



 本文档详细介绍了如何使用Kafka Connect进行数据迁移操作,包括服务的启动与状态检查、连接器的创建与管理,以及数据的输入和验证。通过一系列步骤,读者将学会如何在Kafka中设置和管理连接器,实现数据的高效传输。
本文档详细介绍了如何使用Kafka Connect进行数据迁移操作,包括服务的启动与状态检查、连接器的创建与管理,以及数据的输入和验证。通过一系列步骤,读者将学会如何在Kafka中设置和管理连接器,实现数据的高效传输。
一.代码准备
GET http://localhost:8083/connectors/
header部分要设置key 和 value 分别是: Content-Type: application/json
GET http://localhost:8083/connector-plugins/
POST http://localhost:8083/connectors/
----------------------------------------
{
"name": "hdfs-hive-sink-01",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"tasks.max": "1",
"topics": "test_source",
"hdfs.url": "hdfs://localhost:9000",
"flush.size": "1",
"hive.integration":"true",
"hive.metastore.uris":"thrift://localhost:9083",
"schema.compatibility":"BACKWARD"
}
}
-------------//这一串代码是放到body部分的,选择row,放进去再post
在xshell中打开一个终端,输入以下代码:
kafka-avro-console-producer --broker-list localhost:9092 --topic test_source --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'
