数化方法,比如用 CSV 处理核心业务数据,同时用函数生成辅助的动态参数。
通过熟练掌握这些方法,您可以构建出高度数据驱动、能够模拟真实复杂场景的 JMeter 测试脚本。
JMeter 参数化的核心思想
参数化:将测试脚本中的固定值(如用户名、订单ID、密码)替换为动态的、可配置的变量。
目的:
1.模拟真实场景:不同用户使用不同数据发起请求。
2.避免缓存和数据库约束(如重复用户名无法注册)。
3. 实现数据驱动测试:使用同一套脚本,执行不同的测试数据。
为了让您对这8种方法的选择有一个全局视角,我整理了以下决策流程图:
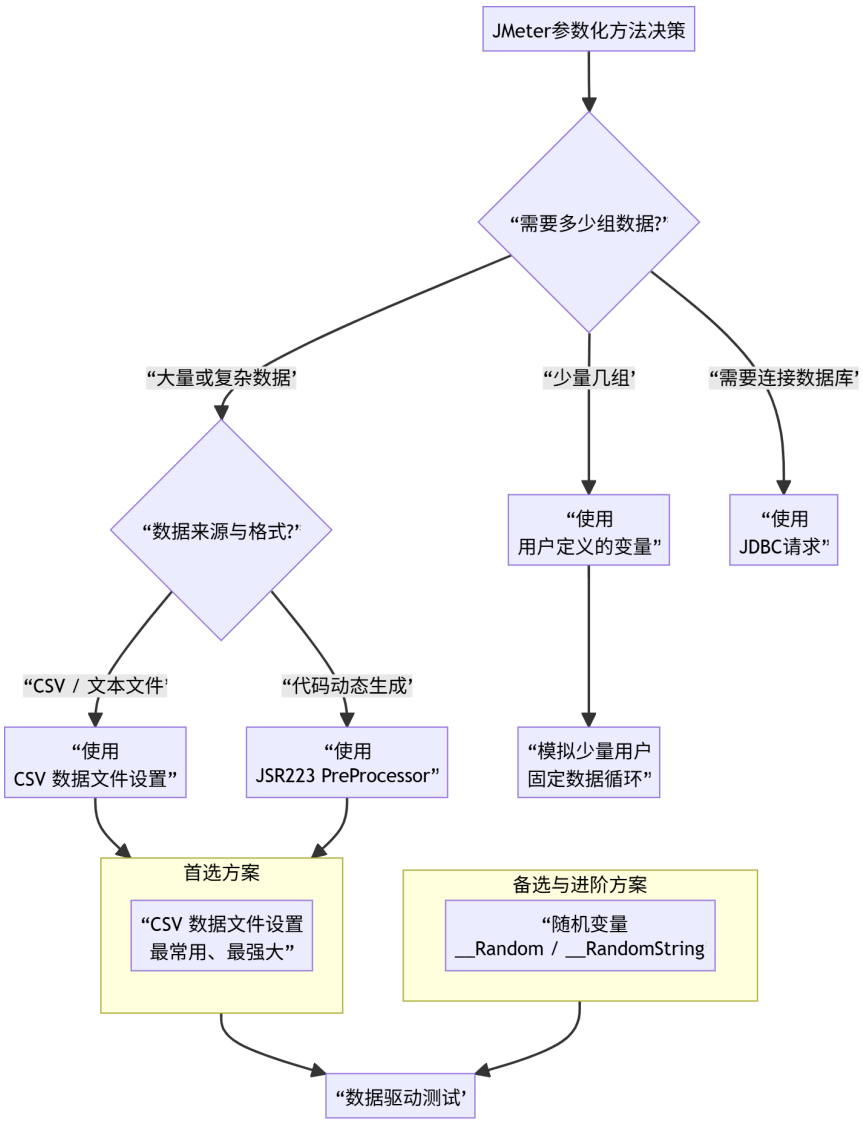
下面,我们详细探讨每种方法的具体操作。
方法一:CSV 数据文件设置 — 最经典、最强大
这是最常用、最灵活的参数化方法,特别适合从文件导入大量测试数据。
-
使用场景:需要模拟大量用户(如1000个用户)或有复杂数据关联(如用户名对应其专属订单ID)。
-
配置步骤:
- 添加配置元件 → CSV 数据文件设置。
- 准备一个CSV或TXT文件,例如
user_data.csv:
username,password,orderId
testuser1,pass123,100001
testuser2,pass456,100002
- 参数化界面配置:
- 文件名:浏览到你的
user_data.csv。 - 文件编码:一般用
UTF-8。
- 在 HTTP 请求中,使用
${username},${password}引用。
- 核心参数详解:
- 变量名称:用英文逗号分隔的变量名列表,与CSV文件的列一一对应。例如:
username,password,orderId。
- 关于“遇到文件结束符再次循环?”:
True:当读完最后一行数据后,又回到第一行开始读取。- 遇到文件结束符停止线程?:如果设为
True,当数据用完时,线程将停止,不再循环。 - 遇到文件结束符再次循环? = False
- 遇到文件结束符停止线程? = True:线程结束时,测试也跟着停止。这是进行长时间压力测试时的常用设置。
- 共享模式:默认“所有线程”,表示所有线程组共享这一份数据。例如,线程1取第一行,线程2取第二行。
- 分隔符:默认逗号,如果数据中包含逗号,可以设置为
|等其他分隔符。
方法二:用户定义的变量 — 适用于全局常量
用于定义一些在测试计划中基本不变的参数,如主机名、端口、基础路径等。
-
