








一、多核CPU的结构
服务器的多核结构属于NUMA(Non-Uniform Memory Access,非一致性内存访问)架构。这里有一篇很好的介绍NUMA架构理解。
以我们课题组的服务器为例,上面有两个“插槽”,即两个socket(物理概念),逻辑上称为节点node。
每个插槽10个物理核core,每个物理核通过超线程技术可以产生两个逻辑核processor。
因此我们服务器可以有$ 2 \times 10 \times 2=40$个线程 。
CPU亲和的意思是,假设我们产生40个线程,希望每个线程运行在他们各自的node上或者core上,这样可以减少程序运行时的内存搬运。
二、查看服务器配置
cat /proc/cpuinfo #查看所有processor的信息
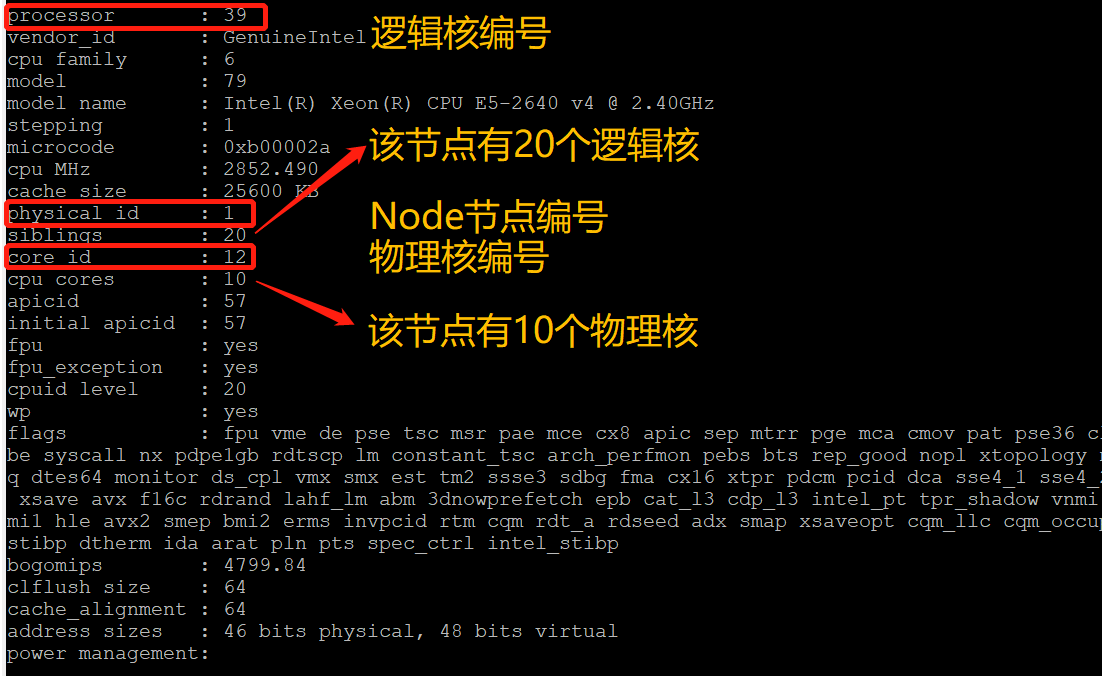
这是最后一个逻辑核的信息,总共有40个逻辑核,该逻辑核在node1节点的12号cpu上(这里的编号不一定连续)。所有的逻辑核分布如下:

因此我们设置线程时,可以绑在同一个node上,即绑在逻辑核编号为{0,2,…,18,20,22,…,38}的集合,或{1,3,…,19,21,23,…,39}的集合,让内存不要在Node0和Node1之间发生。
也可以绑在同一个core上,即绑在逻辑核编号为{0,20},{2,22},{4,24},…,或{19,39}的集合,这样不同物理核之间也不会用内存交换,提高运行速度。
可以用numactl程序查看这些核的分布情况,如没有可以安装sudo apt install numactl,但服务器上我们一般没有root权限,还可以这样查看:
cat /sys/devices/system/node/node0/cpulist
cat /sys/devices/system/node/node0/cpumap
三、设置pthread亲和性
还是用求和的例子说明:
#define _GNU_SOURCE
#include <stdio.h>
#include <sched.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
const int S = 100000000;
int* arr;
typedef struct{
int first;
int last;
int result;
}MY_ARGS;
void* mysum(void* args){
int i;
int s=0;
MY_ARGS* my_args = (MY_ARGS*) args;
int first = my_args->first;
int last = my_args->last;
for(i=first;i<last;i++){
s = s + arr[i];
}
my_args -> result = s;
return NULL;
}
int main(){
int i;
arr = malloc(sizeof(int) * S);
for(i=0;i<S;i++){
if(i%2==0)
arr[i]=i;
else
arr[i]=-i;
}
//亲和性的process集合
int blist[20]={1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39};
cpu_set_t cpuset_1,cpuset_2;
CPU_ZERO(&cpuset_1);
CPU_ZERO(&cpuset_2);
for(i=0;i<20;i++){
CPU_SET(blist[i], &cpuset_1);
CPU_SET(blist[i]-1, &cpuset_2);
}
//亲和性的属性设置
pthread_attr_t attr1;
pthread_attr_t attr2;
pthread_attr_init(&attr1);
pthread_attr_init(&attr2);
pthread_attr_setaffinity_np(&attr1, sizeof(cpu_set_t), &cpuset_1);
pthread_attr_setaffinity_np(&attr2, sizeof(cpu_set_t), &cpuset_2);
// 产生两个线程
pthread_t th1;
pthread_t th2;
int mid = S/2;
MY_ARGS args1 = {0,mid,0};
MY_ARGS args2 = {mid,S,0};
pthread_create(&th1,&attr1,mysum,&args1);
pthread_create(&th2,&attr2,mysum,&args2);
pthread_join(th1,NULL);
pthread_join(th2,NULL);
printf("sum: %d\n",args1.result + args2.result);
return 0;
}
这里将两个线程绑分布绑在node0和node1节点,也可以都绑在同一个节点,因为每个节点最多能跑20个线程,问题不大。
更多实例可以参看我的gitee:pthread亲和性

















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









