









题目描述:96. 不同的二叉搜索树
给你一个整数
n
n
n ,求恰由
n
n
n 个节点组成且节点值从
1
1
1 到
n
n
n 互不相同的 二叉搜索树 有多少种?返回满足题意的二叉搜索树的种数。
示例 1:
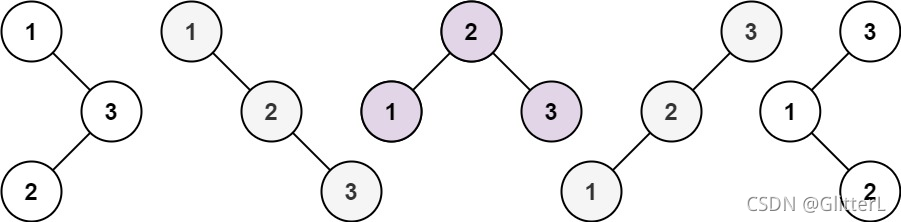
输入:n = 3
输出:5
示例 2:
输入:n = 1
输出:1
方法一:暴力求解
算法及思路
首先,我们要清楚二叉搜索树的性质:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;它的左、右子树也分别为二叉排序树。
因此,对于一个有序序列
1
⋅
⋅
⋅
n
1 ··· n
1⋅⋅⋅n,为了构建成一颗二叉搜索树,我们可以遍历每个数字
i
i
i,让
i
i
i 作为该子树的根结点,因此就有:
- 序列 1 ⋅ ⋅ ⋅ ( i − 1 ) 1 ··· ( i - 1 ) 1⋅⋅⋅(i−1) 作为其左子树;
- 序列 ( i + 1 ) ⋅ ⋅ ⋅ n ( i + 1 ) ··· n (i+1)⋅⋅⋅n 作为其右子树;
因此,利用暴力求解法,我们可以利用递归方法暴力求解:
- 我们定义一个函数 int buildTrees( int start, int end ),函数表示当前值的集合为 [ s t a r t , e n d ] [ start , end ] [start,end] ,返回序列 [ s t a r t , e n d ] [ start , end ] [start,end] 能够构成的所有二叉搜索子树的个数;
- 因此,以 i i i 为根结点,则将序列划分为了 [ s t a r t , i − 1 ] [ start , i - 1 ] [start,i−1] 和 [ i + 1 , e n d ] [ i + 1 , end ] [i+1,end]两部分,分别作为其左子树和右子树;
- 最后,我们需要明确,如果对于根结点 i i i ,其全部二叉搜索左子树的个数为 l e f t left left ,右子树的个数为 r i g h t right right ,那么,以结点 i 作为根结点的全部二叉搜索树的个数为 左子树序列和右子树序列的笛卡尔积,即 l e f t ∗ r i g h t left * right left∗right ;
举例而言,创建以 3 为根、长度为 7 的不同二叉搜索树,整个序列是
[
1
,
2
,
3
,
4
,
5
,
6
,
7
]
[ 1, 2, 3, 4, 5, 6, 7 ]
[1,2,3,4,5,6,7] ,我们需要从左子序列
[
1
,
2
]
[ 1, 2 ]
[1,2] 构建左子树,从右子序列
[
4
,
5
,
6
,
7
]
[ 4, 5, 6, 7 ]
[4,5,6,7] 构建右子树,然后将它们组合(即笛卡尔积)。
明确: 对于序列
[
4
,
5
,
6
,
7
]
[ 4, 5, 6, 7 ]
[4,5,6,7] 所构成二叉搜索树的所有序列的个数与
[
1
,
2
,
3
,
4
]
[ 1, 2, 3, 4 ]
[1,2,3,4] 所构成二叉搜索树的序列个数是相同的。
因此,在代码中为了方便起见,可以直接都转换为以 1 开头的序列(即
[
4
,
5
,
6
,
7
]
[ 4, 5, 6, 7 ]
[4,5,6,7] ->
[
1
,
2
,
3
,
4
]
[ 1, 2, 3, 4 ]
[1,2,3,4] )
代码:(时间复杂度高,会超时)
Java
class Solution {
public int numTrees(int n) {
int sum = 0;
for(int i = 1; i<=n; i++){
int left = buildTrees(1, i-1);
int right = buildTrees(i+1, n);
sum += (left * right);
}
return sum;
}
public int buildTrees(int l, int r){
if(l>r){
return 1;
}
for(int i = l; i<=r; i++){
int left = buildTrees(l,i-1);
int right = buildTrees(i+1,r);
