




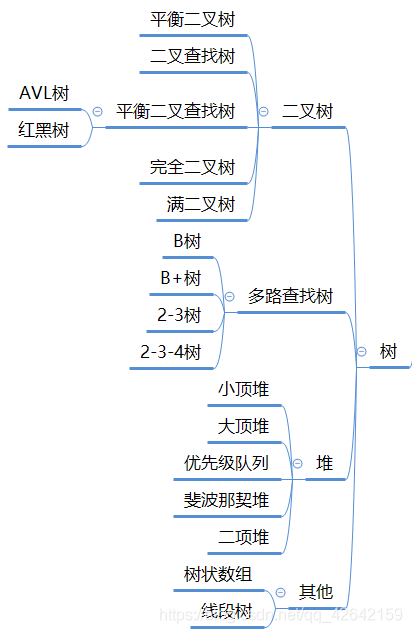
 本文详细讲解了树的基础概念,特别是二叉树的分类(如二叉查找树、完全二叉树、红黑树),存储方法(链式与顺序),遍历算法(前序、中序、后序),以及红黑树的特性、插入删除操作和在工程实践中的重要性。重点介绍了平衡二叉查找树,尤其是红黑树的定义、维护平衡的方法和应用实例。
本文详细讲解了树的基础概念,特别是二叉树的分类(如二叉查找树、完全二叉树、红黑树),存储方法(链式与顺序),遍历算法(前序、中序、后序),以及红黑树的特性、插入删除操作和在工程实践中的重要性。重点介绍了平衡二叉查找树,尤其是红黑树的定义、维护平衡的方法和应用实例。
一、什么是树
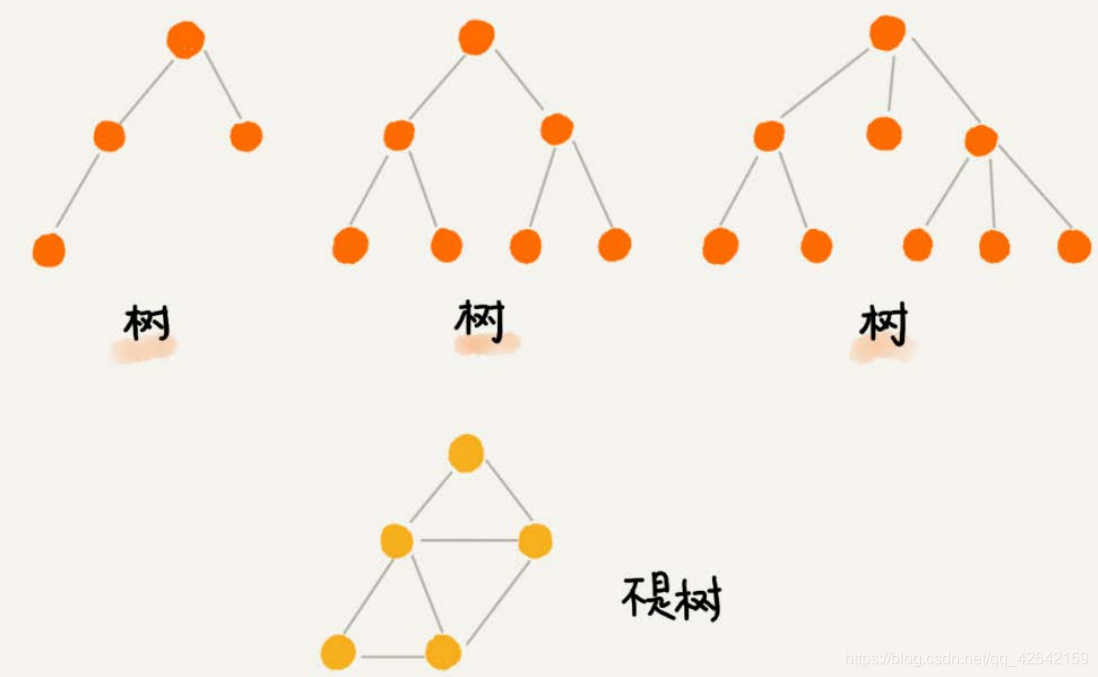
树是一种重要的非线性数据结构,直观地看,它是数据元素(在树中称为结点)按分支关系组织起来的结构,很象自然界中的树那样。
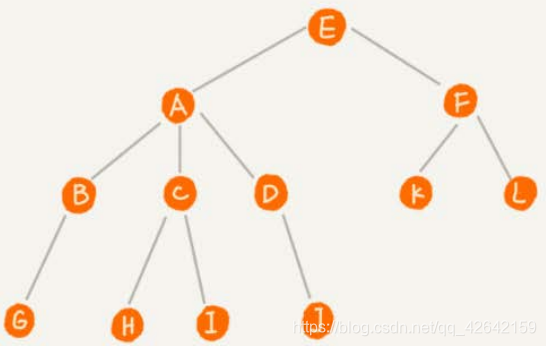
这里面每个元素我们叫作 “ 节点 ” ;用来连线相邻节点之间的关系,我们叫作 “ 父子关系 ” 。A节点就是B节点的父节点,B节点是A节点的子节点。B、C、D这三个节点的父节点是同一个节点,所以它们之间互称为兄弟节点。我们把没有父节点的节点叫作根节点,也就是图中的节点E。我们把没有子节点的节点叫作叶子节点或者叶节点,比如图中的G、H、I、J、K、L都是叶子节点。
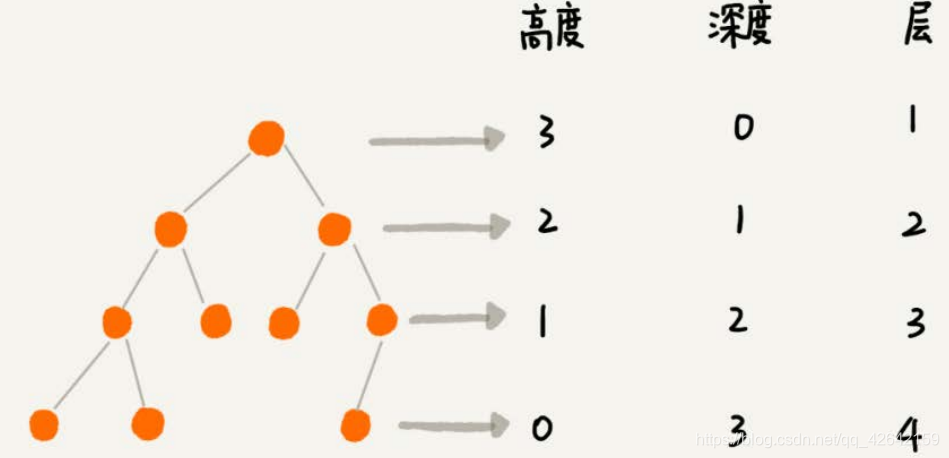
除此之外,关于“树”,还有三个比较相似的概念:高度(Height)、深度(Depth)、层(Level)。它们的定义是这样的:

