




 本文通过李宏毅老师的讲解,深入浅出地介绍了机器学习中偏差与方差的概念及其对模型性能的影响。文章探讨了简单模型与复杂模型的偏差与方差特性,并提出了在实际应用中如何平衡二者的方法。
本文通过李宏毅老师的讲解,深入浅出地介绍了机器学习中偏差与方差的概念及其对模型性能的影响。文章探讨了简单模型与复杂模型的偏差与方差特性,并提出了在实际应用中如何平衡二者的方法。
李宏毅机器学习Day03之误差
参与了datawhale组队学习,李宏毅老师机器学习课程学习打卡
课程资料:https://www.bilibili.com/video/BV1Ht411g7Ef?p=1&vd_source=618ecf41cffc71dcd77f42f4c37554fe
课程笔记资料:https://linklearner.com/datawhale-homepage/#/learn/detail/93
李宏毅老师将bias和variance这块讲的太好了,用射箭的例子理解生动又形象(对比学校的相关课程,简直一个字绝)
误差从哪里来
参考:含公式推导 https://segmentfault.com/a/1190000016447144
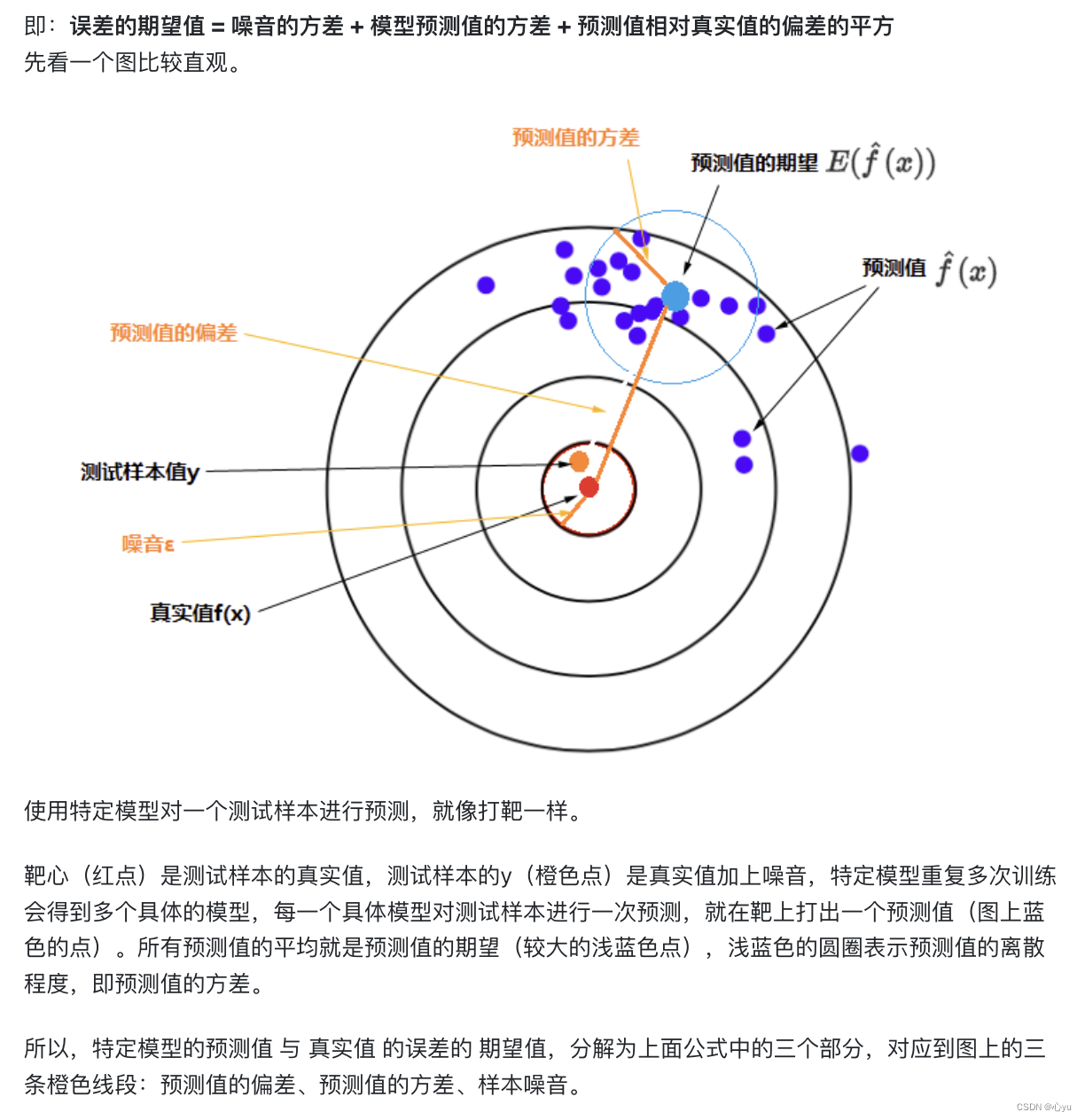

