



点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
转自 | 我爱计算机视觉
在人工智能领域,常常面临一个两难选择:一边是像LLaVA这样知识渊博、具有强大通用语义理解能力的大型视觉-语言模型(VLM),但它们体型庞大、运行缓慢且成本高昂;另一边是像YOLO这样轻量、高效、速度飞快的专才型目标检测器,但它们缺乏深度的语义理解能力,尤其是在小样本学习场景下表现不佳。
如何让轻量的“学生”(YOLO)学会重量级“教授”(LLaVA)的智慧,同时又保持其轻便的身材?来自三星英国研究院和帕多瓦大学的研究者们在一篇名为 《MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment》 的论文中,给出了一个漂亮的答案。他们提出了一种名为 MOCHA 的新型知识蒸馏方法,成功地将大型VLM中丰富的、区域级的多模态语义知识,迁移到了一个轻量级的、纯视觉的目标检测器中,在几乎不增加推理成本的前提下,让后者在少样本个性化检测任务上的性能平均提升了 +10.1 分。

论文标题:MOCHA: Multi-modal Objects-aware Cross-arcHitecture Alignment
作者团队:Elena Camuffo, Francesco Barbato, Mete Ozay, Simone Milani, Umberto Michieli
机构:三星英国研究院 (Samsung R&D Institute UK), 帕多瓦大学 (University of Padova)
论文地址:https://arxiv.org/abs/2509.14001
