







1 百度网站
如果使用如下代码之后会出现控制台打印的出来html代码,但是文件里面没有。所以需要修改。
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
print(resp.read().decode("utf-8"))
with open("mybaidu.html",mode="w") as f:
f.write(resp.read().decode("utf-8"))
print("over!")修改后是这样的:
from urllib.request import urlopen
url = "http://www.baidu.com"
resp = urlopen(url)
ht = resp.read().decode("utf-8")
print(ht)
with open("mybaidu.html",mode="w") as f:
f.write(ht)
print("over!")但是仍然出现下面乱码情况
原因可能是编码方式错误,所以出现乱码,修改如下:
with open("mybaidu.html",mode="w",encoding='utf-8') as f:运行结果正确:
2 Web请求过程剖析
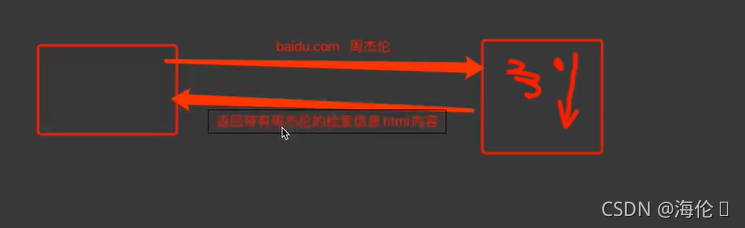
1.服务器渲染:在服务器那边直接把数据和html整合在一起,统一返回给浏览器,在页面源代码中能看到数据。
2.客户端渲染:第一次请求只要html骨架,第二次请求拿到数据,进行展示,在页面源代码中,看不到数据。
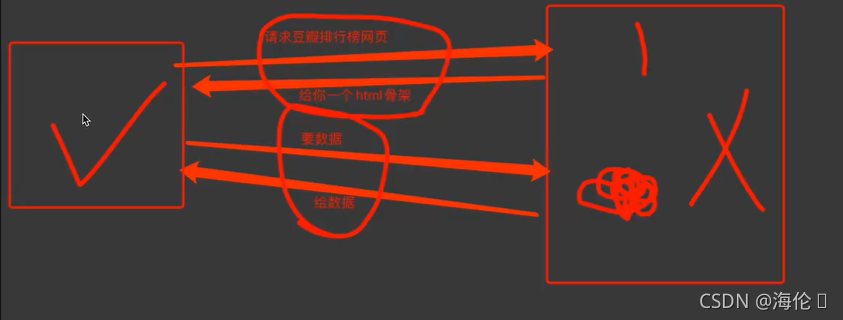
所以要熟练使用浏览器抓包工具:数据并不是在第一次请求里面,而是在第二次请求里面。而且请求为规则的json格式如下。
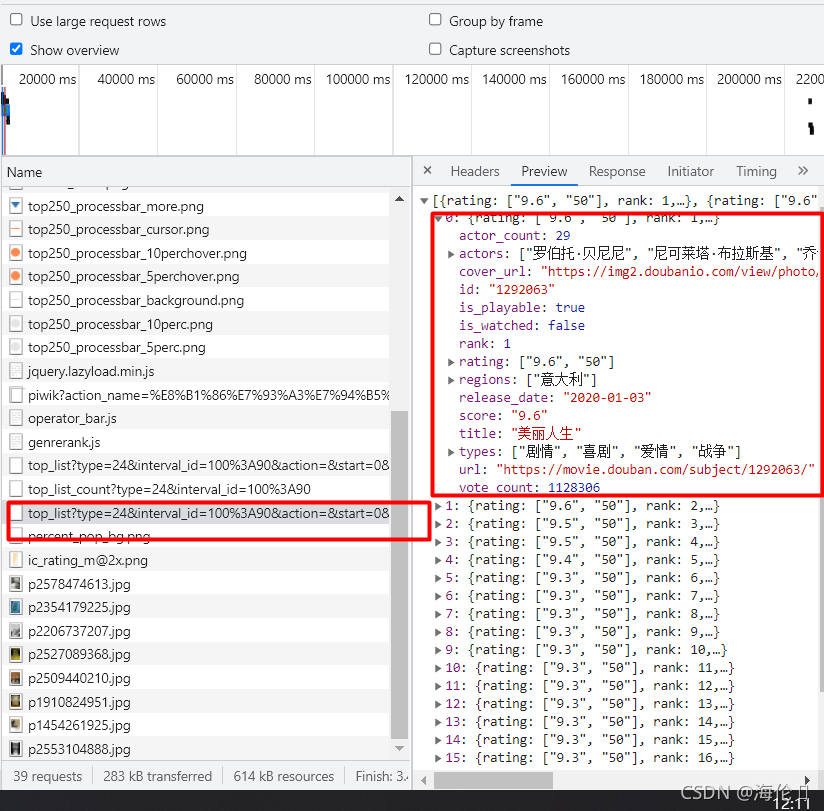
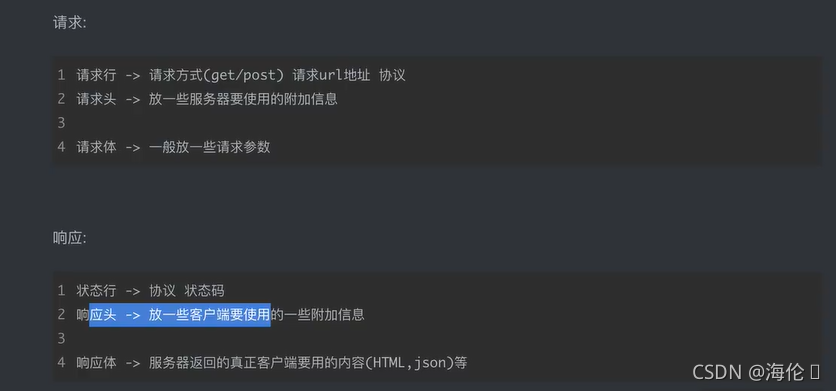
3 http协议

4 request入门
- get请求方式
import requests
query = input("请输入你喜欢的明星:")
url = f'https://www.baidu.com/s?wd={query}'