sum += (left * right);
}
return sum;
}
}
再次分析:
其实,我们已经知道了:二叉搜索树序列的个数与其值无关,只与区间长度有关
我们观察官方给出的 示例1:
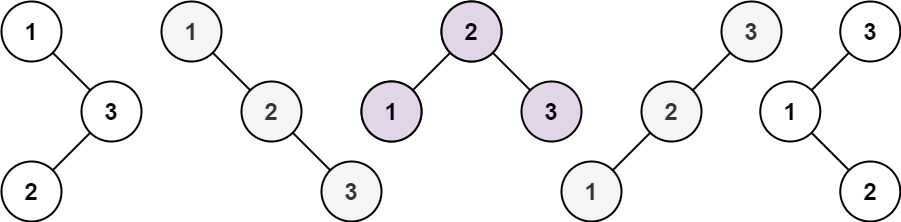
不难发现他们以中间标红的二叉搜索树 对称。说白了,就是,当我们以 i 为根结点,遍历序列
[
1
,
2
,
3
]
[ 1 , 2 , 3 ]
[1,2,3] 时以1作为根结点和以3作为根结点所得到的序列个数是相同的(只考虑个数)。
这是因为,对于根结点 1 而言,它的左子树序列长度为 0 ,右子树序列长度为 2。
对于根结点 3 而言,它的左子树序列长度为 2 ,右子树序列长度为 0。
同样, [ 1 , 2 , 3 , 4 , 5 ] [ 1 , 2 , 3 , 4 , 5 ] [1,2,3,4,5] 长度为奇数,是以 3 为对称轴 ; [ 1 , 2 , 3 , 4 ] [ 1 , 2 , 3 , 4 ] [1,2,3,4] 长度为偶数,是以 2 和 3 进行对称。
因此,我们可以对代码进行大幅度的改进:每次只需要计算前半序列的长度,然后乘以 2 并加上当序列长度为奇数时中间结点的序列个数即可(例如, [ 1 , 2 , 3 , 4 , 5 ] [ 1 , 2 , 3 , 4 , 5 ] [1,2,3,4,5] 我们只需要计算以 1 、 2 为根结点的序列的总个数 n u m num num,然后 n u m ∗ 2 num * 2 num∗2,再加上以 3 为根结点时的序列个数,就是最后的答案)。
时间复杂度就交给你们啦,O(∩_∩)O哈哈~
代码如下:
Java
class Solution {
public int numTrees(int n) {
int sum = 0;
int m;
m = n/2;
for(int i = 1; i<=m; i++){
int left = buildTrees(1, i-1);
int right = buildTrees(i+1, n);
sum += (left * right);
}
sum = sum * 2;
if(n % 2 == 1){
int left = buildTrees(1,n/2);
int right = buildTrees(n/2 + 2 , n);
sum += (left * right);
}
return sum;
}
public int buildTrees(int l, int r){
if(l>r){
return 1;
}
r = r - l + 1;
l = 1;
int sum = 0;
int m = r/2;
for(int i = l; i<=m; i++){
int left = buildTrees(l,i-1);
int right = buildTrees(i+1,r);
sum += (left * right);
}
sum = sum * 2;
if(r % 2 == 1){
int left = buildTrees(l,r/2);
int right = buildTrees(r/2 + 2 , r);
sum += (left * right);
}
return sum;
}
}
方法二:动态规划
算法及思路
明确:二叉搜索树序列的个数与其值无关,只与区间长度有关
其实我们通过方法一不难看出:我们每次都是从头开始计算序列长度为 n 时所包含的二叉搜索树的序列个数,但是没有利用到之前已经计算过的信息。
例如:我们在计算序列长度为 4 4 4 的二叉搜索树时 [ 1 , 2 , 3 , 4 ] [ 1 , 2 , 3 , 4 ] [1,2,3,4],假设以 1 作为根结点,则左子树序列长度为 0 0 0 ,右子树序列长度为 3 3 3 ,而我们之前就已经计算过 序列长度为 3 3 3 的总个数了,没有必要再算一次,且当前状态受上一个状态的影响,因此我们就可以从这里入手,进行下一步优化——动态规划。
定义两个函数:
- G ( n ) G ( n ) G(n):长度为 n 的序列能构成的不同二叉搜索树的个数
- F ( i , n ) F ( i , n ) F(i,n):以 i 为根、序列长度为 n 的不同二叉搜索树的个数 ( 1 ≤ i ≤ n ) ( 1 ≤ i ≤ n) (1≤i≤n)。
