






一、作业题目:
原生Python实现KNN分类算法,用鸢尾花数据集。
二、算法设计
KNN是一种聚类算法,用于对新的数据点进行分类。对于一个只知道特征的数据点,首先计算它和已知训练集所有点的距离,然后选择最近的K个点进行“投票表决”来决定所属类型。因为训练集的标签是已知的,所以根据“投票”结果,判定该点的类型为“票数”最多的类别。例如在K=3,即选择最近的3个点进行判别时,其属于三角形一类;K=5时,其属于五边形一类。当然,这也就涉及K的选择问题,一般使用交叉验证法确定最优的K值。如图所示:
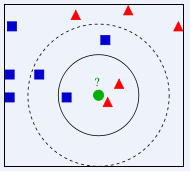
特例:K=1时,可以将训练的模型成为最邻近分类器。
通过调用sklearn库应用此算法可知:只要模仿新建一个类,并包含fit和predict方法即可。
首先实现如何调用sklearn库来实现KNN算法,然后按照同样的流程逐步深入算法的各个部分,最后完成手动实现。每个函数的具体实现说明如下:
1. fit
可以接受两个参数,分别是训练集的特征和标签。由于KNN算法没有显示训练过程(在训练集进入时才开始计算并分类),所以这里只需要将训练集导入类变量即可。
def fit(self, X_train, Y_train):
self.X_train = X_train
self.Y_train = Y_train2. predict
此函数的返回值时预测结果,所以建立一个列表来存放所有的类别结果,该列表就是predictions。之后,只需要遍历每一个测试集里边的特征值数据,并选取距离最近的点(此时设k=1)的类别作为判别的结果,并将其加入predictions即可。
def predict(self, X_test):
predictions = []
for row in X_test:
# label = random.choice(self.Y_train)
label = self.closest(row)
predictions.append(label)
return predictions3. closest
找到离输入的数据点最近的一个点,并将此最近点的类别作为该点类别的预测值返回。首先将测试点与训练集第一个数据点的距离设为初始最小距离,并将第一个点设为初始最邻近的点。之后,遍历训练集的每一个点,只要距离比之前的点小,就更新最短距离,并更新其所属类别(通过记录索引值来记录其类别)。那么在遍历完训练集所有点之后,此时best_dist必时最小的,其对应的类别就是Y_train[best_index]。
def closest(self,row):
best_dist = self.euc(row, self.X_train[0])
best_index = 0
for i in range(len(X_train)):
dist = self.euc(row, self.X_train[i])
if dist < best_dist:
best_dist = dist
best_index = i
return self.Y_train[best_index]4. euc
计算数据点之间的距离。这里的距离函数,选用了欧式距离。
def euc(self, a, b):
return distance.euclidean(a, b)三、源代码
import numpy as np
import operator
from scipy.spatial import distance
class ScappyKNN():
def fit(self, X_train, Y_train, k):
self.X_train = X_train
self.Y_train = Y_train
self.k = k
def predict(self, X_test):
predictions = []
for row in X_test:
label = self.closest_k(row)
predictions.append(label)
return predictions
def closest_k(self, row):
# distances 存储测试点到数据集各个点的距离
distances = []
for i in range(len(X_train)):
dist = self.euc(row, self.X_train[i])
distances.append(dist)
# 转换成数组,对距离排序(从小到大),返回位置信息
distances = np.array(distances)
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(self.k):
voteIlabel = Y_train[sortedDistIndicies[i]]
# 此处 get,原字典有此 voteIlabel 则返回其对应的值,没有则返回0
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
# 根据值(对应“票数”)进行排序,使得获得票数多的类在前(故使用reverse = True)
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
# 返回该测试点的类别
return sortedClassCount[0][0]
# 计算欧式距离
def euc(self, a, b):
return distance.euclidean(a, b)四、测试用例设计即调试过程截图
1、测试用例设计:
from sklearn.datasets import load_iris
iris = load_iris()
X = iris.data
Y = iris.target
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y)
my_classifier = ScappyKNN()
my_classifier.fit(X_train, Y_train, k = 3)
predictions = my_classifier.predict(X_test)
from sklearn.metrics import accuracy_score
print(accuracy_score(Y_test, predictions))
2、调试过程截图:
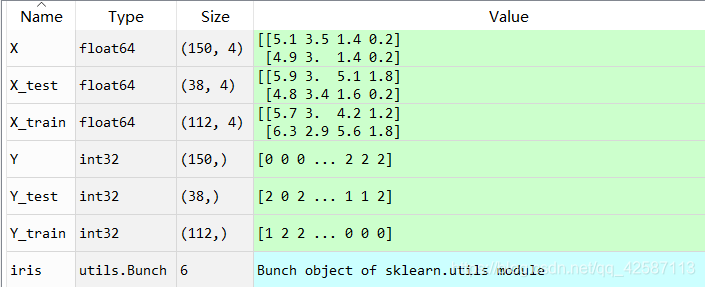
(1)获取X、Y:

(2)执行KNN类方法:
(3)预测结果:

3、测试结果:
![]()
五、总结
K近邻算法中K的含义是:我们可以考虑训练集中与新数据点最近的任意K个邻居,而不是只考虑最近的一个。
至此,已经完成了手动实现聚类算法。对于一个算法,如果只会调用的话,就好比黑盒一样,不知道原理,用起来自然不会很放心。而经过自己的实现,对其内部的机制就十分清楚了,对之后的调用甚至优化算法都有很大的帮助。

















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









