



YOLOV8文档
一般来说yolo在应用领域常用的是v5或者v8版本,选择较新的v8来温习
从卷积了解起来
一般来说图片的输入都是w×h×3 (RGB三个通道),所以都会遇到多通道卷积。
一般来说多通道卷积:输入通道个数 = 卷积核通道数、 输出通道个数 = 卷积核的个数
卷积核计算:下面几个符号要记住
输入尺寸(input):
卷积核大小(kernel size): k
步幅(stride): s
边界扩充(padding):p
通道数(channel): c
输出尺寸(output):
单通道输出尺寸计算:(i+2p-k)/s 向下取整 + 1
RGB三通道的卷积就是 将三个核计算的结果按照所在位置求和成一个新的值。
可以去看这篇文章https://zhuanlan.zhihu.com/p/251068800
常用术语
Backbone:负责特征提取,采用了一系列卷积和反卷积层,同时使用了残差连接和瓶颈结构来减小网络的大小并提高性能。
Neck:负责多尺度特征融合,通过将来自Backbone不同阶段的特征图进行融合,增强特征表示能力。
Head:负责最终的目标检测和分类任务,包括一个检测头和一个分类头。
检测头包含一系列卷积层和反卷积层,用于生成检测结果;分类头则采用全局平均池化对每个特征图进行分类,输出每个类别的概率分布。
在这里插入图片描述
YOLOV8
模型图
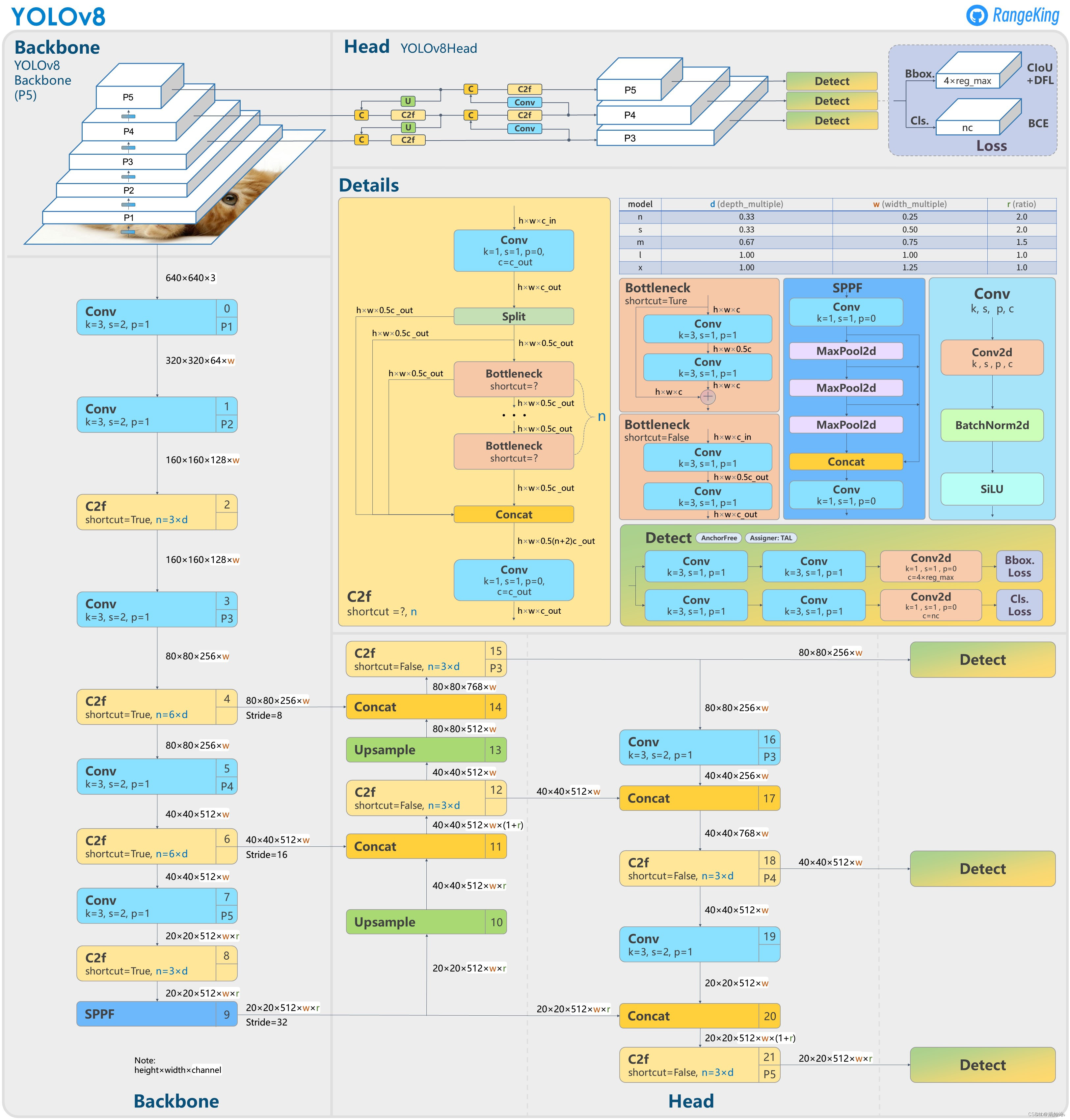
Backbone
关于CSPLayer的演化
首先CBL就是一个复合层。卷积+batch正则化+不同激活函数
CBR: Conv2d + BatchNormal2d + Relu
CBL: Conv2d + BatchNormal2d + LeckyRelu
CBH: Conv2d + BatchNormal2d + Hardswish
CBS: Conv2d + BatchNormal2d + SiLu

关于C3的(三个CBs构成)网络结构,可以去看https://blog.youkuaiyun.com/weixin_55073640/article/details/122614176