下面考虑变量x的主要来源:偏差和方差
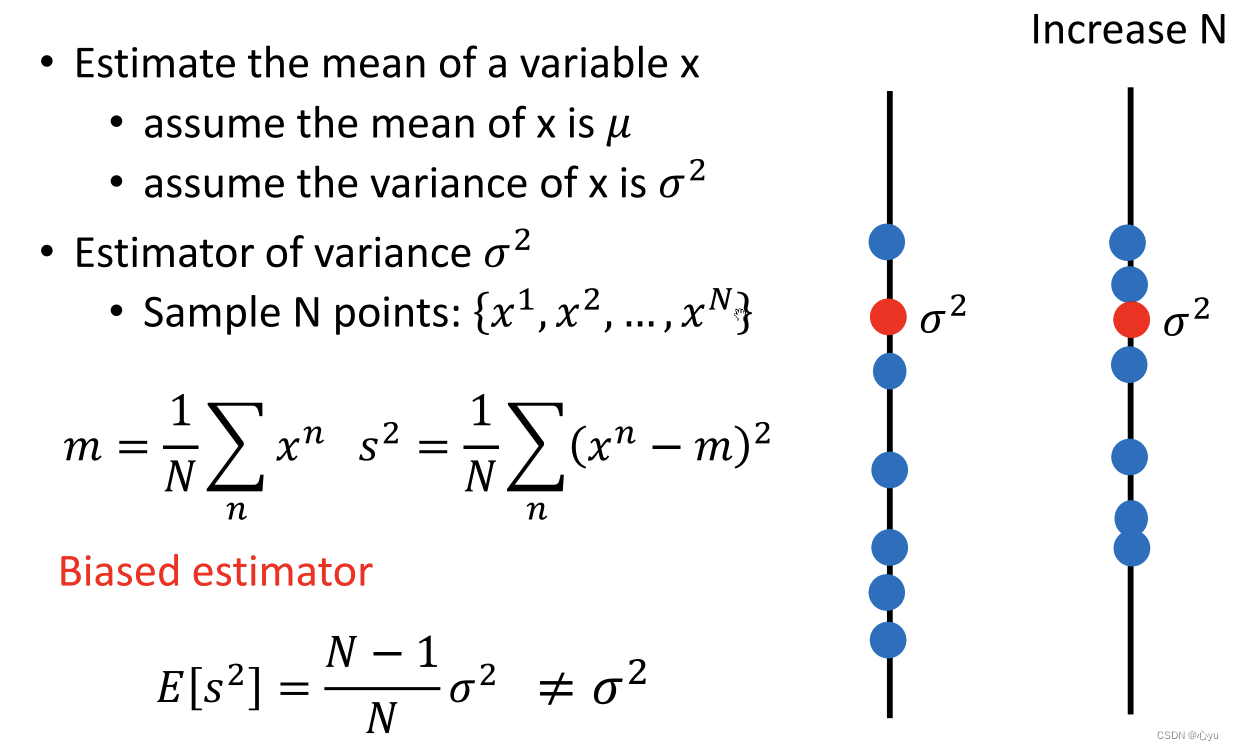
评估变量x的偏差

评估变量x的方差
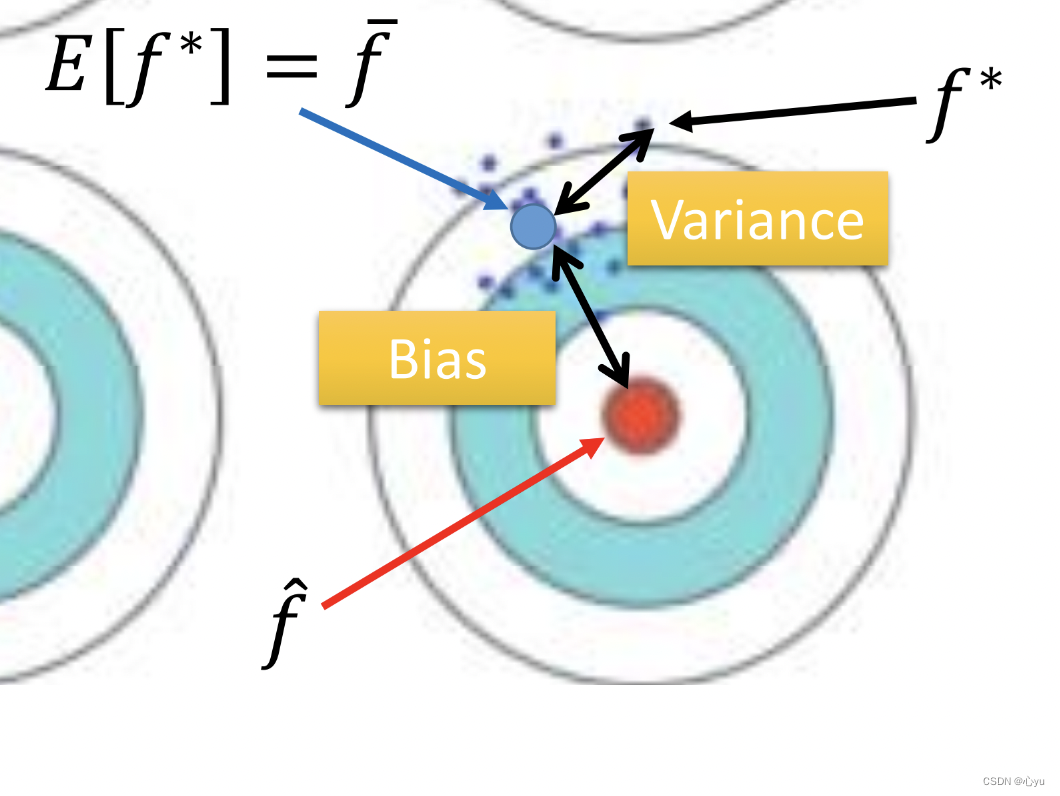
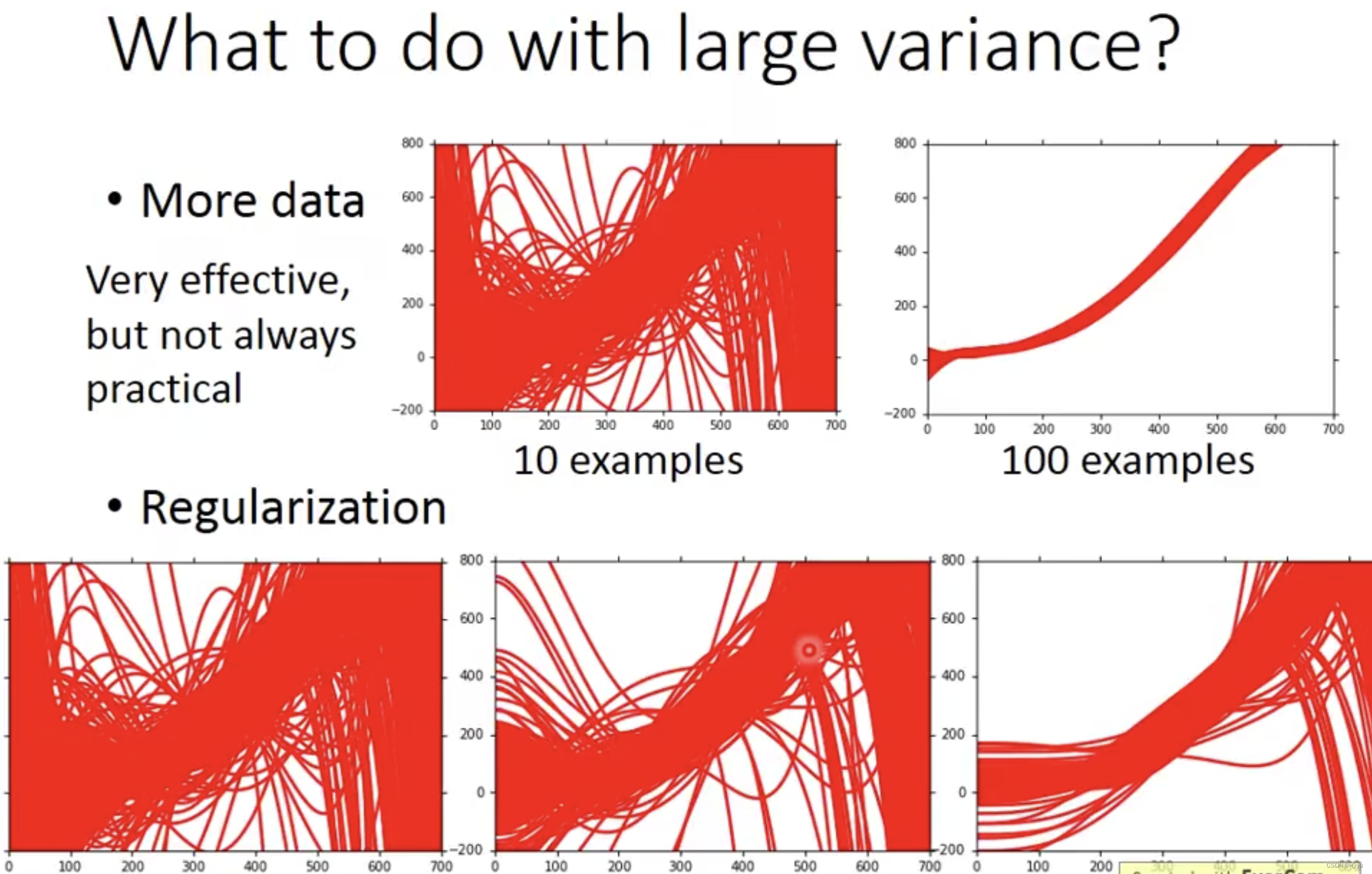
为什么会有很多模型?
用同一个model,在不同的训练集中找到的f*就是不一样的
不同模型的方差
一次模型的方差就比较小的,也就是是比较集中,离散程度较小。而5次模型的方差就比较大,同理散布比较广,离散程度较大。