使用场景:一个电商网站的URL,所有请求都基于这个HOST。
-
配置步骤:
- 添加 → 配置元件 → 用户定义的变量。
- 特点:
- 数据是固定的,不随线程或循环而变化。
方法三:函数助手 — 快速生成动态数据
JMeter 提供了丰富的内置函数,可以生成随机数、字符串、时间戳等,非常适合需要动态变化但不依赖外部文件的参数。
-
常用函数:
-
__Random:生成随机数。
-
__time:获取当前时间戳。
-
__threadNum:获取当前线程编号。
-
使用步骤:
- 通过菜单栏 工具 → 函数助手对话框。
- 选择一个函数,如
__Random,设置最小值、最大值,以及一个存储结果的变量名,然后点击“生成”来创建函数表达式。
方法四:JDBC Request — 从数据库获取
这是 “动态参数化” 的终极方案,直接从数据源获取最新、可用的数据。
- 使用场景:
- 需要一个随机的用户ID:
${__Random(1,10000, userId)}
实战技巧:常用于查询类接口。先执行一个 JDBC Request 从数据库查询出数据(如最新创建的订单号),将其存入一个变量(如 ${order_id}),然后在后续请求中引用。
方法五:JSR223 PreProcessor — 高度灵活与强大
通过编程方式(支持Groovy、Java等)动态生成或处理数据。
- 使用场景:需要非常复杂的数据生成逻辑,或需要对已有数据进行处理。
方法六:用户参数 — 适用于少量、固定的用户数据集
位于前置处理器中,允许你为一个或多个用户定义多组参数。
方法七:Beanshell 取样器 — 旧的编程方式
功能与JSR223类似,但性能较差,不推荐在新脚本中使用,仅用于兼容旧脚本。
方法八:随机变量 — 简易随机数据
这是一个独立的配置元件,可以定义一个随机字符串变量。
最佳实践与调试技巧
1.变量引用语法:${变量名}。
2.作用域:JMeter变量遵循作用域规则(如仅在同一个线程组内有效)。
3.参数优先级:如果一个变量在多处定义,优先级从高到低一般为:
- 线程组/采样器内的局部变量 > CSV 数据文件设置 > 用户定义的变量。
掌握这些方法,尤其是 CSV 数据文件设置 和 JSR223 PreProcessor,你将能应对绝大多数接口参数化场景。

















 2637
2637

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