二、二叉树( Binary Tree )
二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只有左子节点,有的节点只有右子节点。

编号2的二叉树中,叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫作满二叉树。
编号3的二叉树中,叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫作完全二叉树。

(若设二叉树的深度为k,除第 k 层外,其它各层 (1~k-1) 的结点数都达到最大个数,第k 层所有的结点都连续集中在最左边,这就是完全二叉树。)
三、存储一棵二叉树
一种是基于指针或者引用的二叉链式存储法,一种是基于数组的顺序存储法。
3.1 链式存储法
从图中你应该可以很清楚地看到,每个节点有三个字段,其中一个存储数据,另外两个是指向左右子节点的指针。我们只要拎住根节点,就可以通过左右子节点的指针,把整棵树都串起来。这种存储方式我们比较常用。大部分二叉树代码都是通过这种结构来实现的。
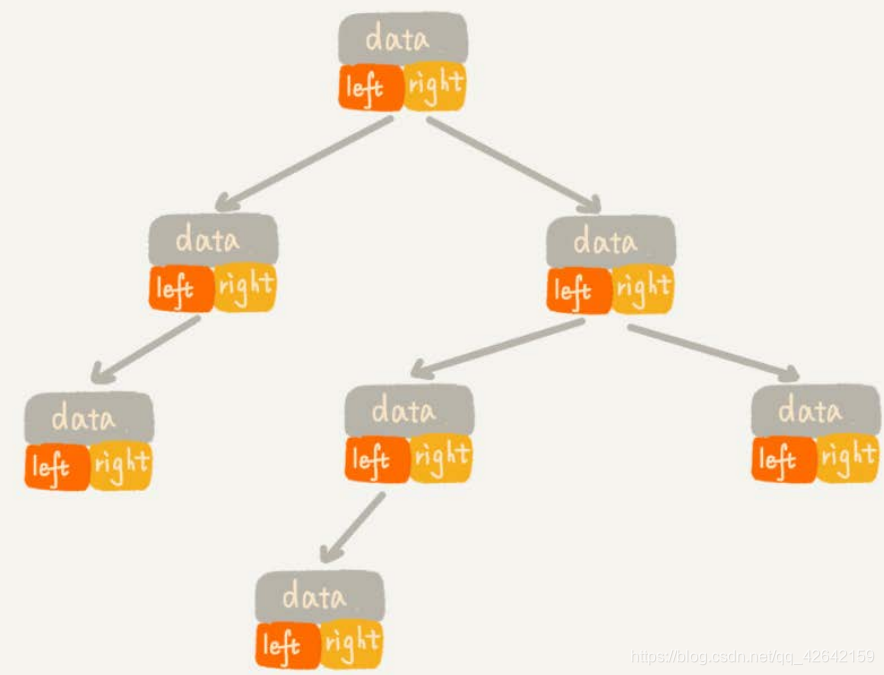
3.2 数组的顺序存储法。
我们把根节点存储在下标i = 1的位置,那左子节点存储在下标2 * i = 2的位置,右子节点存储在2 * i + 1 = 3的位置。以此类推, B 节点的左子节点存储在 2 * i = 2 * 2 = 4 的位置,右子节点存储在 2 * i + 1 = 2 * 2 + 1 = 5 的位置。