所以用比较简单的模型,方差是比较小的(就像射击的时候每次的时候,每次射击的设置都集中在一个比较小的区域内)。如果用了复杂的模型,方差就很大,散布比较开。
这也是因为简单的模型受到不同训练集的影响是比较小的。
不同模型的偏差

偏差与方差
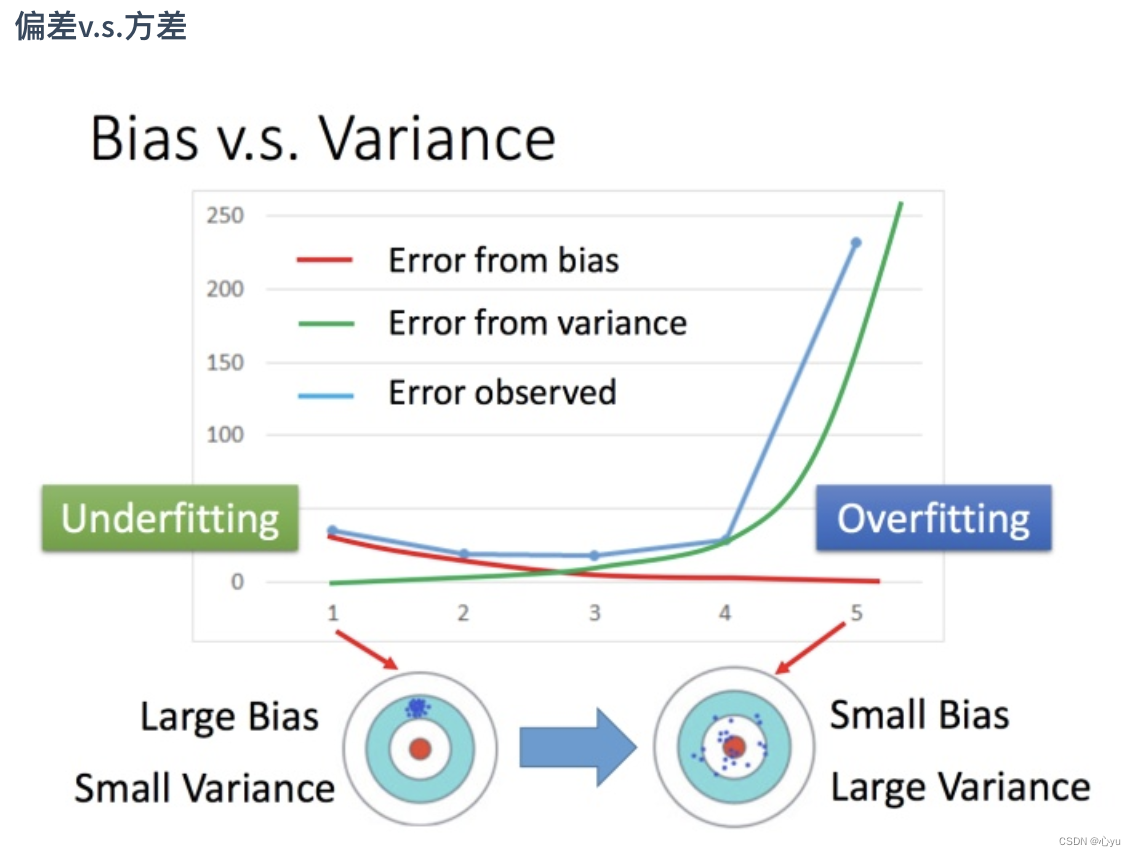
overfitting: 偏差较小,方差较大
underfitting: 偏差较大,方差较小
解决方案:tradeoff between bias and varience
偏差太大:

方差太大:
模型选择
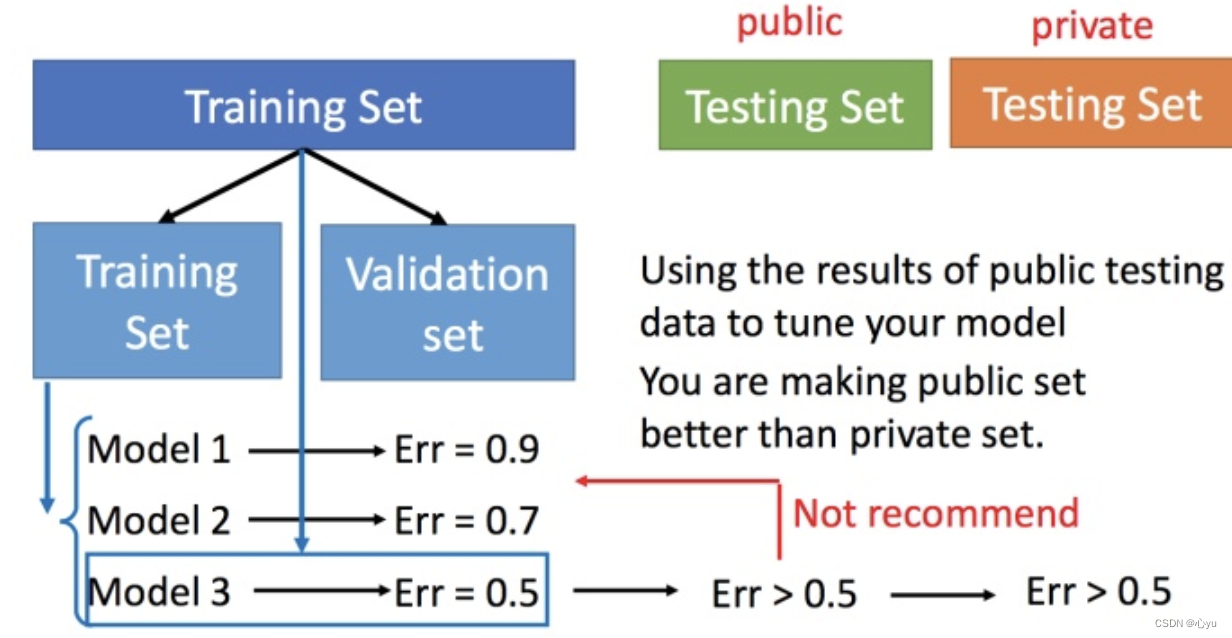