然后就可以在下面属于数据进行尝试:(注意数据的格式一定是你上面写的格式)
{"f1":"f1_001"}
{"f1":"f1_001"}
然后再打开第二个终端输入以下代码后回车:
kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic test_source
//在第一个终端中输入的数据,第二个窗口就会及时更新
在以上的Post操作完成后就可以进行传到hdfs的操作:
GET http://localhost:8083/connectors/
GET http://localhost:8083/connectors/hdfs-hive-sink-01/status
//检查连接状态 ,可省略
GET http://localhost:8083/connectors/hdfs-hive-sink-01/config
//检查配置信息 ,可省略
然后再回到xshell打开第三个终端:
输入:
bee
show tables; //如果有多个数据库要先show databases; use databases——name;
就可以看到根据在第一个终端输入的数据相应的生成了一个表
二.检查服务连接状态、开启所需的服务
1.看一下当前有哪些服务开启
![]()
2.用ops命令可以查看哪些命令对应哪些服务
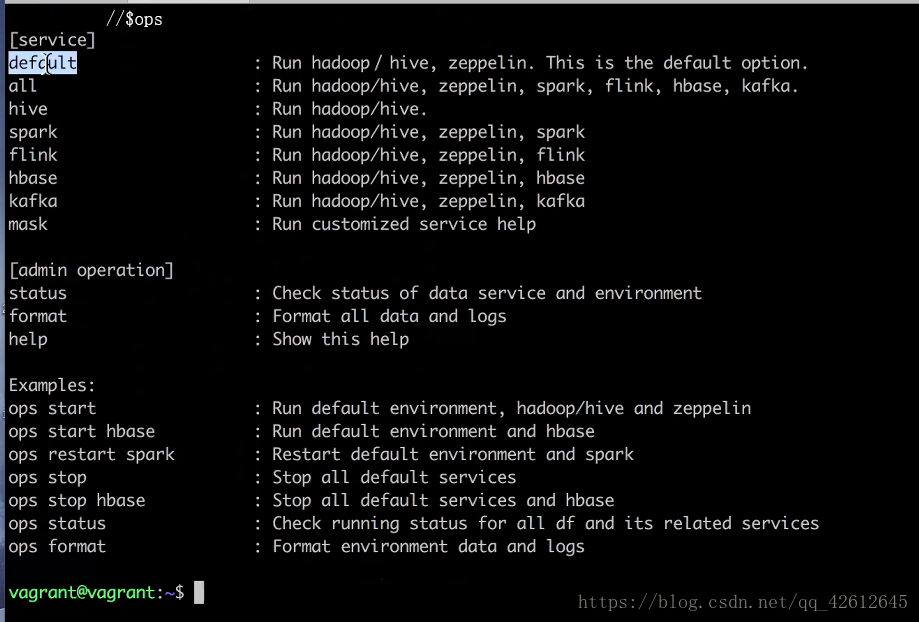
3.用ops start kafka 开启服务
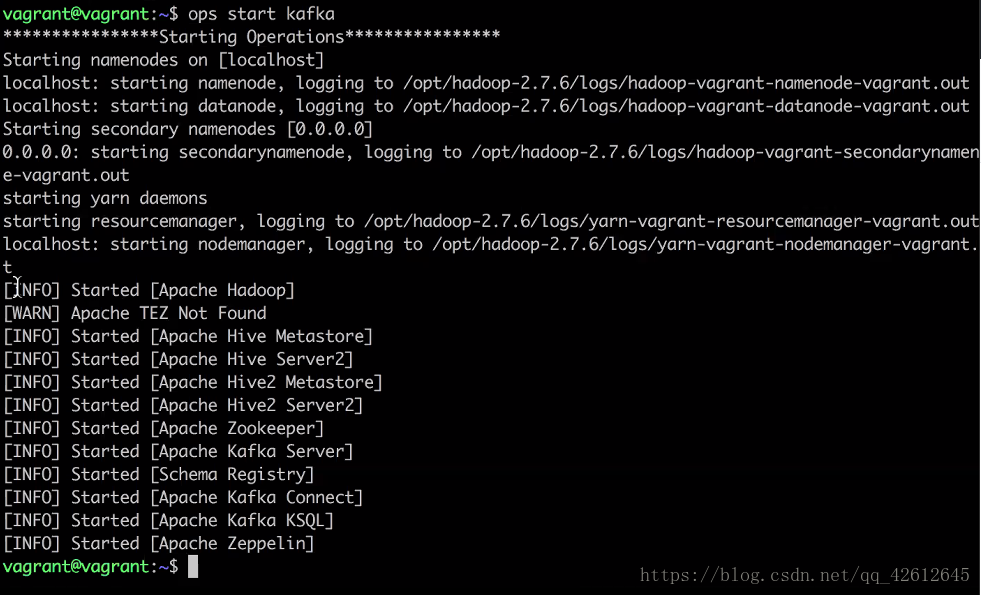
4. 再查看服务开启状态
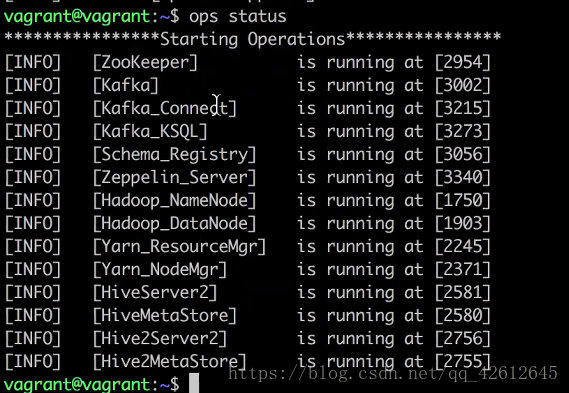
5.如果是重启服务可以用ops restart kafka

6.关闭服务用 ops stop kafka
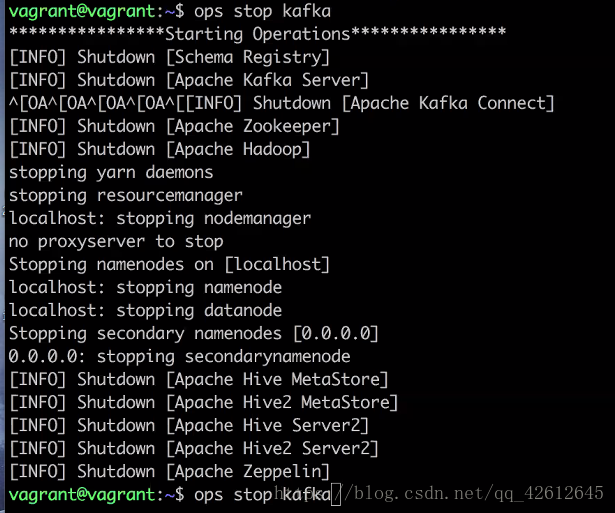
7.用ops status 查看当前还有哪些服务开着,需要关闭的可以用 kill -9 命令杀死
