






 本文介绍了SPP-Net如何通过空间金字塔池化解决卷积神经网络输入图片尺寸固定的问题,实现任意尺寸输入的同时保持输出特征向量的固定长度。通过去除R-CNN中的重复计算步骤并采用多级池化方法,提高了图像分类和目标检测的效率与准确性。
本文介绍了SPP-Net如何通过空间金字塔池化解决卷积神经网络输入图片尺寸固定的问题,实现任意尺寸输入的同时保持输出特征向量的固定长度。通过去除R-CNN中的重复计算步骤并采用多级池化方法,提高了图像分类和目标检测的效率与准确性。
摘要:现存的卷积神经网络都需要固定尺寸的输入图片,这个尺寸一般都是自己设定的,可能不合理。spp-net可以不限制输入图片的尺寸大小,却可以生成一个固定长度的表示(fm)。
r-cnn的计算过程:先用选择搜索对原图处理,提取2000个region(在原图上),然后把这2000个region每一个都放到一个卷积神经网络中训练、测试,因为这2000个region肯定有重合的,所有肯定会有重复计算。
而本文中用选择搜索在提取2000候选框,但是这2000个候选框不是在原图上,而是在经过对卷积层输出的fm上,然后把这2000个在fm的region直接送到分类器、检测器中训练、测试,因为少了把原图上的region经卷积处理这一步,故没有了重复计算。
本文的两个关键创新点:
1、 金字塔池化:即对最后一个卷积层的输出,进行多级池化,将池化的结果拼接成一个向量(如21个元素)送入卷积层。
2、 去除r-cnn中对输入图片的重复计算:主要就是不在原图上去region,而是把选择搜索得到的候选框映射到左后一个卷积层输出的fm上。
1、 引言
流行的cnn架构都需要有一个固定尺寸的输入,这一版都是对输入cnn图片(经过选择搜索后的)进行crop(裁剪)或者warp(拉伸压缩)得到一个固定尺寸的cnn输入。crop后可能会得不到真个目标,而warp可能和最初的形状差异巨大。
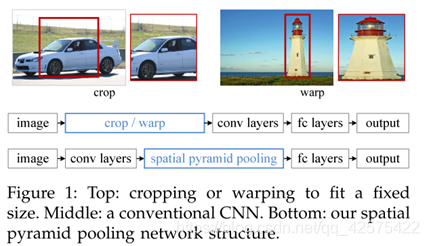
cnn为什么需要一个固定大小的输入?我们知道cnn中既有卷积层也有全连接层,卷积层用的是滑动窗口的方法,这并不需要固定输入大小,而真正需要固定输入大小的是全连接层。本文用空间金字塔池化的方法,将卷积层的输出池化到一个固定大小的fm,然后把这个作为全连接层输入,这样就避免了要对输入图片(经过选择搜索后)进行crop或warp处理。
spp的特性:
1) spp能生成固定尺度的输出,滑动窗口不行。
2) spp用了多层空间箱(multi-level spatial bins)(每一个空间箱对应输出的就是一个像素点,用的是max pooling方法得到),而滑动窗口只用了一个大小的窗口(即卷积核的大小)。
3) spp能pool从可变大小的输入图片中提取特征。(跟第一点很重复)
2 带spp的深度网络
2.1 卷积层和特征图
卷积层输出的特征图中某个目标的激活值的相对位置和原图的这个目标的相对位置一样。证明了卷积层的空间不变性。
2.2 spp(空间金字塔池化)
就是用一个根据输入fm的大小进行按比例的max pooling,池化成一个固定尺度的多维向量。例如要得到55的输出(即25个元素),若输入时1010的话即横、纵向都是每10/5=2个元素去一个最大值输出。若输入时100200的,横向是每100/5=20个元素取一个最大值,纵向是每200/5=40元素取一个最大值输出,这样得到的输出就是55的。
2.3 训练网络