背景:轻量化部署的“最后一公里”
在许多真实世界的应用场景,尤其是在手机等资源受限的设备上,希望模型能够快速识别一些个性化的物体,比如“我的猫”、“我的水杯”等。这就是“少样本个性化检测”任务。这类任务需要模型具备强大的语义理解能力,而这正是大型VLM的强项。但直接在手机上部署一个几十亿参数的VLM显然是不现实的。
因此,知识蒸馏(Knowledge Distillation)技术成为了解决这一问题的关键:在“云端”用一个强大的教师模型(Teacher)去“教”一个轻量级的学生模型(Student),训练完成后,只需在“终端”部署这个轻便但聪明的学生模型。MOCHA正是为此设计的一种高效的跨架构知识蒸馏方案。
MOCHA的“三步配方”
MOCHA的整个流程可以概括为一个三步走的“配方”:
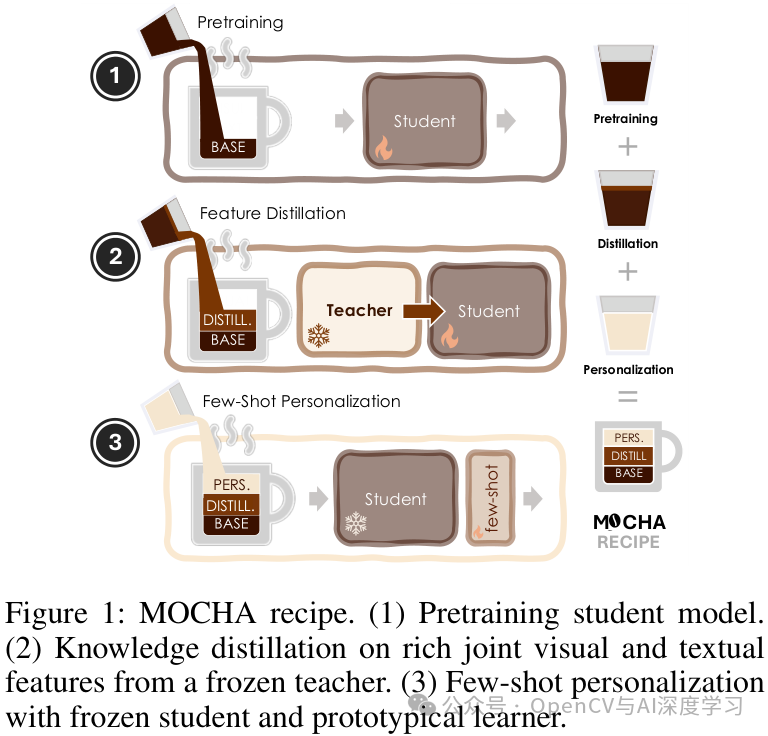
预训练学生模型:首先,在COCO等大规模通用数据集上训练一个标准的YOLO模型,使其具备基础的目标检测能力。
知识蒸馏:这是MOCHA的核心。在这一阶段,用一个冻结的、强大的VLM(如LLaVA)作为教师,将其知识“蒸馏”给YOLO学生模型。
少样本个性化:蒸馏完成后,学生模型的主干网络也被冻结。当用户需要识别新物体时,只需提供1-5个样本,就能快速训练一个极轻量的原型学习器(prototypical learner),实现高效的个性化检测。
MOCHA知识蒸馏的核心机制
与以往的知识蒸馏方法不同,MOCHA有两大创新点:
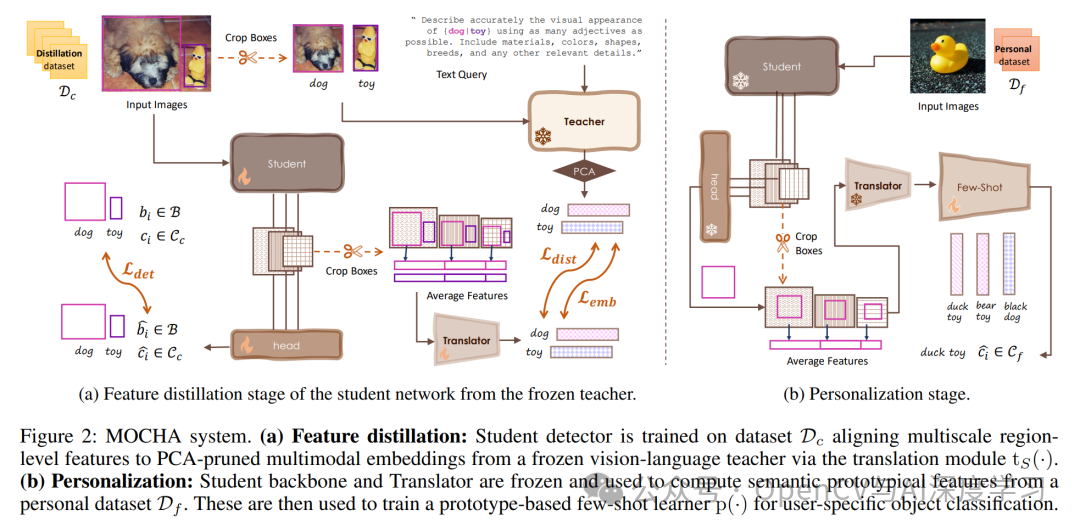
对象级别的多模态语义传递:传统方法通常进行全局或密集的特征对齐,而MOCHA则在“对象级别”进行操作。对于图像中的每一个物体,它利用VLM强大的图文理解能力,生成一个融合了视觉和文本语义的丰富特征向量。这个特征向量就是学生需要学习的“知识精华”。