Hd = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
resp = requests.get(url, headers=Hd) #处理一个小小的反爬
print(resp)
print(resp.text)- post请求方式
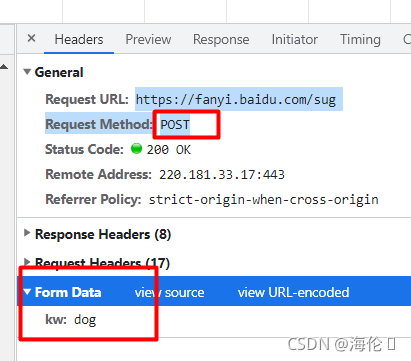
import requests
url = "https://fanyi.baidu.com/sug"
s = input("请输入你要翻译的英文:")
dat = {
"kw":s
}
#发送post请求,发送的数据必须放入字典中,通过data参数进行传递
resp = requests.post(url , data=dat)
print(resp.json()) #将服务器返回的类容直接处理成json- 豆瓣demo
https://movie.douban.com/j/chart/top_listtype=24&interval_id=100%3A90&action=&start=0&limit=20URL:找问号前面是url,之后是参数
https://movie.douban.com/j/chart/top_listtype=24&interval_id=100%3A90&action=&start=0&limit=20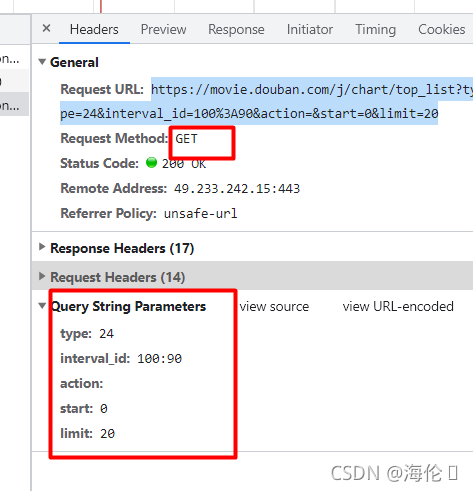
import requests
url = "https://movie.douban.com/j/chart/top_list"
param = {
"type": "24",
"interval_id": "100:90",
"action":"",
"start":1,
"limit":20,
}
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
resp = requests.get(url=url, params=param,headers=headers)
print(resp.status_code)
print(resp.text)
resp.close()记得关掉resp,否则容易出错。
5 re解析正则表达式
 https://tool.oschina.net/regex
https://tool.oschina.net/regex匹配方法:
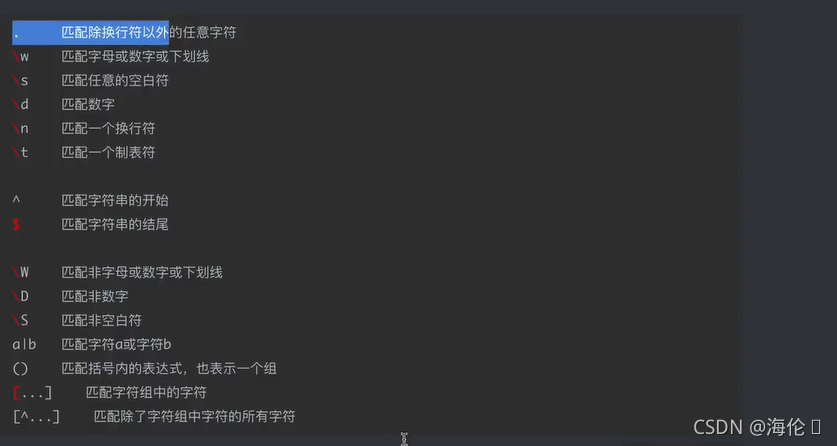

6 demo
代码:
#拿到页面源代码
#通过re提取想要的有效信息 re
import requests
import re
import csv
#url = "https://www.jd.hk/"
url = "https://movie.douban.com/top250"
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"
}
resp = requests.post(url= url,headers= headers)
page_context = resp.text
#print(resp.text)
resp.close()
#解析数据
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">'
r'.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">'
r'(?P<score>.*?)</span>.*?<span>(?P<num>.*?)人评价</span>',re.S)
result = obj.finditer(page_context)
f = open("data.csv", mode="w",encoding="utf-8")
csvwriter = csv.writer(f)
for it in result:
'''
print(it.group("name"))
print(it.group("year").strip())
print(it.group("score"))
print(it.group("num"))
'''
dic = it.groupdict()#字典
dic['year'] = dic['year'].strip()
csvwriter.writerow(dic.values())
f.close()
print("over!")
运行结果:
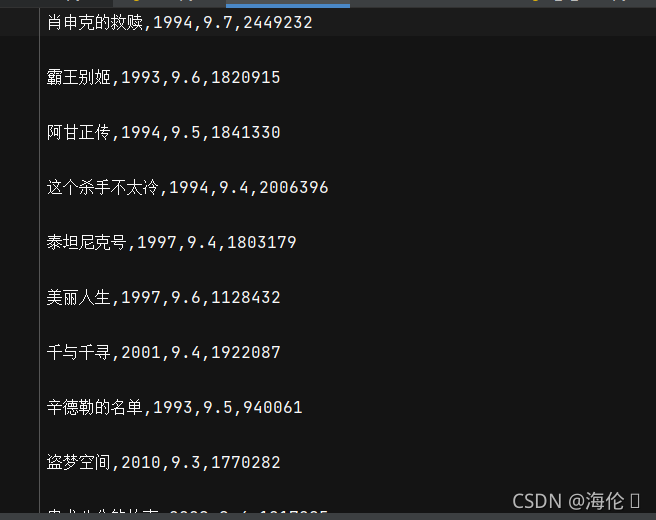

















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









