









城市名称数据清洗
有很多城市信息的脏数据如下:
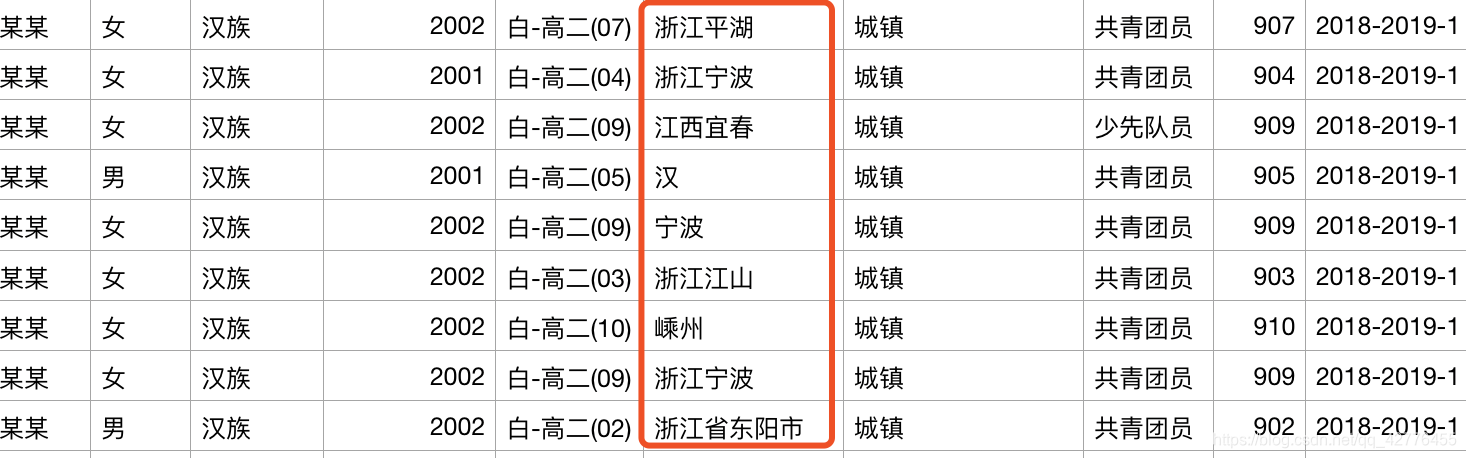
这里提供的思路是将这些数据放到某个地图网站上,自动匹配用爬虫的原理来实现数据清洗(这里保留空数据):
代码如下:
import re
import numpy as np
import pandas as pd
import requests,json
from pandas import DataFrame
def clean(dirty_city):
URL = 'http://lspengine.go2map.com/tips/tip'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'}
# 将中文转换为unicode编码
u_city = bytes(dirty_city,encoding='unicode_escape')
s_b_city = str(u_city)
s_u_li = s_b_city.split('\'')[1].split('\\\\')
str_city = ''
for s in s_u_li:
if s == '':
continue
else:
str_city = str_city + '%' + s
form = {
'key' : str_city,
'poiext': 'city,country',
}
response = requests.get(url=URL,params=form,headers=headers)
cityInfo_s = response.text
cityInfo_json = json.loads(cityInfo_s)
info = list(cityInfo_json['response']['results'])[0]
infoList = info.split(',')
#print(info)
if '省' in info:
return infoList[-2]+'-'+infoList[-1]
else:
return clean(infoList[-1]) +'-'+ infoList[-2]
if __name__ == '__main__':
data = pd.read_csv('/Users/hang/Desktop/education_data/2_student_info_2.csv')
# 脏的城市数据信息
dirty_cities = data.bf_NativePlace
id_s = data.bf_StudentID
for i in id_s:
cityName_series = data[data['bf_StudentID']==i].bf_NativePlace
city = cityName_series.tolist()[0]
print(city, i)
if type(city) == type(0.1):
continue
elif city == '汉族':
continue
elif city == '天津市':
continue
else:
try:
cleaned_city = clean(city)
data.loc[data['bf_StudentID']==i,' bf_NativePlace'] = cleaned_city
except:
continue
print(data)
data.to_csv('2_student_info_3.csv')
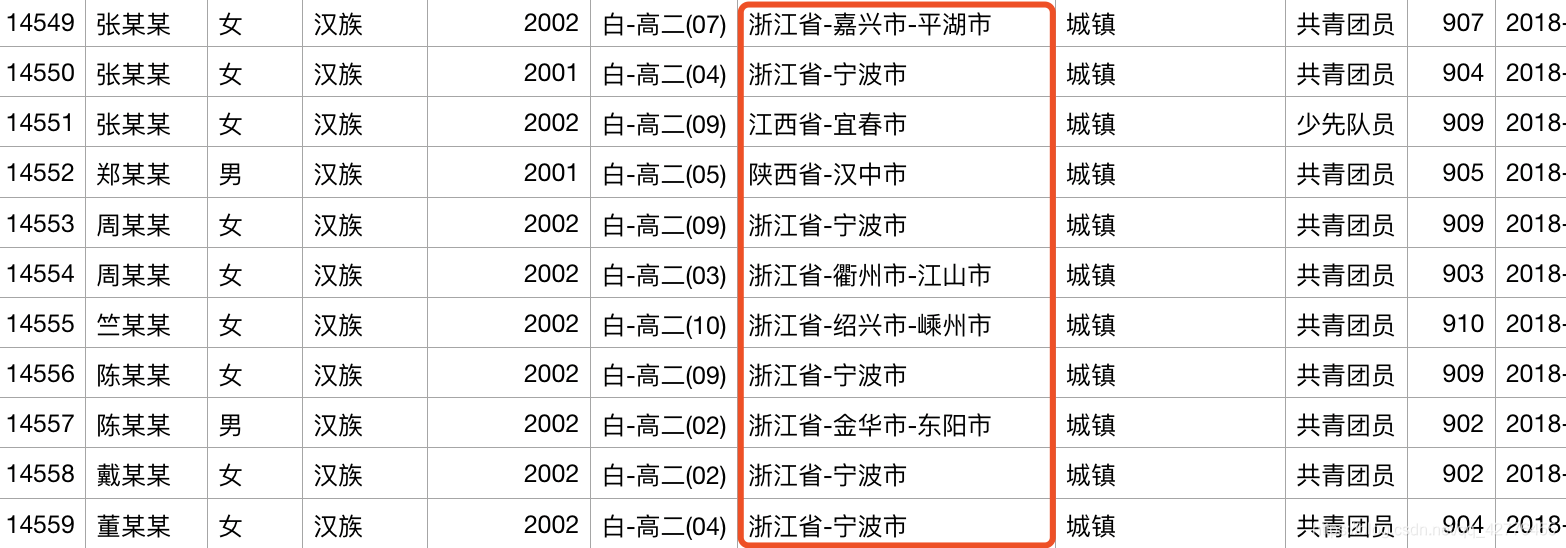
结果:

















 4731
4731

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