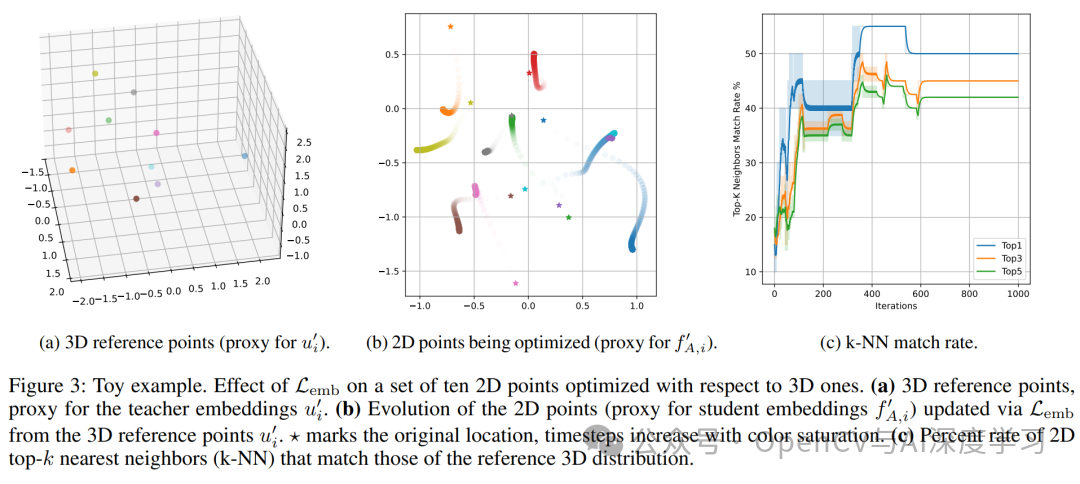
双目标损失函数:为了让学生(YOLO)的特征能有效对齐教师的特征,MOCHA设计了一个“翻译模块”(Translation Module)将学生特征映射到与教师特征相同的联合空间中,并使用了一个双目标损失函数来指导训练:
局部对齐损失 (Local Alignment Loss) :确保对于同一个物体,学生转换后的特征与教师的特征尽可能接近。
全局关系一致性损失 (Global Relational Consistency Loss) :不仅要学得像,还要学到“关系”。该损失确保学生特征空间中不同物体间的相对关系(如“猫”和“狗”的特征距离)与教师空间中的保持一致。这有助于学生学习到一个结构良好、语义可分的特征空间。
最关键的是,整个过程 无需修改教师模型,并且在最终的推理阶段,学生模型是一个 纯视觉模型,完全不需要文本输入,保证了其高效性。
实验结果:轻量模型堪比重量级
研究者在四个个性化检测基准上,对MOCHA在少样本(1-shot和5-shot)设置下的性能进行了验证。
显著的性能提升:实验结果表明,经过MOCHA蒸馏后的YOLO模型,相比于没有经过蒸馏的基线YOLO,性能有巨大提升。在所有数据集和设置下,平均分提升达到了 +10.1。
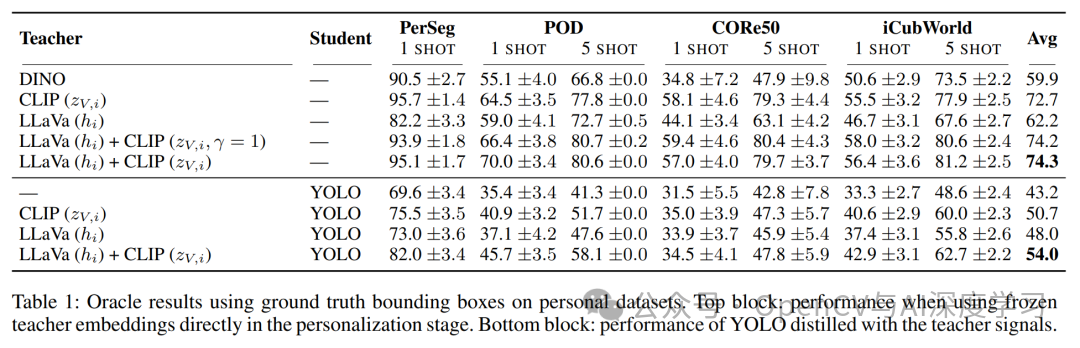
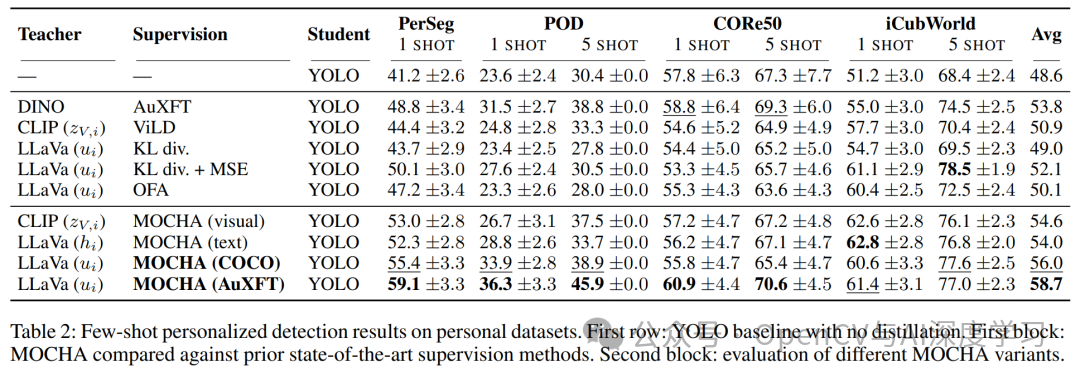