现在在偏差和方差之间就需要一个权衡 想选择的模型,可以平衡偏差和方差产生的错误,使得总错误最小 但是下面这件事最好不要做:

用训练集训练不同的模型,然后在测试集上比较错误,模型3的错误比较小,就认为模型3好。但实际上这只是你手上的测试集,真正完整的测试集并没有。比如在已有的测试集上错误是0.5,但有条件收集到更多的测试集后通常得到的错误都是大于0.5的。
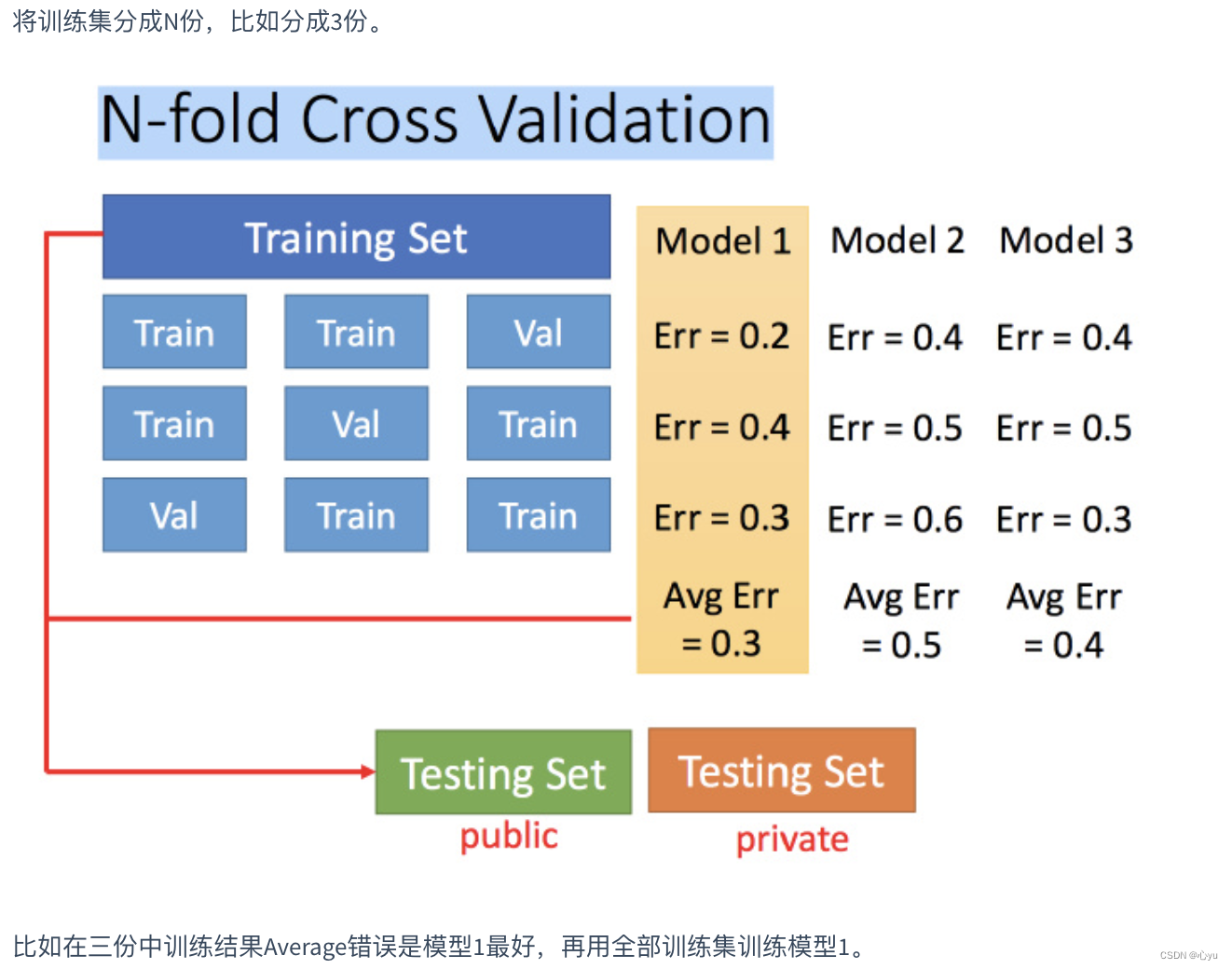
交叉验证
图中public的测试集是已有的,private是没有的,不知道的。交叉验证 就是将训练集再分为两部分,一部分作为训练集,一部分作为验证集。用训练集训练模型,然后再验证集上比较,确实出最好的模型之后(比如模型3),再用全部的训练集训练模型3,然后再用public的测试集进行测试,此时一般得到的错误都是大一些的。不过此时会比较想再回去调一下参数,调整模型,让在public的测试集上更好,但不太推荐这样。
上述方法可能会担心将训练集拆分的时候分的效果比较差怎么办,可以用N折交叉验证


















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











