







哨兵(sentinel)是Redis的高可用性(High Availability)的解决方案: 由一个或多个sentinel实例组成sentinel集群可以监视一个或多个主服务器和多个从服务器。 当主服务器进入下线状态时,sentinel可以将该主服务器下的某一从服务器升级为主服务器继续提供服务,从而保证redis的高可用性。
哨兵模式部署方案:
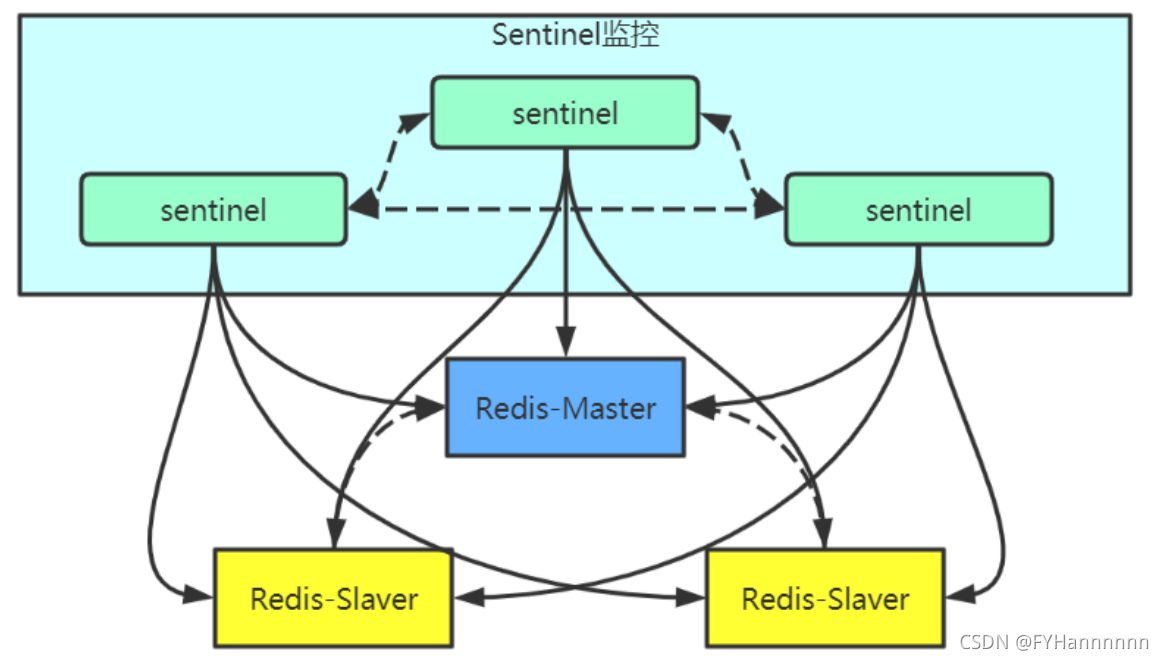
一,哨兵模式执行流程
1,启动并完成Sentinel初始化
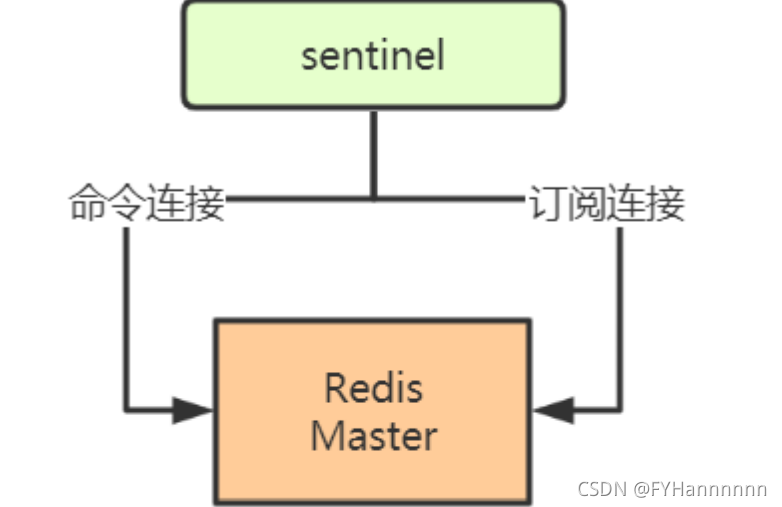
Sentinel是一个特殊的Redis服务器,不会进行持久化,Sentinel实例启动后,每个Sentinel会创建2个连向主服务器的网络连接 :
- 命令连接:用于向主服务器发送命令,并接收响应;
- 订阅连接:用于订阅主服务器的—sentinel—:hello频道。
2,获取主服务器信息
Sentinel默认每10s一次,向被监控的主服务器发送info命令,获取主服务器和其下属从服务器的信息。
3,获取从服务器信息
当Sentinel发现主服务器有新的从服务器出现时,Sentinel还会向从服务器建立命令连接和订阅连接。 在命令连接建立之后,Sentinel还是默认10s一次,向从服务器发送info命令,并记录从服务器的信息。
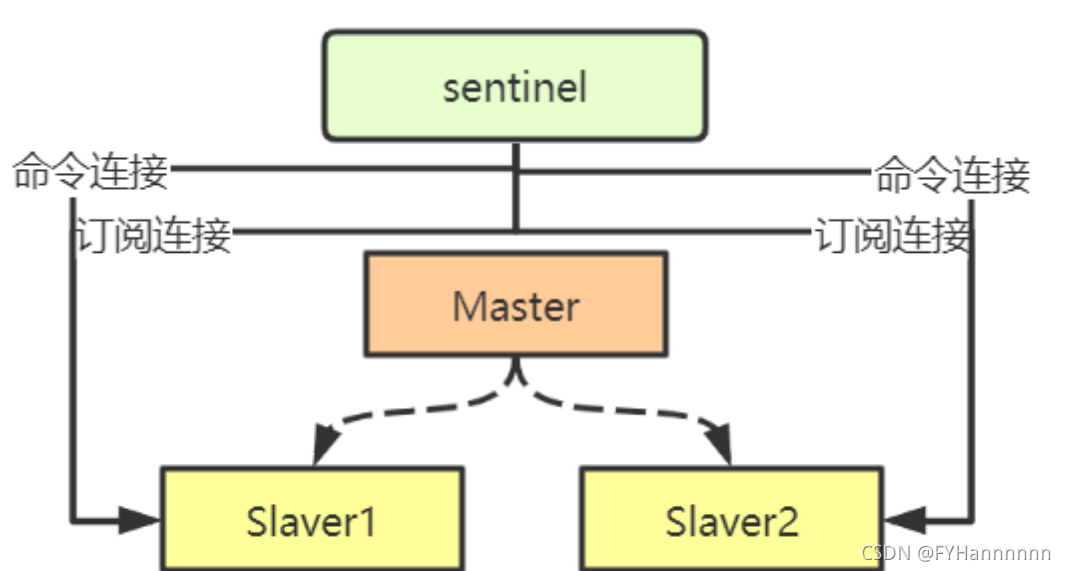
4,向主服务器和从服务器发送消息(以订阅的方式)
默认情况下,Sentinel每2s一次,向所有被监视的主服务器和从服务器所订阅的—sentinel—:hello频道上发送消息,消息中会携带Sentinel自身的信息和主服务器的信息。
PUBLISH _sentinel_:hello "< s_ip > < s_port >< s_runid >< s_epoch > < m_name > <
m_ip >< m_port ><m_epoch>"5,接收来自主服务器和从服务器的频道信息
当Sentinel与主服务器或者从服务器建立起订阅连接之后,Sentinel就会通过订阅连接,向服务器发送命令: subscribe —sentinel—:hello
(Sentinel彼此之间只创建命令连接,而不创建订阅连接,因为Sentinel通过订阅主服务器或从服务器, 就可以感知到新的Sentinel的加入,而一旦新Sentinel加入后,相互感知的Sentinel通过命令连接来通信就可以了。)
6,检测主观下线状态(Ping-Pong)
Sentinel每秒一次向所有与它建立了命令连接的实例(主服务器、从服务器和其他Sentinel)发送PING命令,实例在down-after-milliseconds毫秒内返回无效回复(除了+PONG、-LOADING、-MASTERDOWN外) 实例在down-after-milliseconds毫秒内无回复(超时) Sentinel就会认为该实例主观下线(SDown)
7,检查客观下线状态
当一个Sentinel将一个主服务器判断为主观下线后 Sentinel会向同时监控这个主服务器的所有其他Sentinel发送查询命令,判断它们是否也认为主服务器下线。如果达到Sentinel配置中的quorum数量的Sentinel实例都判断主服 务器为主观下线,则该主服务器就会被判定为客观下线(ODown)。【误判分析,一般为半数以上就判断下线】