单尺度训练:即固定输入尺度训练(224224),同时对最后一个卷积层的输出用了不同size的卷积核来pooling(multi-level pooling),输出不同大小的fm(33,22,11),然后把这些输出展成向量连到一起作为全连接层的输入。单尺度的训练的目的就是为了满足多级别池化的要求。
多尺度训练:此处用两种输入图片尺度(180180,224224)交替训练,然后在最后一个卷积层的输出运用spp得到固定大小的fm,对此fm运用单尺度训练中提到的多级别池化方法。这样做的目的就是允许有不同大小的输入图片,同时也利用了现在已经优化的很好的多级别池化。反之,如果不用spp,是没办法的用多级别池化的,因为最后一个卷积层的输出尺度不一样,用了多级别池化后的输出尺度也不一样,无法投入到要求固定尺度输入的全连接层。
上述单/多尺度训练仅在训练阶段,在测试阶段输入任何大小的图片都是可行的。
3 为图像分类SPP网络
3.1 在ImageNet 2012 分类的实验
图片resize,使短边长256,然后从中间裁剪出224224的大小。
数据增强:水平发翻转和颜色改变(color altering)
全卷积层用了Dropout。
学习率:最初是0.01,每次不再收敛时,学习0.1。
3.1.1 主干网络
3.1.2多级别pooling对准确率的提高
实验表明,多级别pooling对准确率的提高并不是因为增加了模型参数,而是因为因为多级别pooling对于目标的变形和空间布置更具有鲁棒性。但是相对于spp提高甚微。
消融实验有问题,没有单独控制有的网络有多级池化,有的没有,故无法证明多级别训练对准确率的提高有影响。
3.1.3 两尺度交替训练对准确率的提高
相对于单尺度有略微提高,若是更多尺度训练也有略微提高,但微乎其微。
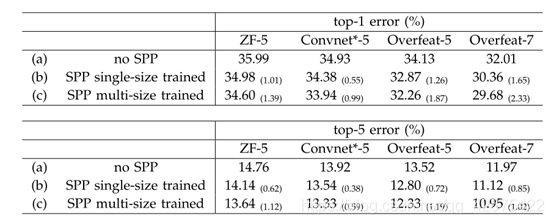
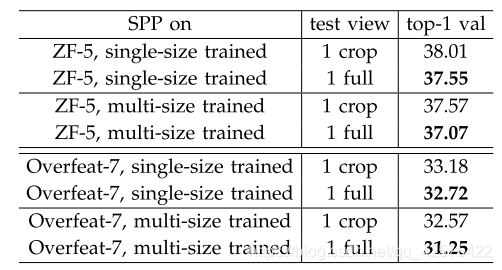
3.1.4 全图无裁剪(有resize,但保持高宽比)与裁剪后的图片(从中心裁剪出224*224)训练
证明了维持图片完整性的重要性
4 spp-net for object detection
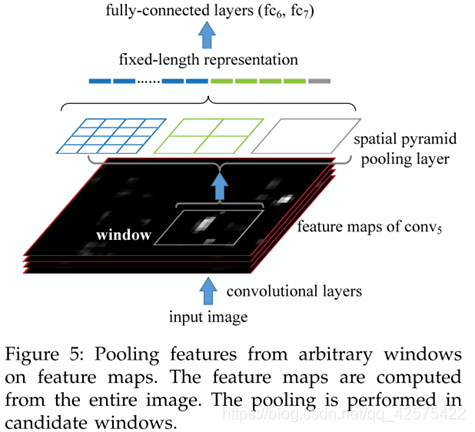
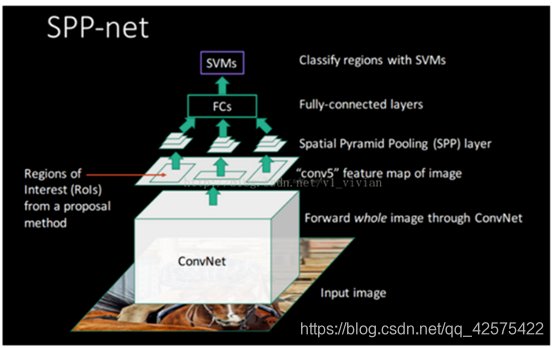
图中没有绘出选择搜索的过程,选择搜索得到的结果直接映射到第五个卷积层上了。
4.1 检测算法
对于检测算法,论文中是这样做到:使用ss生成~2k个候选框,缩放图像min(w,h)=s之后提取特征,每个候选框使用一个4层的空间金字塔池化特征,网络使用的是ZF-5的SPPNet形式。之后将12800d的特征输入全连接层,SVM的输入为全连接层的输出。
这个算法可以应用到多尺度的特征提取:先将图片resize到五个尺度:480,576,688,864,1200,加自己6个。然后在map window to feature map一步中,选择ROI框尺度在{6个尺度}中大小最接近224x224的那个尺度下的feature maps中提取对应的roi feature。这样做可以提高系统的准确率。
4.2 检测结果
4.3 复杂度与运行时间
4.4 为目标检测做模型混合
4.5 在ILSVRC 2014上的检测
5 结论
完整的spp-net:

















 1247
1247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









