







摘要
封闭轮廓是物体识别以及增强现实中虚拟物体与现实相结合的重要因素。但很难精确进行重建,比如:在基于立体视觉重建方法中,轮廓周围的点只能在两帧图像中其中一个里面出现。 引入了normal estimation(法线估计)增强深度估计,引入新约束项来限制法线、深度和轮廓估计。由于ground truth很难获得,使用合成图像用作训练。在NYUv2-Depth上运行后,在轮廓处效果超过了ground truth。
1 介绍
如图1所示,单目深度估计中轮廓无法正确重建,但对于物体识别、增强现实和路径规划是重要线索。这可能由于以下原因:
- 训练图像的轮廓周围标注不准,如果标注是来自立体视觉重建或结构光相机的方法。比如使用NYUv2-Depth dataset的 [25]被用作目前许多方法的评价benchmark,由于在轮廓的一侧或两侧,存在仅在一帧图像中可见的三维点,结构光相机本质上依赖于立体重建,也具有相同的问题。
- 轮廓信息只代表图像的一小部分,如果不进行特殊处理对损失函数影响不大。
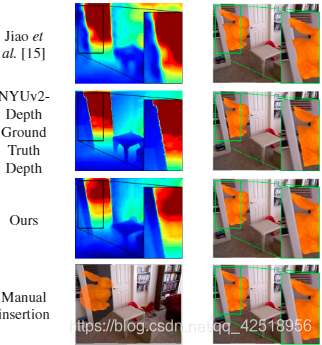
图1:SharpNet在边缘处的效果,比结构光深度相机有更明显的边缘。本图在NYUv2的RGB图像基础上添加了虚拟Stanford rabbit对图像进行增强。左侧三行是用来occlusion-aware插入的深度图,右侧是增强结果。与使用binary mask的手动添加相比(最后一行),轮廓周围的几个像素的误差会明显降低图像合成的真实性
本文将深度估计与轮廓一同进行训练,参照将深度和normal一同估计并约束的[30, 23, 35]。设计一个对深度、normals、occluding contours的网络,并最小化深度和轮廓之间的损失函数,通过简单设计loss达到实时工作,在 640 × 480图像上运行150 fps。
为了增强效果,使用轮廓深度准确的合成图像作为训练用的标注数据来进行与训练。由于ground truth的边缘信息不准确,不能使用原来的评测标准,于是手动生成100张来自NYUv2-Depth的随机图像,并命名为NYUv2-OC。除了对深度进行评估,还对轮廓进行2D定位。
2 相关工作
2.1 监督与自监督深度估计
随着大型标注数据集的诞生,基于监督学习的深度估计被提出,Eigen [6, 5]使用多尺度深度估计,来获得全局和局部信息从而帮助深度估计。之前的工作还考虑过ordinal depth classification [8]或 pair-wise depthmap comparisons [2]来加强局部和非局部区的约束。
- Laina [18]:使用deep residual neural networks [12]并利用BerHu [21, 40] reconstruction loss取得成果,但是在边缘深度过于光滑。
- Jiao [15]:提出NYUv2 dataset 的数据分布是 heavy-tailed形式的,因此对网络使用attention-driven loss进行监督,并将深度估计与语义分割相结合,但是虽然效果增强,但是在high-depth区,如窗户、走廊或镜子处存在bias。尽管最终Loss降低,但是会产生blurry的深度图。
2.2 Edge- and Occlusion-Aware depth estimation:
Wang [30]:引入SURGE【30】方法通过同时学习深度、normal maps来增强平面和边缘区的场景重建。然后,使用Dense Conditional Random Field (DCRF)对深度进行优化。然而这种方法不适合实时运行,并且使用的是传统深度误差度量,对边缘处效果没有提升.
在对KITTI使用立体图像对或图像序列深度估计时,许多自监督方法[36, 35, 37, 28, 10]已经添加了边缘、轮廓感知的几何约束。但是虽然能够测试单目深度估计,但是需要在训练时用多视角标定过的图像训练,因此不能在单目RGB-D数据集NYUv2-Depth [25] 或 SUN-RGBD [26]上训练。
考虑到缺乏评估标准以及从估计深度中的边缘、平面重建质量标准,Koch [16] 引入iBims-v1数据集,包含100张高质量RGB图像和相应深度图,并引入了轮廓处的标注和评价标准,以及平滑区域的惩罚数,本文评估方法是基于此方法做的.