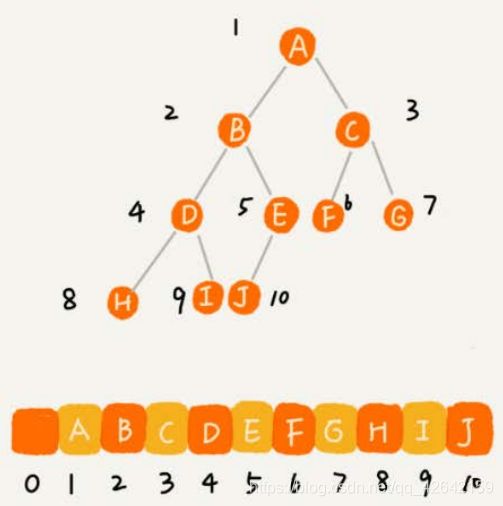
如果节点 X 存储在数组中下标为 i 的位置,下标为 2 * i 的位置存储的就是左子节点,下标为 2 * i + 1 的位置存储的就是右子节点。反过来,下标为 i/2 的位置存储就是它的父节点。通过这种方式,我们只要知道根节点存储的位置(一般情况下,为了方便计算子节点,根节点会存储在下标为 1 的位置),这样就可以通过下标计算,把整棵树都串起来。
不过,我刚刚举的例子是一棵完全二叉树,所以仅仅 “ 浪费 ” 了一个下标为 0 的存储位置。如果是非完全二叉树,其实会浪费比较多的数组存储空间。你可以看我举的下面这个例子。
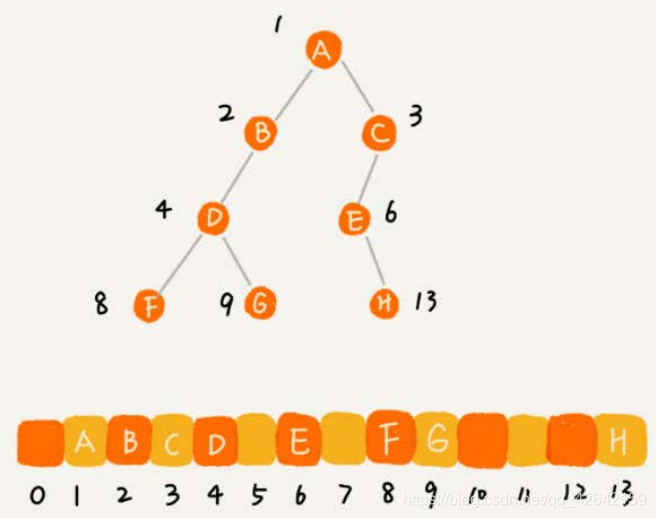
所以,如果某棵二叉树是一棵完全二叉树,那用数组存储无疑是最节省内存的一种方式。因为数组的存储方式并不需要像链式存储法那样,要存储额外的左右子节点的指针。这也是为什么完全二叉树会单独拎出来的原因,也是为什么完全二叉树要求最后一层的子节点都靠左的原因。
当我们讲到堆和堆排序的时候,你会发现,堆其实就是一种完全二叉树,最常用的存储方式就是数组。
四、二叉树的遍历
前序遍历、中序遍历和后序遍历。其中,前、中、后序,表示的是节点与它的左右子树节点遍历打印的先后顺序。
4.1 前序遍历
前序遍历是指,对于树中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树。
4.2 中序遍历
中序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它本身,最后打印它的右子树。
4.3 后序遍历