C2f模块(特征提取模块)
参考了C3模块以及ELAN的思想进行的设计C2f,通过优化梯度流动和减少冗余参数,实现了更高的特征提取效率和更轻的网络结构。
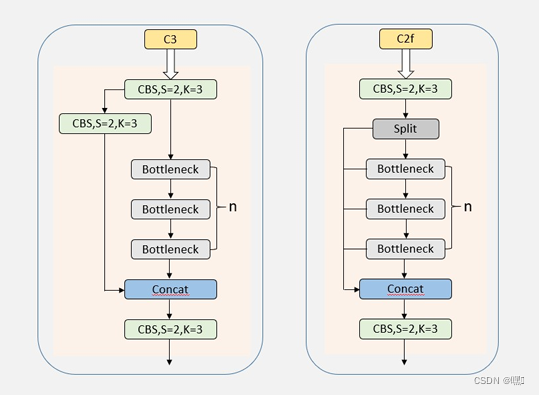
添加了多个残差连接。C2f模块相比于C3模块有更多的跳层连接,并增加了额外的split操作(就是在通道维度一份为二),channel减半,来实现降低参数的目的。
在C2f中Boottleneck就是两个卷积层加入跳跃连接。
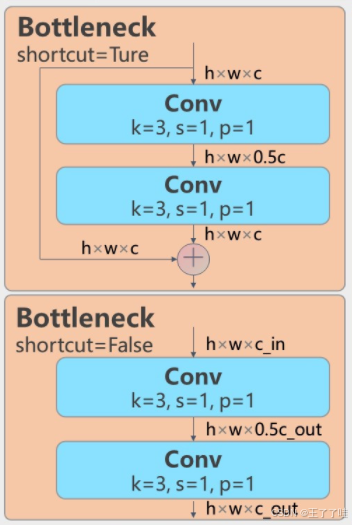
Bottleneck 模块主要包含以下几个部分:
两个卷积层(Conv):
第一个卷积层将输入通道数c1缩减到一个中间的通道数c_(通常是输出通道数c2的某个比例)。
第二个卷积层将中间通道数c_恢复到输出通道数c2,同时可以根据配置应用组卷积(group convolution)。
残差连接(Shortcut):
如果输入通道数c1与输出通道数c2相同,并且shortcut=True,则会启用残差连接,即将输入特征直接加到输出特征上,形成跳跃连接。
这种结构可以帮助网络更好地保留和利用输入特征,缓解梯度消失问题,并加速训练收敛。
Neck多尺度特征融合
PAN-FPN
删除了YOLOv5 中 PAN-FPN 上采样阶段中的卷积结构,先进行下采样操作,然后再上采样操作。将C3模块替换为C2f模块,轻量化的同时使得模型对于不同大小和形状的目标具有更好的适应性。
一是删除了上采样阶段中的卷积结构,减少了计算量;二是将C3模块替换为C2f模块,提高了特征提取的效率。
SPPF改进
Head部分
YOLOv8:改为解耦头(Decoupled Head),分类和回归任务使用独立的卷积层,减少任务间干扰,提升收敛速度和检测精度。
Anchor-Based和Anchor-free
直接预测目标的中心点和宽高比例,减少Anchor 框的数量,