首先,根据方法一的思路可以知道,对于不同的二叉搜索树的总数 G ( n ) G ( n ) G(n) ,是所有 F ( i , n ) F ( i , n ) F(i,n) 之和:
G ( n ) = ∑ i = 0 n F ( i , n ) G(n) = \displaystyle \sum^{n}_{i=0}{F(i,n)} G(n)=i=0∑nF(i,n)
对于边界情况,当序列长度为$ 1 $( 只有根 ) 或为 0 0 0 ( 空树 ) 时,只有一种情况,即:
G ( 0 ) = 1 , G ( 1 ) = 1 G(0) = 1,G(1) = 1 G(0)=1,G(1)=1
举例而言,创建以 3 为根、长度为 7 的不同二叉搜索树,整个序列是 [ 1 , 2 , 3 , 4 , 5 , 6 , 7 ] [1, 2, 3, 4, 5, 6, 7] [1,2,3,4,5,6,7],我们需要从左子序列 [ 1 , 2 ] [1, 2] [1,2] 构建左子树,从右子序列 [ 4 , 5 , 6 , 7 ] [4, 5, 6, 7] [4,5,6,7] 构建右子树,然后将它们组合(即笛卡尔积)。
对于这个例子,不同二叉搜索树的个数为 F ( 3 , 7 ) F(3, 7) F(3,7)。我们将 [ 1 , 2 ] [1,2] [1,2] 构建不同左子树的数量表示为 G ( 2 ) G(2) G(2), 从 [ 4 , 5 , 6 , 7 ] [4, 5, 6, 7] [4,5,6,7] 构建不同右子树的数量表示为 G ( 4 ) G(4) G(4),注意到 G ( n ) G(n) G(n) 和序列的内容无关,只和序列的长度有关。于是, F ( 3 , 7 ) = G ( 2 ) ⋅ G ( 4 ) F(3,7) = G(2) \cdot G(4) F(3,7)=G(2)⋅G(4)。 因此,我们可以得到以下公式:
F ( i , n ) = G ( i − 1 ) ⋅ G ( n − i ) F(i,n) = G(i-1) \cdot G(n-i) F(i,n)=G(i−1)⋅G(n−i)
因此,结合上述公式可以得出递归表达式:
G ( n ) = ∑ i = 1 n G ( i − 1 ) ⋅ G ( n − i ) G(n) = \displaystyle \sum^{n}_{i=1}{G(i-1) \cdot G(n-i)} G(n)=i=1∑nG(i−1)⋅G(n−i)
于是,我们可以从小到大计算 G G G函数,
代码:
C++
class Solution {
public:
int numTrees(int n) {
vector<int> G(n + 1, 0);
G[0] = 1;
G[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j <= i; ++j) {
G[i] += G[j - 1] * G[i - j];
}
}
return G[n];
}
};
Java
class Solution {
public int numTrees(int n) {
int[] G = new int[n + 1];
G[0] = 1;
G[1] = 1;
for (int i = 2; i <= n; ++i) {
for (int j = 1; j <= i; ++j) {
G[i] += G[j - 1] * G[i - j];
}
}
return G[n];
}
}
Python
class Solution:
def numTrees(self, n):
"""
:type n: int
:rtype: int
"""
G = [0]*(n+1)
G[0], G[1] = 1, 1
for i in range(2, n+1):
for j in range(1, i+1):
G[i] += G[j-1] * G[i-j]
return G[n]
以上就是所有的内容了,当然还有一种通过数学进行求解的方法,感觉对于大多数人来说不是很友好,O(∩_∩)O哈哈~


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