后序遍历是指,对于树中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点本身
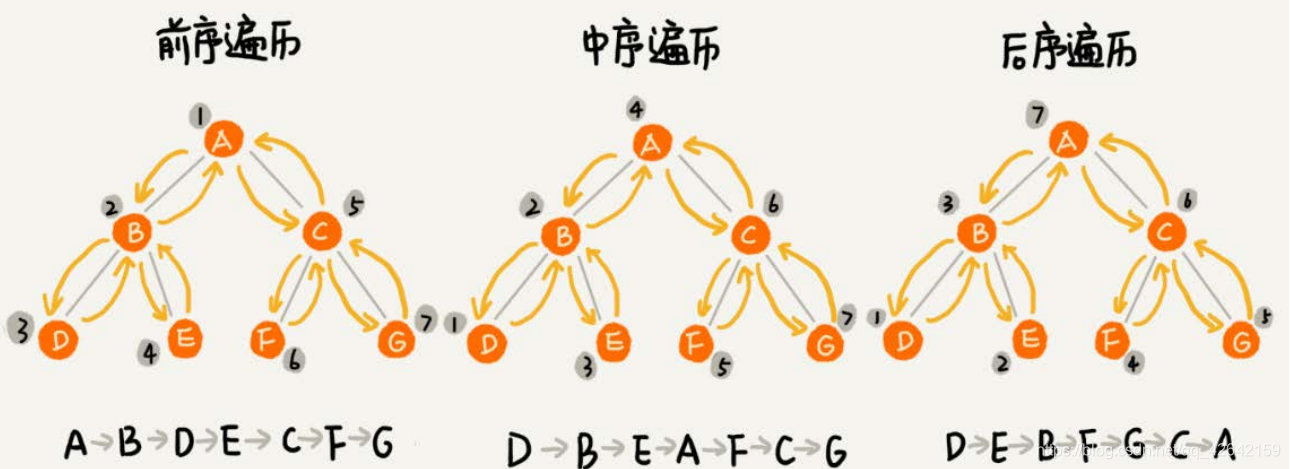
实际上,二叉树的前、中、后序遍历就是一个递归的过程。比如,前序遍历,其实就是先打印根节点,然后再递归地打印左子树,最后递归地打印右子树。
写递归代码的关键,就是看能不能写出递推公式,而写递推公式的关键就是,如果要解决问题 A ,就假设子问题 B 、 C 已经解决,然后再来看如何利用 B 、 C 来解
决 A 。所以,我们可以把前、中、后序遍历的递推公式都写出来。
前序遍历的递推公式:
preOrder® = print r->preOrder(r->left)->preOrder(r->right)
中序遍历的递推公式:
inOrder® = inOrder(r->left)->print r->inOrder(r->right)
后序遍历的递推公式:
postOrder® = postOrder(r->left)->postOrder(r->right)->printr
代码归档:https://gitee.com/qq127827/concurrent-project
五、二叉查找树O(logn)
支持动态数据集合的快速插入、删除、查找操作。
二叉查找树是二叉树中最常用的一种类型,也叫二叉搜索树。二叉查找树要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都大于这个节点的值。
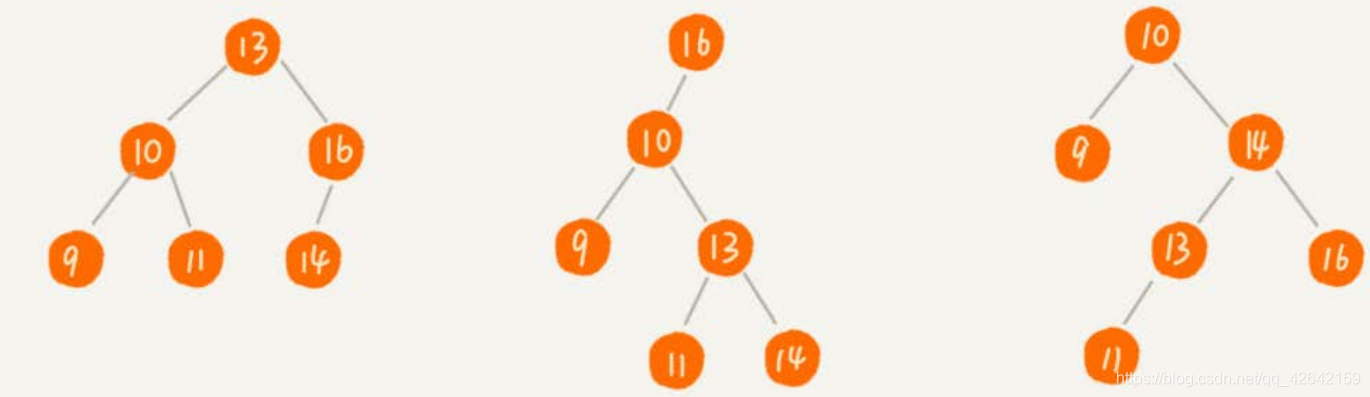