目标检测领域的发展从anchor-free到anchor-base,现在又有回到anchor-free的趋势。
区别在于是否使用预定义的anchor框来匹配真实的目标框。
anchor-base
优点:
适用于多尺度和多宽高比的目标。
对于密集目标排列的情况,锚框可以提高检测性能。
缺点
对于目标数量较少的情况,锚框设计可能浪费计算资源。
对于小目标检测较为困难。
Anchor-free优点:
相对简洁,无需设计大量的锚框。
更适合小目标检测。
缺点
对于多尺度和多宽高比的目标,可能性能较差。
在密集目标排列的情况下,容易出现定位不准确的问题。
https://blog.youkuaiyun.com/qq_44878985/article/details/134718475
TaskAligned
损失函数
VFLLoss 动态调整正负样本权重,增强对难样本(如小目标、模糊目标)的关注。
数据增强
https://blog.youkuaiyun.com/qq_38973721/article/details/128700920
几何变换:如水平/垂直翻转、随机裁剪、旋转、缩放、平移、透视变换等,改变目标物体的位置、方向和大小。
颜色空间变换:如亮度调整、对比度变化、饱和度调整、色调偏移、添加高斯噪声、椒盐噪声等,模拟光照条件、相机白平衡和图像质量的变化。
混合变换:如图像混合(如CutMix、MixUp)、样本拼接(如GridMask、RandomErasing)等,将多个样本的部分内容组合在一起,或随机擦除部分区域。
特定领域的增强:针对特定任务或数据类型设计的增强技术,如深度估计中的视点变换、医学影像中的纹理合成等。
YOLOV8:马赛克增强(Mosaic)、混合增强(Mixup)、随机扰动(random perspective )以及颜色扰动(HSV augment)这四种数据增强方法。
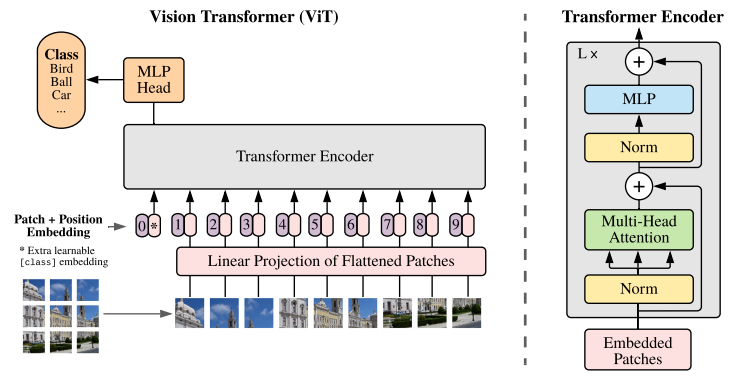
VIT


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