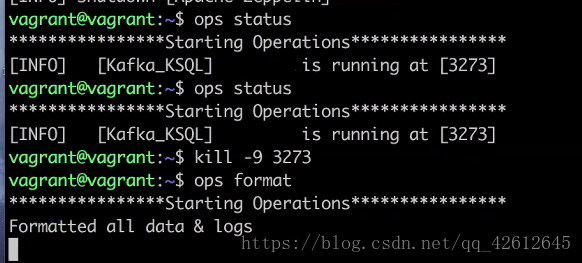
8. 也可以用 ops start mask后面跟0,1 来开启指定的服务
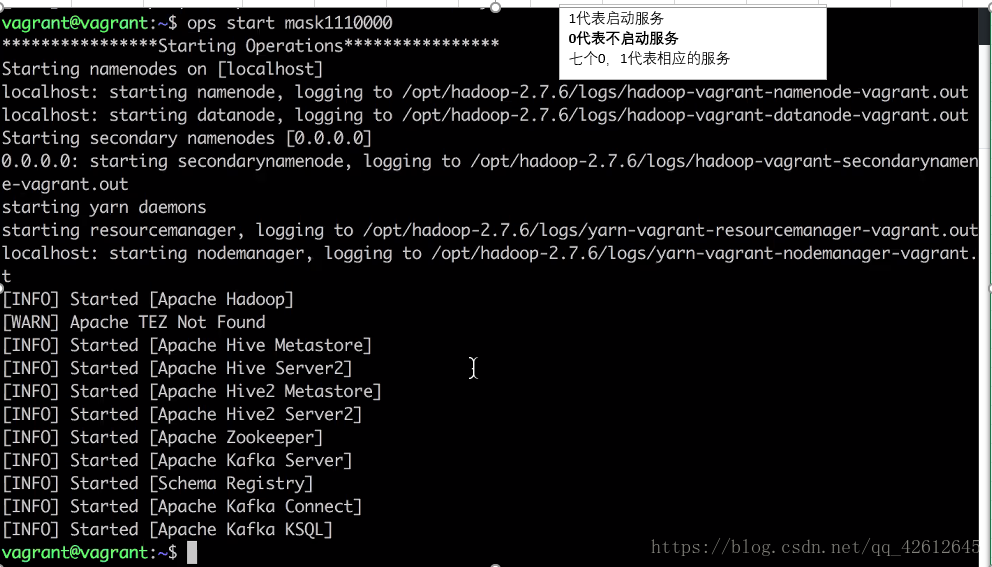
三.连接操作
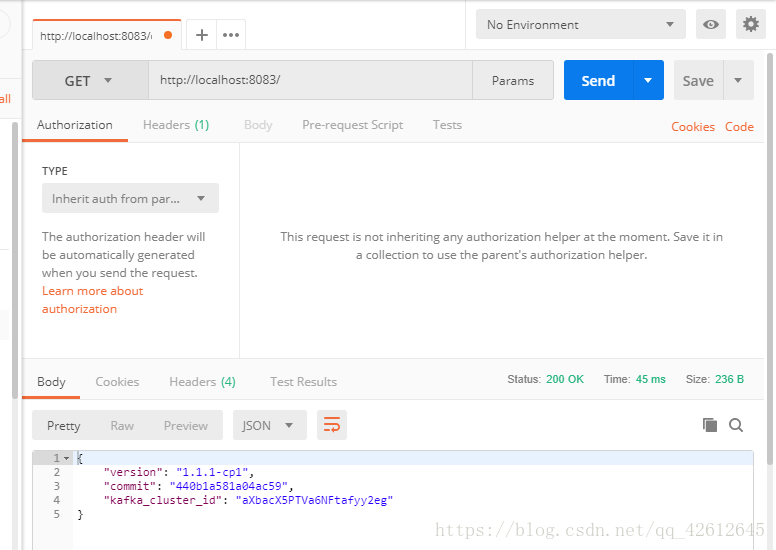
1.输入第一个url进行试水(可省略)会返回版本信息等
2.GET这个connector
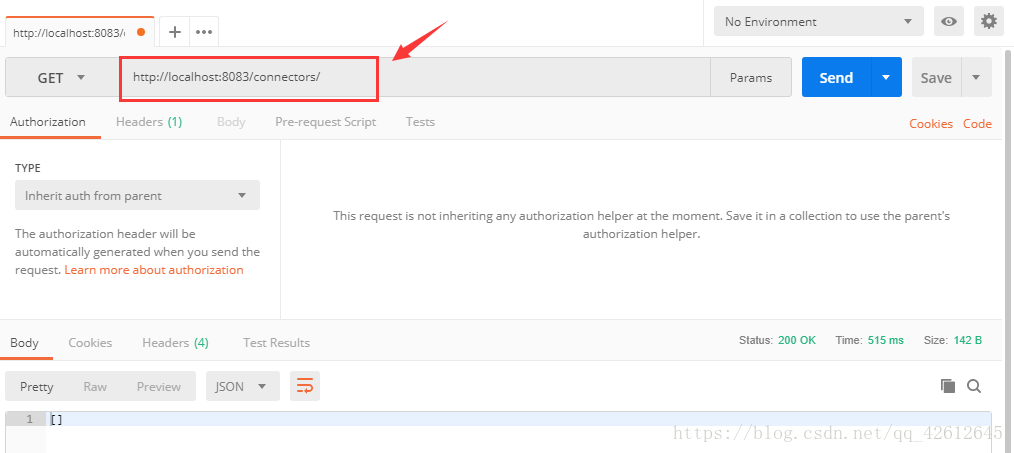
注意写header:
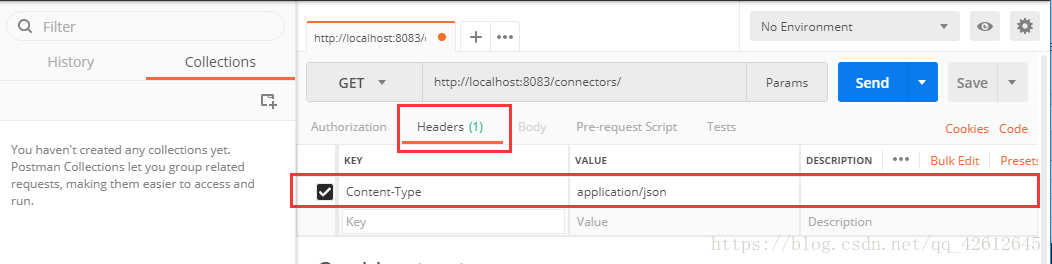
3.再GET connector-plugins
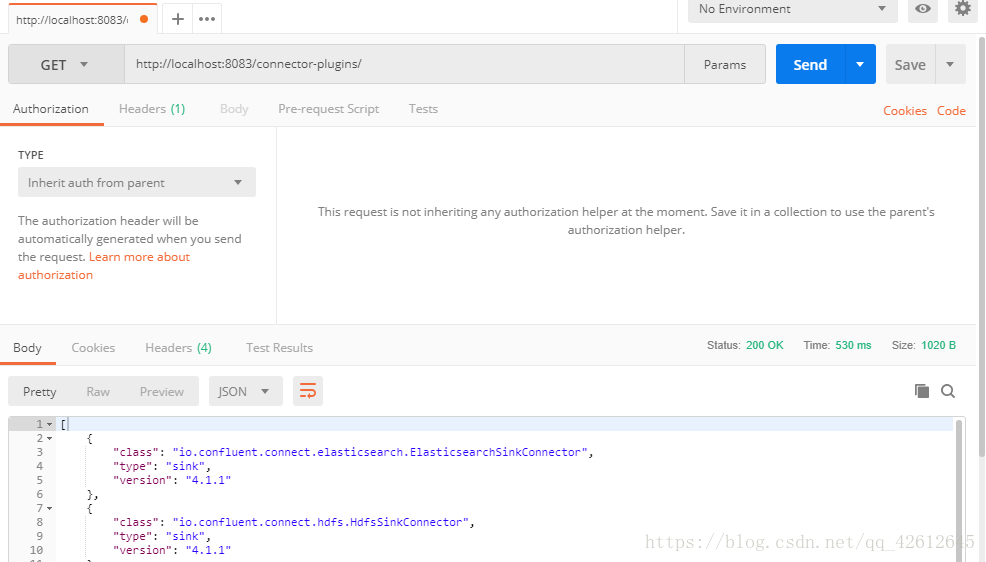
4.POST connector
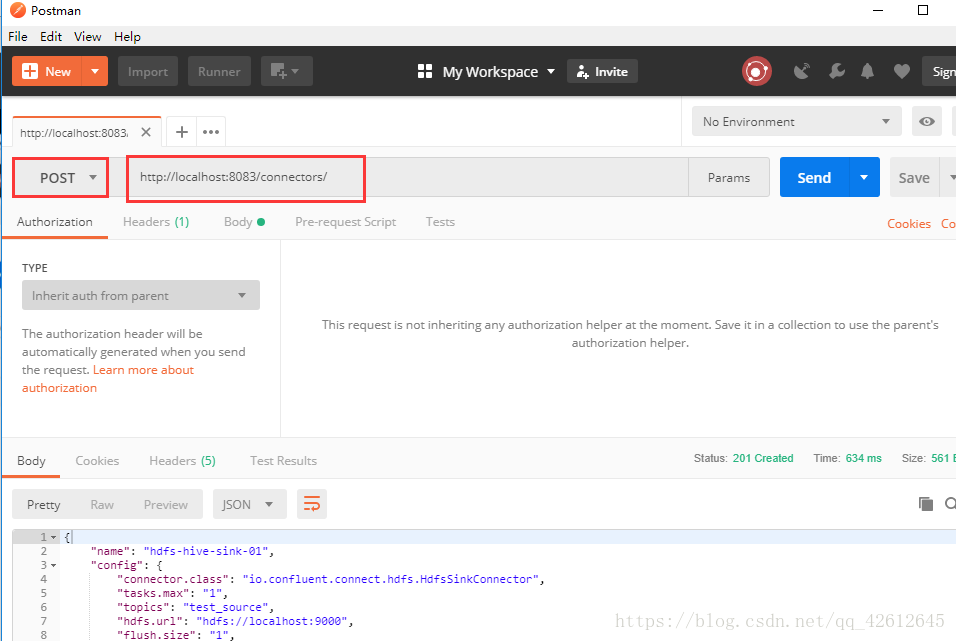
注意:这个post操作要写body,先选择body-->>row -->>写代码