二叉查找树的查找、插入操作都比较简单易懂,但是它的删除操作就比较复杂了 。针对要删除节点的子节点个数的不同,我们需要分三种情况来处理。
第一种情况是,如果要删除的节点没有子节点,我们只需要直接将父节点中,指向要删除节点的指针置为 null 。比如图中的删除节点 55 。
第二种情况是,如果要删除的节点只有一个子节点(只有左子节点或者右子节点),我们只需要更新父节点中,指向要删除节点的指针,让它指向要删除节点的子节点就可以了。比如图中的删除节点 13 。
第三种情况是,如果要删除的节点有两个子节点,这就比较复杂了。我们需要找到这个节点的右子树中的最小节点,把它替换到要删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了),所以,我们可以应用上面两条规则来删除这个最小节点。比如图中的删除节点 18 。
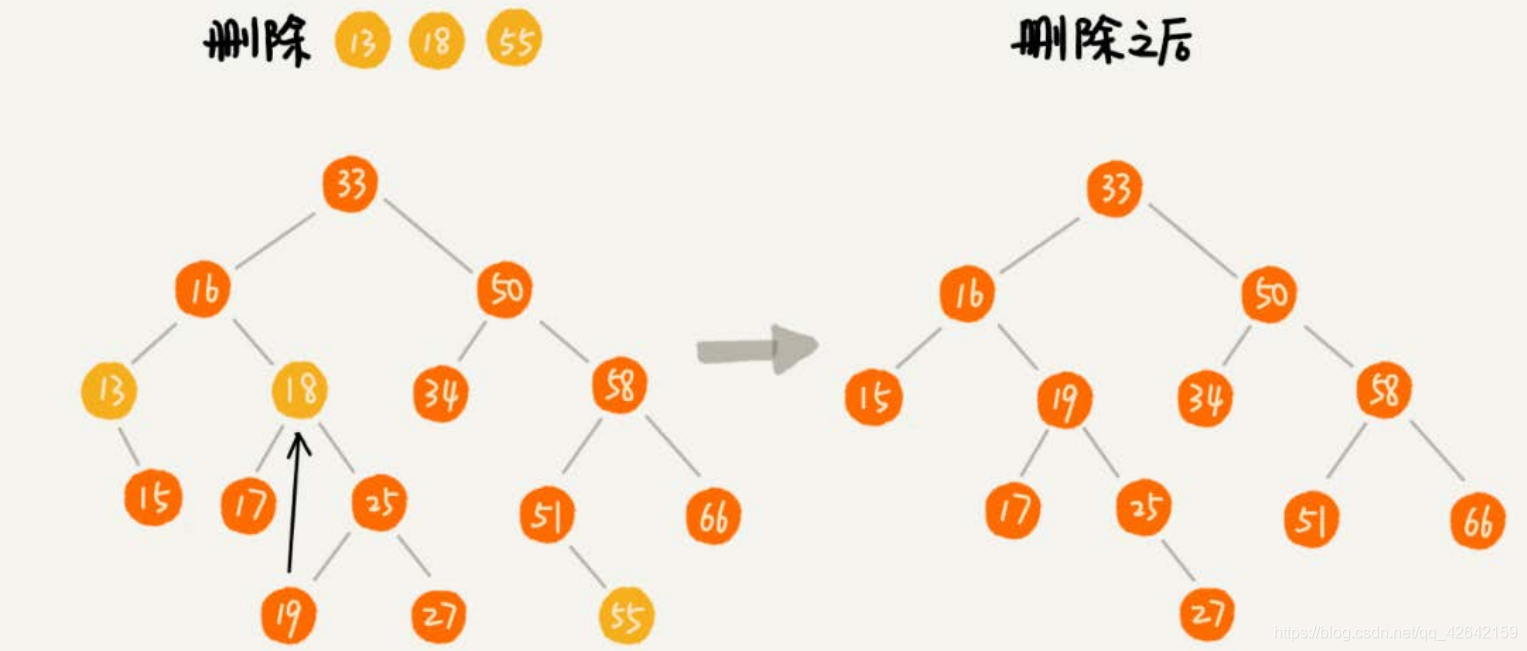
六、红黑树
二叉查找树是最常用的一种二叉树,它支持快速插入、删除、查找操作,各个操作的时间复杂度跟树的高度成正比,理想情况下,时间复杂度是 O(logn)
不过,二叉查找树在频繁的动态更新过程中,可能会出现树的高度远大于log 2 n的情况,从而导致各个操作的效率下降。极端情况下,二叉树会退化为链表,时间复杂度会退化到 O(n) 。我上一节说了,要解决这个复杂度退化的问题,我们需要设计一种平衡二叉查找树,也就是今天要讲的这种数据结构。
很多书籍里,但凡讲到平衡二叉查找树,就会拿红黑树作为例子。不仅如此,如果你有一定的开发经验,你会发现,在工程中,很多用到平衡二叉查找树的地方都会用红黑树。你有没有想过,为什么工程中都喜欢用红黑树,而不是其他平衡二叉查找树呢
