







 本文深入介绍了Hadoop MapReduce的架构、运行流程及核心组件,包括MapTask和ReduceTask的工作职责。MapReduce运算分为Map和Reduce两个阶段,数据以键值对形式流转。WordCount案例展示了MapReduce的基本使用,通过Mapper和Reducer实现单词计数。Map阶段对输入数据进行切割并输出<单词,1>,Reduce阶段则对相同单词的1进行求和,输出最终的单词计数。Map阶段包括数据切割、解析、映射和分区排序,Reduce阶段涉及数据复制、合并排序和聚合处理。
本文深入介绍了Hadoop MapReduce的架构、运行流程及核心组件,包括MapTask和ReduceTask的工作职责。MapReduce运算分为Map和Reduce两个阶段,数据以键值对形式流转。WordCount案例展示了MapReduce的基本使用,通过Mapper和Reducer实现单词计数。Map阶段对输入数据进行切割并输出<单词,1>,Reduce阶段则对相同单词的1进行求和,输出最终的单词计数。Map阶段包括数据切割、解析、映射和分区排序,Reduce阶段涉及数据复制、合并排序和聚合处理。
Hadoop MapReduce是一个软件框架
用于轻松编写应用程序,这些应用程序以可靠,容错的方式并行处理大型硬件集群(数千个节点)上的大量数据(多TB数据集)。
对于·我们要学习的知识有:
MapReduce架构体系
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster:负责整个程序的过程调度及状态协调
2、MapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
MapReduce的运算
MapReduce分布式的运算程序需要分成2个阶段,分别是Map阶段和Reduce阶段。Map阶段对应的是MapTask并发实例,完全并行运行。Reduce阶段对应的是ReduceTask并发实例,数据依赖于上一个阶段所有MapTask并发实例的数据输出结果。
用户编写的程序分成三个部分:Mapper,Reducer,Driver(提交运行mr程序的客户端驱动)。
用户自定义的Mapper和Reducer都要继承各自的父类。Mapper中的业务逻辑写在map()方法中,Reducer的业务逻辑写在reduce()方法中。整个程序需要一个Driver来进行提交,提交的是一个描述了各种必要信息的job对象。
最需要注意的是:整个MapReduce程序中,数据都是以kv键值对的形式流转的。
MapReduce工作流程可以分为3个阶段
map、shuffle、reduce。
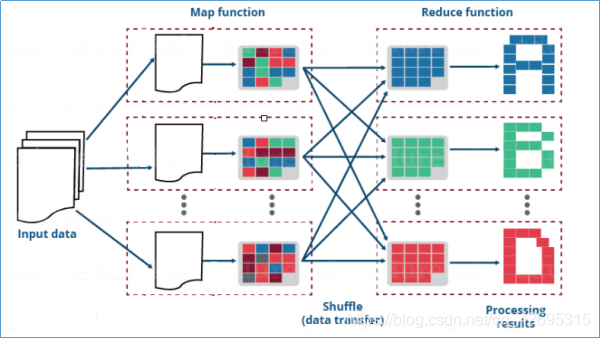
map阶段:
负责把从数据源读取来到数据进行处理,默认情况下读取数据返回的是kv键值对类型,经过自定义map方法处理之后,输出的也应该是kv键值对类型。
shuffle阶段:
map输出的数据会经过分区、排序、分组等自带动作进行重组,相当于洗牌的逆过程。这是MapReduce的核心所在,也是难点所在。也是值得我们深入探究的所在。
默认分区规则:key相同的分在同一个分区,同一个分区被同一个reduce处理。
默认排序规则:根据key字典序排序
默认分组规则:key相同的分为一组,一组调用reduce处理一次。
reduce阶段:
负责针对shuffle好的数据进行聚合处理。输出的结果也应该是kv键值对。
MapReduce入门案例WordCount
MapReduce的WordCount编程思路
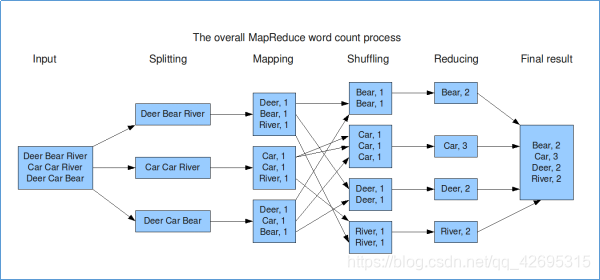
map阶段的核心:把输入的数据经过切割,全部标记1。因此输出就是<单词,1>。
shuffle阶段核心:经过默认的排序分区分组,key相同的单词会作为一组数据构成新的kv对。
reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是该单词的总次数。最终输出<单词,总次数>。
Mapper类编写
public class WordCountMapper extends Mapper<LongWritable, Text,Text,LongWritable> {
//Mapper输出kv键值对 <单词,1>
private Text keyOut = new Text();
private final static LongWritable valueOut = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将读取的一行内容根据分隔符进行切割
String[] words = value.toString().split("\\s+");
//遍历单词数组
for (String word : words) {
keyOut.set(word);
//输出单词,并标记1
context.write(new Text(word),valueOut);
}
}
}
Reducer类编写
public class WordCountReducer extends Reducer<Text, LongWritable,Text,LongWritable> {
private LongWritable result = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//统计变量
long count = 0;
//遍历一组数据,取出该组所有的value
for (LongWritable value : values) {
//所有的value累加 就是该单词的总次数
count +=value.get();
}
result.set(count);
//输出最终结果<单词,总次数>
context.write(key,result);
}
}
直接构建作业启动
public class WordCountDriver_v1 {
public static void main(String[] args) throws Exception {
//配置文件对象
Configuration conf = new Configuration();
// 创建作业实例
Job job = Job.getInstance(conf, WordCountDriver_v1.class.getSimpleName());
// 设置作业驱动类
job.setJarByClass(WordCountDriver_v1.class);
// 设置作业mapper reducer类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 设置作业mapper阶段输出key value数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置作业reducer阶段输出key value数据类型 也就是程序最终输出数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// 配置作业的输入数据路径
FileInputFormat.addInputPath(job, new Path(args[0]));
// 配置作业的输出数据路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//判断输出路径是否存在 如果存在删除
FileSystem fs = FileSystem.get(conf);
if(fs.exists(new Path(args[1]))){
fs.delete(new Path(args[1]),true);
}
// 提交作业并等待执行完成
boolean resultFlag = job.waitForCompletion(true);
//程序退出
System.exit(resultFlag ? 0 :1);
}
}
Map阶段执行过程
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下,Split size = Block size。每一个切片由一个MapTask处理。(getSplits)
第二阶段是对切片中的数据按照一定的规则解析成<key,value>对。默认规则是把每一行文本内容解析成键值对。key是每一行的起始位置(单位是字节),value是本行的文本内容。(TextInputFormat)
第三阶段是调用Mapper类中的map方法。上阶段中每解析出来的一个<k,v>,调用一次map方法。每次调用map方法会输出零个或多个键值对。
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是Reducer任务运行的数量。默认只有一个Reducer任务。
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中。
第六阶段是对数据进行局部聚合处理,也就是combiner处理。键相等的键值对会调用一次reduce方法。经过这一阶段,数据量会减少。本阶段默认是没有的。
Redue阶段执行过程
第一阶段是Reducer任务会主动从Mapper任务复制其输出的键值对。Mapper任务可能会有很多,因此Reducer会复制多个Mapper的输出。
第二阶段是把复制到Reducer本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到HDFS文件中。

















 1095
1095

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