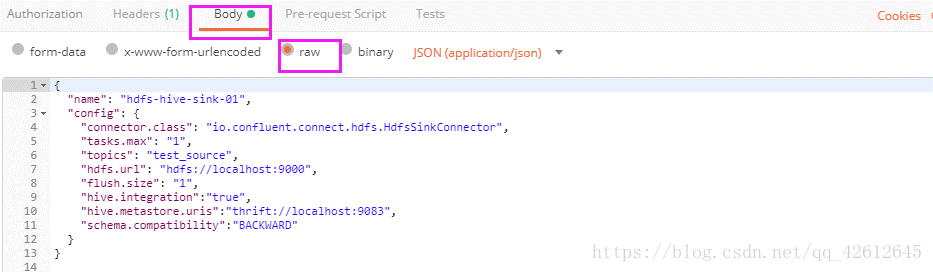
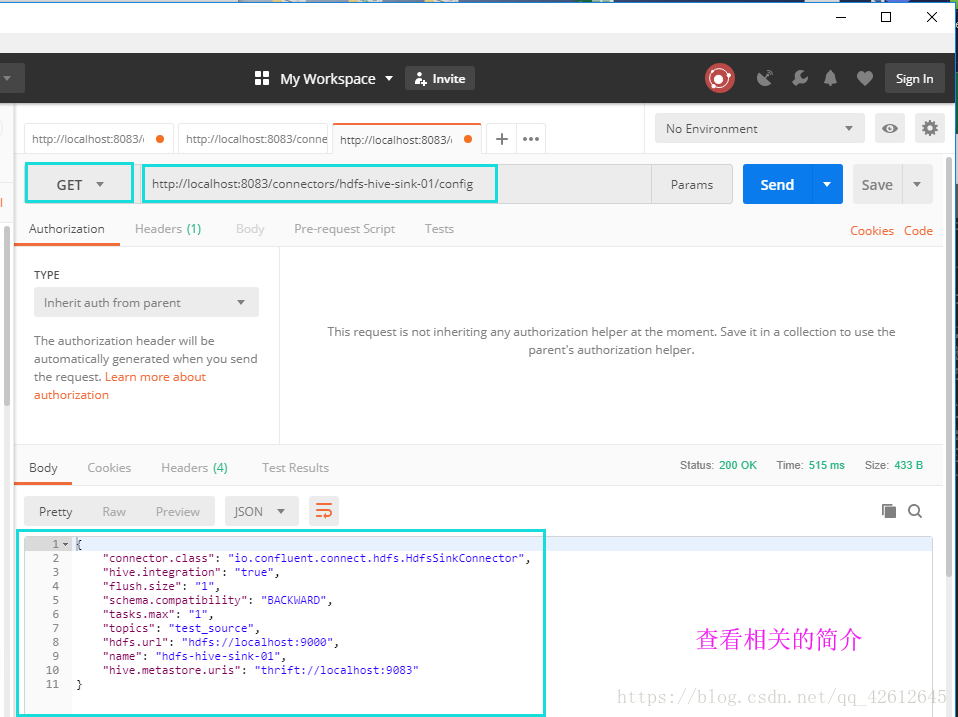
5.解释一下这个body
{
"name": "hdfs-hive-sink-01",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"tasks.max": "1",//表示支持最大线程是一个
"topics": "test_source", //表示从"test_source"读数据
"hdfs.url": "hdfs://localhost:9000",//给出hadoop hdfs的地址
"flush.size": "1",//多少个记录往里面写一次
"hive.integration":"true",//表示支持hive
"hive.metastore.uris":"thrift://localhost:9083",//给出hive的url