6.1 什么是 “ 平衡二叉查找树 ” ?
二叉树中任意一个节点的左右子树的高度相差不能大于 1 。从这个定义来看,上一节我们讲的完全二叉树、满二叉树其实都是平
衡二叉树,但是非完全二叉树也有可能是平衡二叉树。
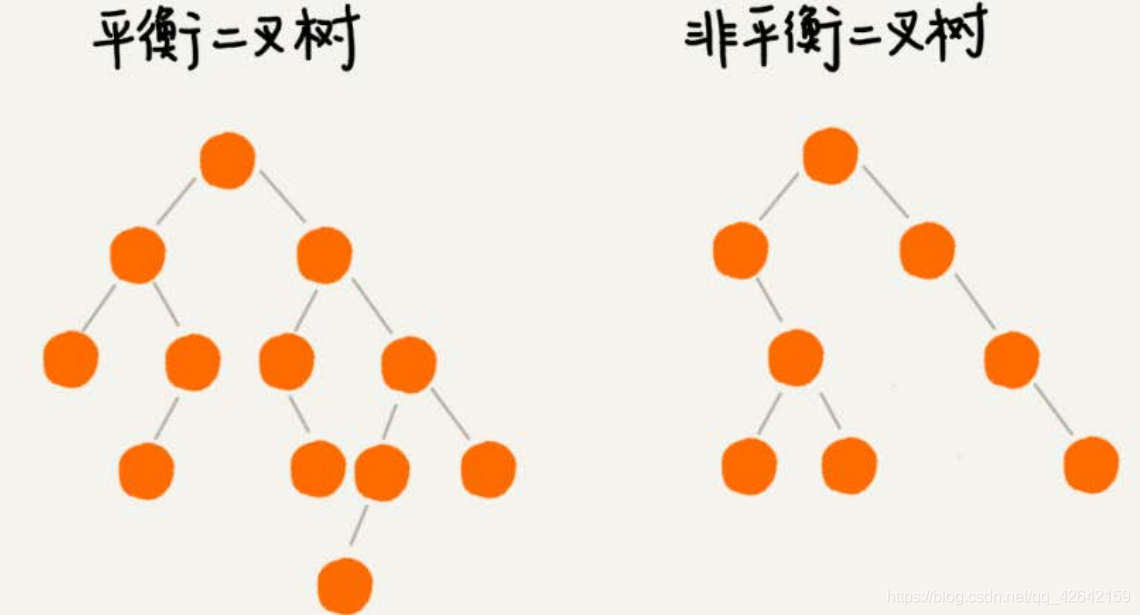
平衡二叉查找树不仅满足上面平衡二叉树的定义,还满足二叉查找树的特点。最先被发明的平衡二叉查找树是AVL树,它严格符合我刚讲到的平衡二叉查找树的定义,即任何节点的左右子树高度相差不超过 1 ,是一种高度平衡的二叉查找树。
但是很多平衡二叉查找树其实并没有严格符合上面的定义(树中任意一个节点的左右子树的高度相差不能大于 1 ),比如我们下面要讲的红黑树,它从根节点到各个叶子节点的最长路径,有可能会比最短路径大一倍。
我们学习数据结构和算法是为了应用到实际的开发中的,所以,我觉得没必去死抠定义。对于平衡二叉查找树这个概念,我觉得我们要从这个数据结构的由来,去理解 “ 平衡 ” 的意思。发明平衡二叉查找树这类数据结构的初衷是,解决普通二叉查找树在频繁的插入、删除等动态更新的情况下,出现时间复杂度退化的问题。
所以,平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。所以,如果我们现在设计一个新的平衡二叉查找树,只要树的高度不比log 2 n大很多(比如树的高度仍然是对数量级的),尽管它不符合我们前面讲的严格的平衡二叉查找树的定义,但我们仍然可以说,这是一个合格的平衡二叉查找树。
6.2 如何定义一棵 “ 红黑树 ” ?