8,选举Leader Sentinel
当一个主服务器被判定为客观下线后,监视这个主服务器的所有Sentinel会通过选举算法(raft),选出一个Leader Sentinel去执行failover(故障转移)操作。
二,哨兵模式Sentinel Leader的选举流程
Raft协议: Raft协议是用来解决分布式系统一致性问题的协议。 Raft协议描述的节点共有三种状态:Leader, Follower, Candidate。
任期term :Raft协议将时间切分为一个个的Term(任期),可以认为是一种“逻辑时间”。
1,Raft采用心跳机制触发Leader选举
触发选举之后,所有的Sentinel节点都变成Follower节点,且任期term皆为0.
2,节点之间的相互通信
节点之间会相互发送RequestVote或者AppendEntries消息,如果有节点接收到了RequestVote或者AppendEntries消息,就会保持自己的Follower身份。
节点如果一段时间内没收到AppendEntries,在该节点的超时时间内还没发现Leader,Follower就 会转换成Candidate,自己开始竞选Leader。
转变成Candidate,首先会对自己的任期term +1 ,然后启动一个新的定时器,给自己投票,然后像其他的所有的节点发送RequestVote消息等待他们的投票
如果在计时器超时前,节点收到多数节点的同意投票,就转换成Leader。同时向所有其他节点发送 AppendEntries,告知自己成为了Leader。
注意任期内的限制:每个节点在一个任期当中都只能投一次票,只能参与一次同意Leader的选票。
3,故障转移
选举出Sentinel Leader之后,它会将失效 Master 的其中一个 Slave 升级为新的 Master , 并让失效 Master 的其他 Slave 改为复制新的 Master ;
当客户端试图连接失效的 Master 时,集群也会向客户端返回新 Master 的地址,使得集群可以使 用现在的 Master 替换失效 Master 。
Master 和 Slave 服务器切换后, Master 的 redis.conf 、 Slave 的 redis.conf 和 sentinel.conf 的配置文件的内容都会发生相应的改变,即Master 主服务器的 redis.conf 配置文件中会多一行 replicaof 的配置, sentinel.conf 的监控目标会随之调换
4,关于主服务器的选择
- 1. 过滤掉主观下线的节点
- 2. 选择slave-priority最高的节点,如果由则返回没有就继续选择
- 3. 选择出复制偏移量最大的系节点,因为复制偏移量越大则数据复制的越完整,如果由就返回了,没 有就继续
- 4. 选择run_id最小的节点,因为run_id越小说明重启次数越少

















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