媲美大型模型:尽管MOCHA的学生模型架构紧凑(YOLOv8n),但其性能却能达到甚至超越那些直接使用大型多模态模型(如CLIP, DINOv2)进行检测的方法,展示了其卓越的效率和实用性。
定性结果:从可视化结果可以看出,在仅有1-5个样本的情况下,基线YOLO模型常常发生错检或漏检,而经过MOCHA蒸馏的模型则能更准确地定位和识别出个性化的新物体。

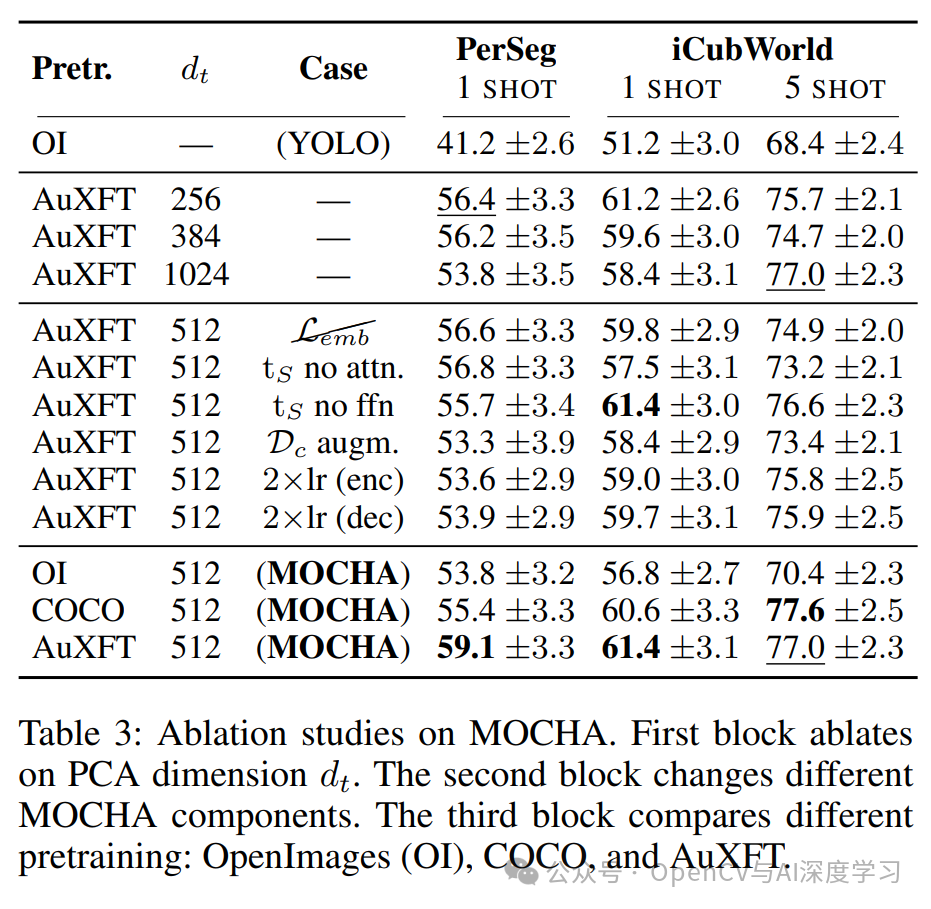
消融实验也证明了MOCHA中各个组件,如双目标损失函数、PCA降维等,都对最终的性能至关重要。
总结与展望
MOCHA的提出,为如何将大型预训练模型的强大语义能力“注入”到轻量级模型中提供了一种高效且实用的新范式。它通过对象级的跨架构知识蒸馏,成功地让一个纯视觉的轻量检测器具备了多模态的“智慧”,同时保持了推理时的高效率和低成本。
这项工作证明,不必总是在“大而全”和“小而快”之间做痛苦的抉择。通过像MOCHA这样的知识蒸馏技术,可以两全其美,为在资源受限的设备上部署更智能、更个性化的AI应用开辟了广阔的前景。
本文仅做学术分享,如有侵权,请联系删文。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:人工智能0基础学习攻略手册
在「小白学视觉」公众号后台回复:攻略手册,即可获取《从 0 入门人工智能学习攻略手册》文档,包含视频课件、习题、电子书、代码、数据等人工智能学习相关资源,可以下载离线学习。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

















 1345
1345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