平衡二叉查找树其实有很多,比如, Splay Tree (伸展树)、 Treap (树堆)等,但是我们提到平衡二叉查找树,听到的基本都是红黑树。它的出镜率甚至要高于 “ 平衡二叉查找树 ” 这几个字,有时候,我们甚至默认平衡二叉查找树就是红黑树,那我们现在就来看看这个 “ 明星树 ” 。
红黑树中的节点,一类被标记为黑色,一类被标记为红色。除此之外,一棵红黑树还需要满足这样几个要求:
- 根节点是黑色的;
- 每个叶子节点都是黑色的空节点(NIL),也就是说,叶子节点不存储数据;
- 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的;(两个节点连接起来,称为相邻节点)
- 每个节点,从该节点到达其可达叶子节点的所有路径,都包含相同数目的黑色节点
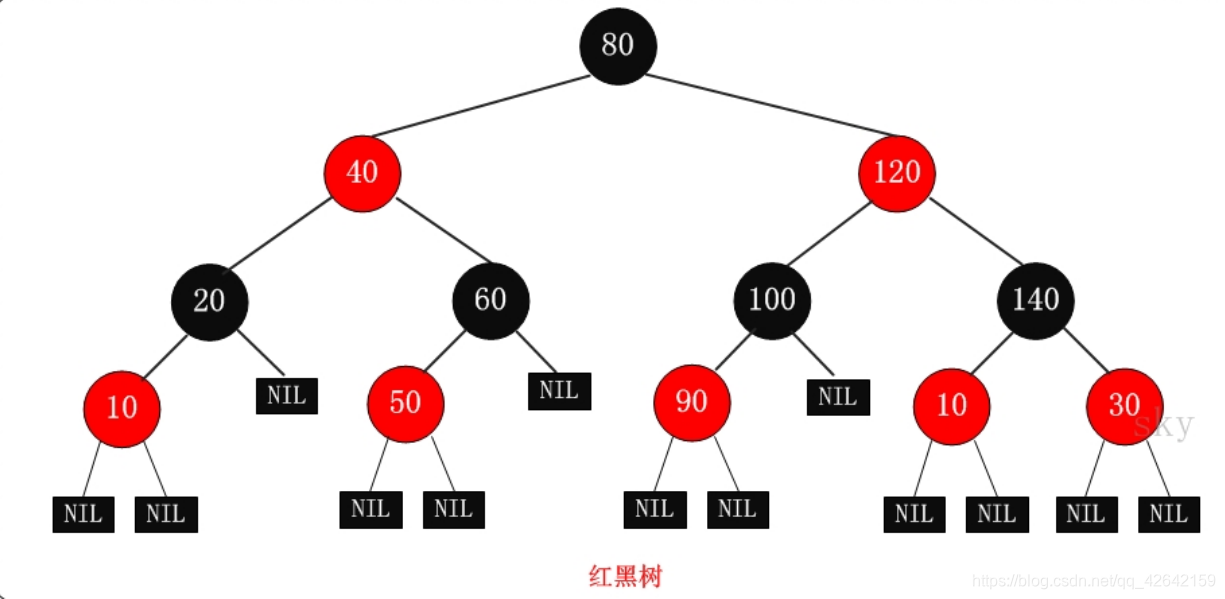
红黑树的增删改查节点后,需要通过左旋和右旋保持红黑树的特性。(https://www.cnblogs.com/skywang12345/p/3245399.html)
七、递归树
我们前面讲过,递归的思想就是,将大问题分解为小问题来求解,然后再将小问题分解为小小问题。这样一层一层地分解,直到问题的数据规模被分解得足够小,不用继续递归分解为止。
如果我们把这个一层一层的分解过程画成图,它其实就是一棵树。我们给这棵树起一个名字,叫作递归树。我这里画了一棵斐波那契数列的递归树,你可以看看。节点里的数字表示数据的规模,一个节点的求解可以分解为左右子节点两个问题的求解。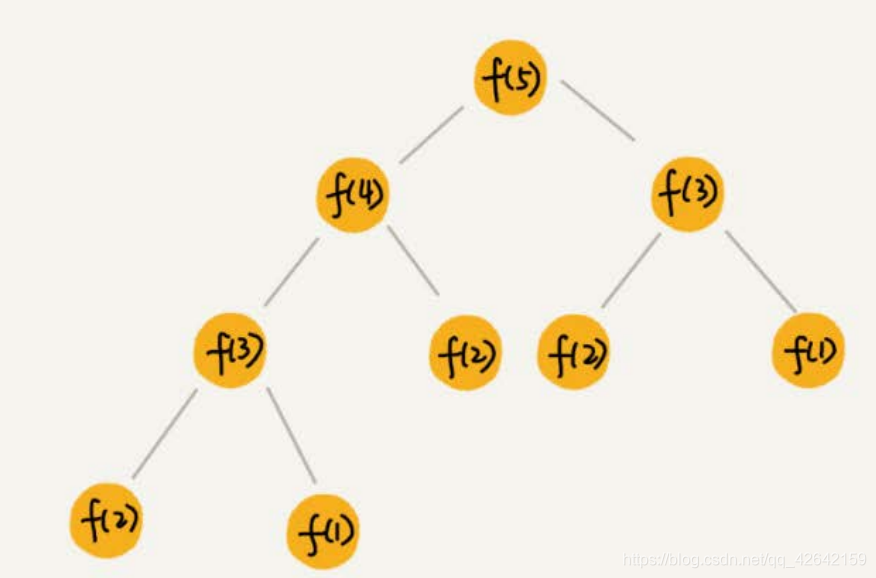