"schema.compatibility":"BACKWARD"
}
}
6.然后回到xshell打开一个窗口输入相应命令:然后就可以输入数据了{"f1":"f1_001"} {"f1":"f2_002"} {"f1":"f3_003"}

kafka-avro-console-producer --broker-list localhost:9092 --topic test_source --property value.schema='{"type":"record","name":"myrecord","fields":[{"name":"f1","type":"string"}]}'
7.在第二个窗口执行以下命令然后回车,它就会自动接收第一个窗口输入的数据({"f1":"f1_001"}
{"f1":"f2_002"}
{"f1":"f3_003"}

kafka-avro-console-consumer --bootstrap-server localhost:9092 --topic test_source
8.然后再GET connector
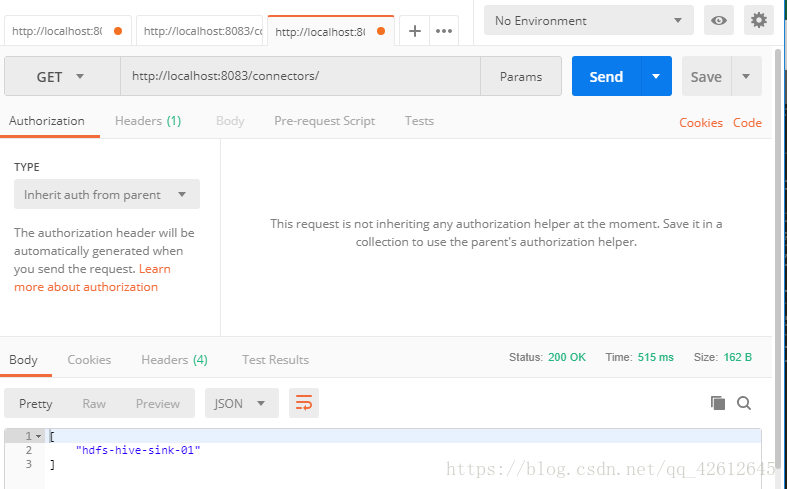
9.查看连接状态(可省略)
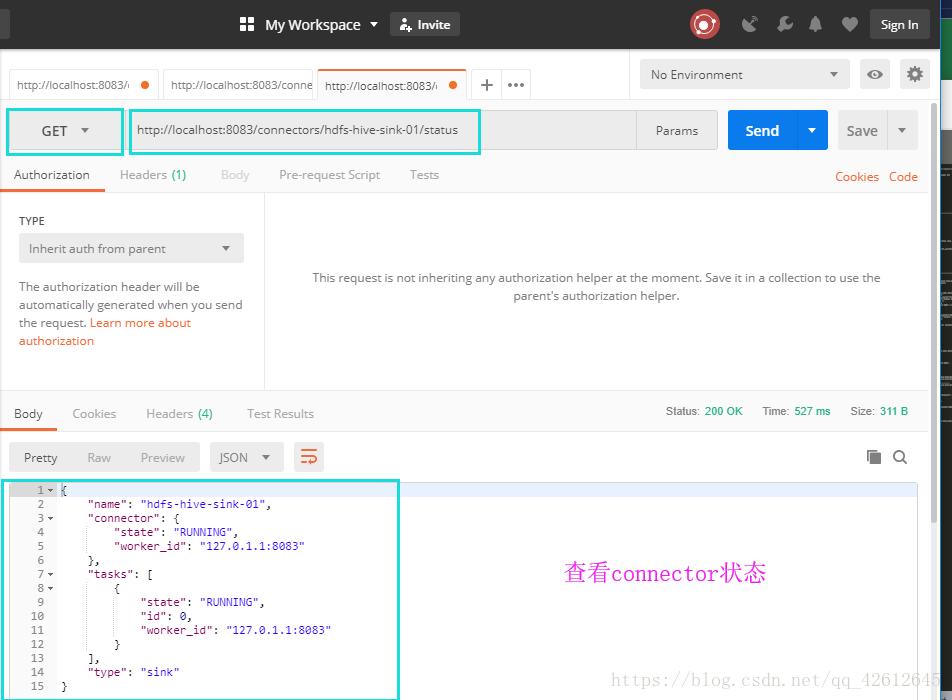
10.查看相应的信息(可省略)
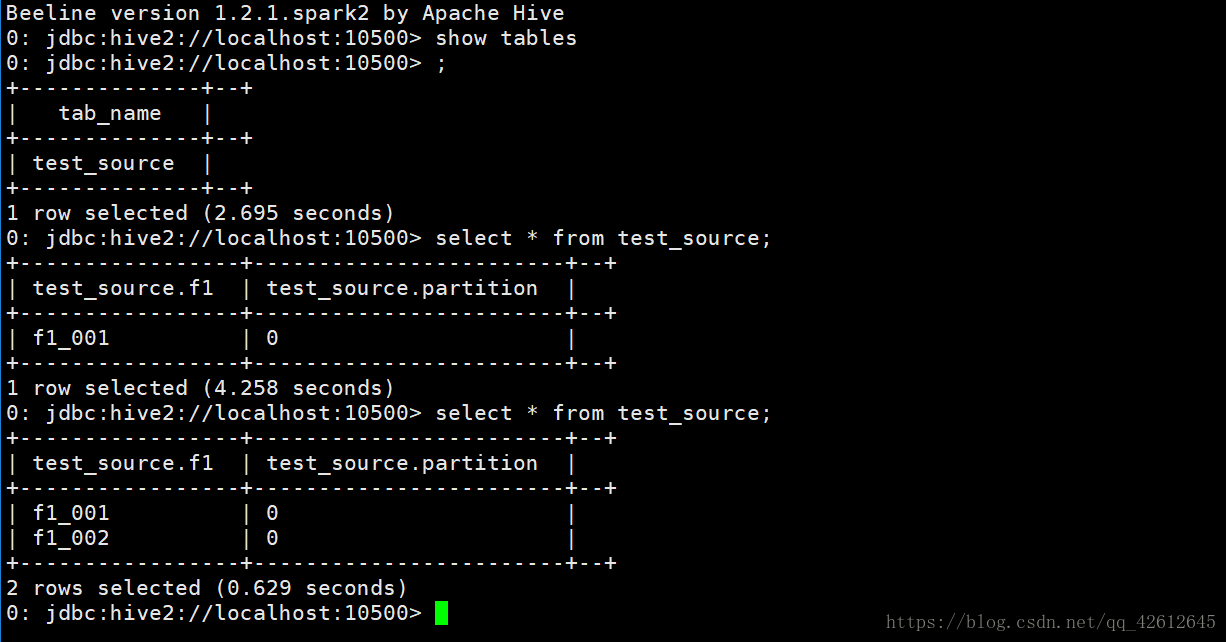
11.回到终端打开第三个连接窗口,输入bee,然后show tables; 你就会看到生成此时hdfs根据第一个连接窗口输入的数据生成了一个表,在第一个窗口有数据更新写入时,这也会相应的改变
三.删除相应的连接
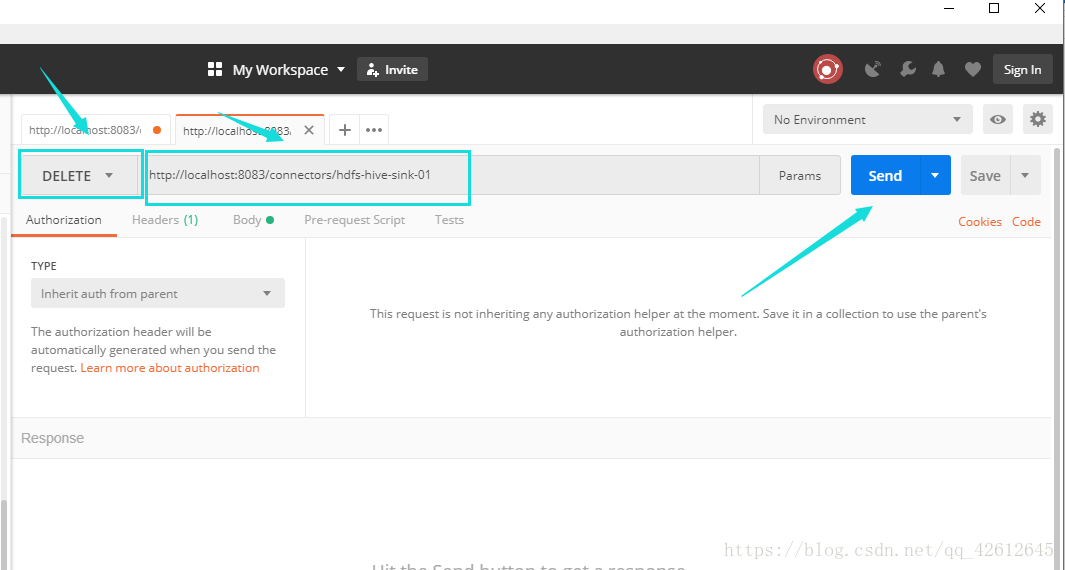
今天操作的图解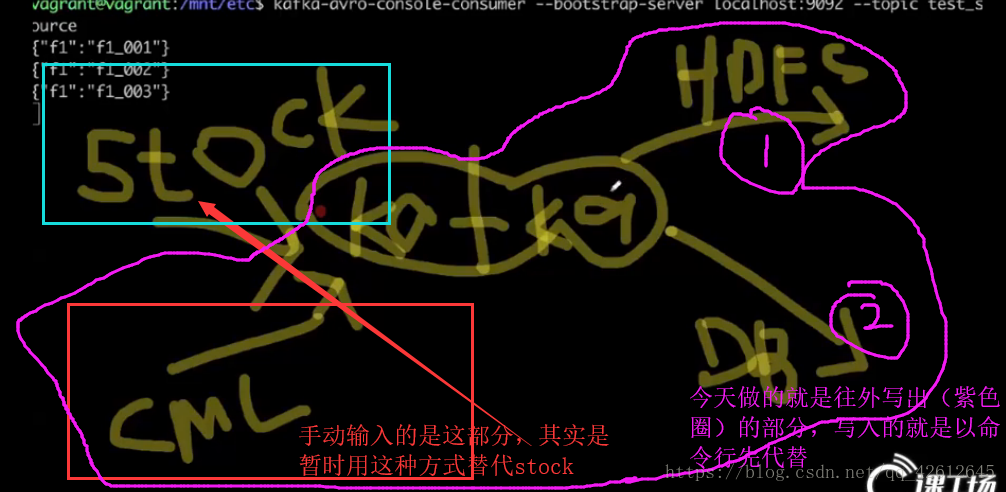

















 1685
1685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