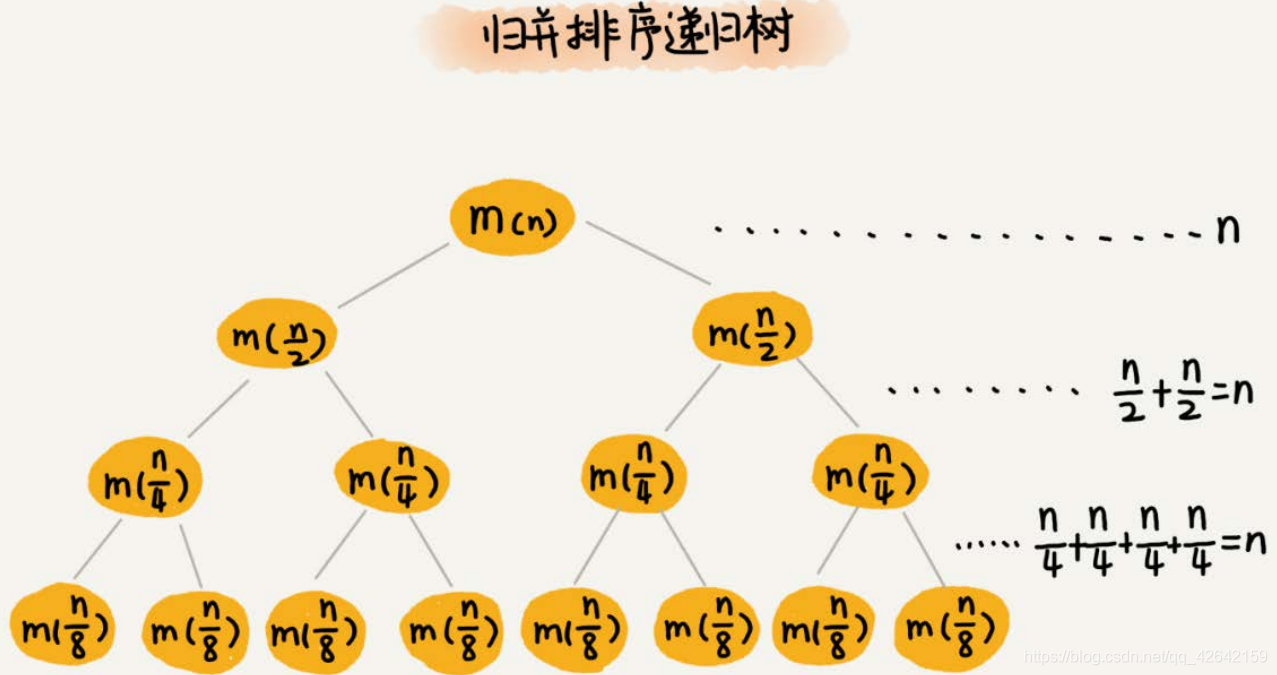
7.1 递归树的应用:
1.分析快速排序的时间复杂度

2.分析斐波那契数列的时间复杂度
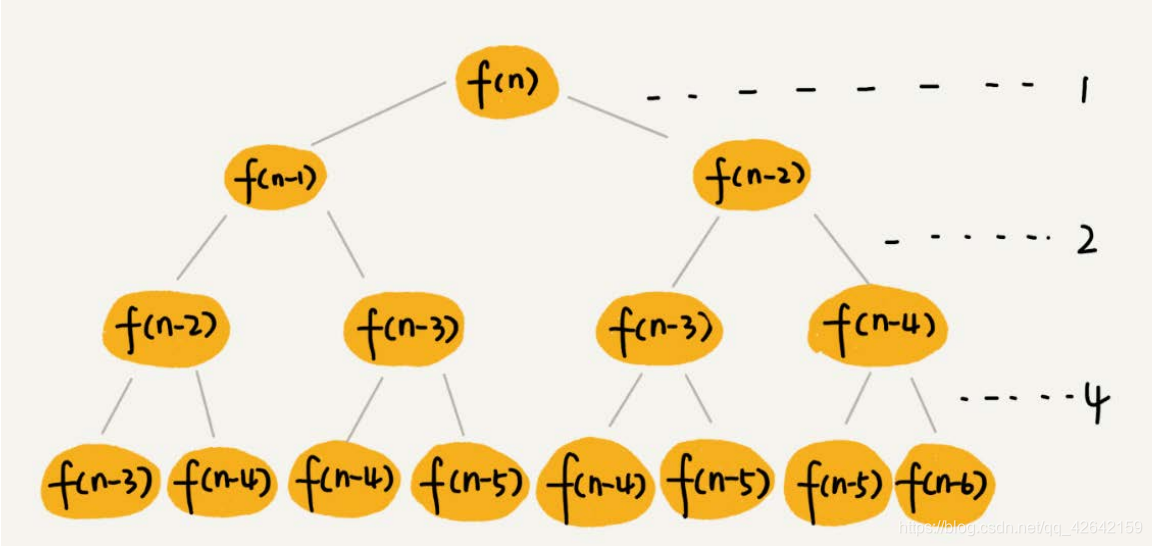
八、堆
堆是一种特殊的树。我们现在就来看看,什么样的树才是堆。我罗列了两点要求,只要满足这两点,它就是一个堆。
1.堆是一个完全二叉树;
2. 堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
我分别解释一下这两点。
第一点,堆必须是一个完全二叉树。还记得我们之前讲的完全二叉树的定义吗?完全二叉树要求,除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
第二点,堆中的每个节点的值必须大于等于(或者小于等于)其子树中每个节点的值。实际上,我们还可以换一种说法,堆中每个节点的值都大于等于(或者小于等于)其左右子节点的值。这两种表述是等价的。对于每个节点的值都大于等于子树中每个节点值的堆,我们叫作 “ 大顶堆 ” 。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫作 “ 小顶堆 ” 。
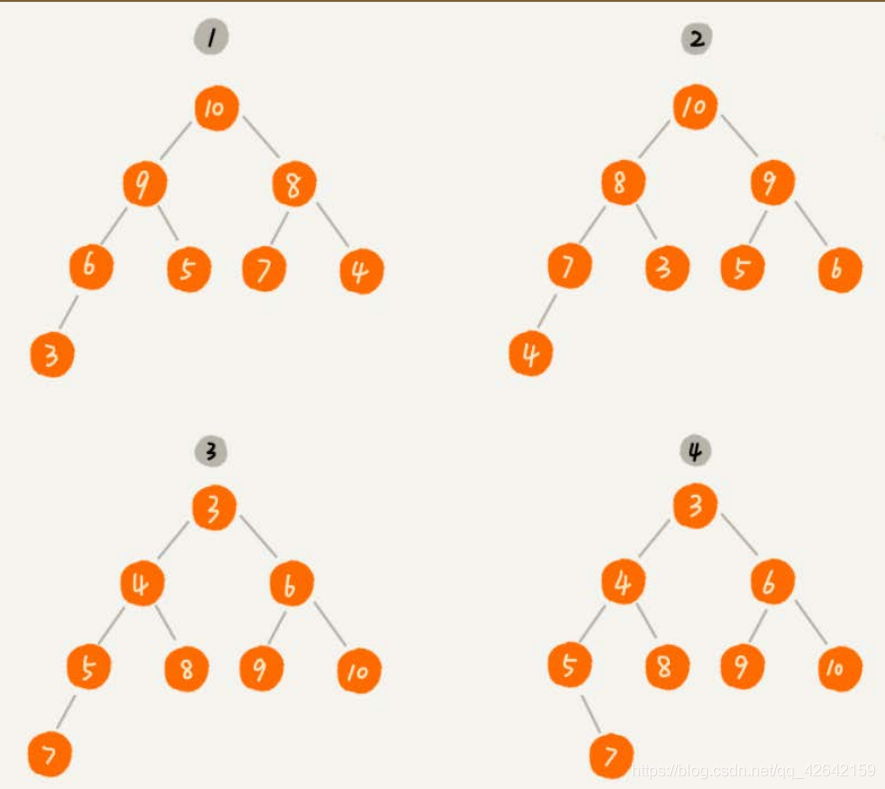
其中第 111 个和第 222 个是大顶堆,第 333 个是小顶堆,第 444 个不是堆。除此之外,从图中还可以看出来,对于同一组数据,我们可以构建多种不同形态的堆。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