3 方法
如Figure2,训练一个网络![]() 来进行估计,输入为 图像
来进行估计,输入为 图像![]() ,深度图
,深度图![]() ,边缘可能性图
,边缘可能性图![]() ,表面法向量图(surface normals)
,表面法向量图(surface normals)![]() 。此方法由于几何估计的部分,在室内数据集效果更好Figure3。
。此方法由于几何估计的部分,在室内数据集效果更好Figure3。
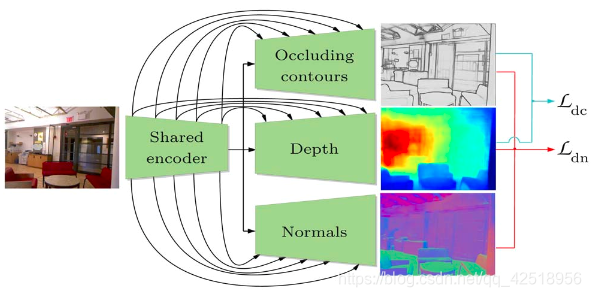
图2:本文的“U-net”形状【24】的多任务encoder-decoder网络结构,使用单独的ResNet50 encoder来学习中间表达内容,并由所有的decoder所共享,这个设置对所有任务都起到作用。此外 在encoder和decoder的相应尺度特征之间加入了skip-connection
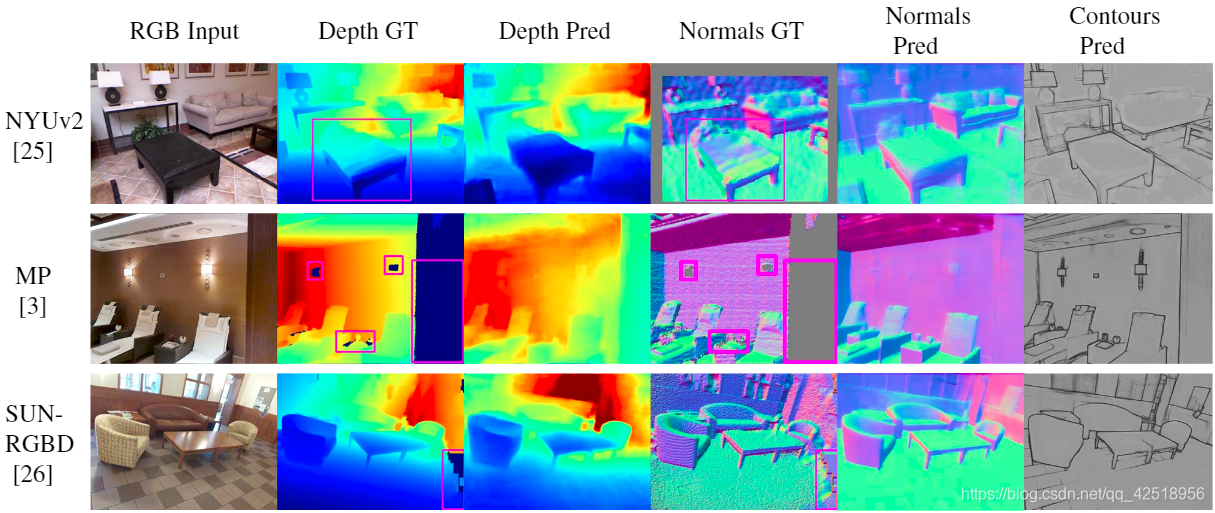
图3:从多个RGB-D数据集的单图像估计效果。“MP”是Matterport3D,“GT”是ground truth ,“Pred”是预测结果。红框是成功重建的几何区域但是Kinect不准确(在一张图,椅子应该离台灯更近),NYUv2 和 SUN-RGBD[20] 的ground truth的法向量是使用[25]的代码计算而来
3.1 训练过程
先使用合成数据集PBRS [39]训练f,对每帧图像提供深度图D,法向量图N,物体轮廓二进制图C。PBRS中没有提供轮廓图,先用C占位。我们发现,大部分的轮廓边缘是由于物体相互遮挡造成。然而,我们的网络能够在没有边缘监督情况下学习到物体的内部边缘,于是分别利用深度图D与边缘估计C来实现对物体内部边缘估计。
然后,使用NYUv2-Depth dataset在没有使用边缘或法向量(![]() )进行监督情况下微调f:即使[17]和[25]对Kincet-v1深度图使用不同估计方法生成normals map,但输出都含噪声。NYUv2-Depth dataset中没有直接提供边缘轮廓,尽管可以使用edge detectors [1, 4]自动提取边缘,但是这样提取会对检测器参数十分敏感(Figure4)。相反,我们引入了一致性项,在训练时对边缘、法向量、深度图进行约束。 测试时,如果对法线和边界不感兴趣,可以选择只使用f的深度估计,从而快速运行
)进行监督情况下微调f:即使[17]和[25]对Kincet-v1深度图使用不同估计方法生成normals map,但输出都含噪声。NYUv2-Depth dataset中没有直接提供边缘轮廓,尽管可以使用edge detectors [1, 4]自动提取边缘,但是这样提取会对检测器参数十分敏感(Figure4)。相反,我们引入了一致性项,在训练时对边缘、法向量、深度图进行约束。 测试时,如果对法线和边界不感兴趣,可以选择只使用f的深度估计,从而快速运行
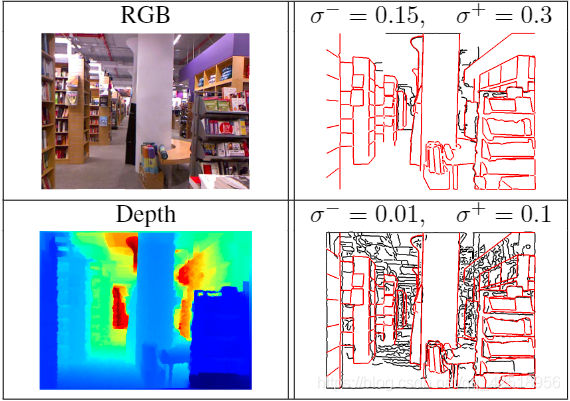
图4:NYUv2-Depth的RGB-D采样,并手动对NYUv2-OC边缘进行标注(红线),黑色线是使用不同的Canny 检测器参数(σ −和 σ +分别表示低、高阈值)在ground truth Kinect-v1的边缘检测。自由度高检测器容易发现虚假边缘,而严格的则会失去很多真实边缘,于是采用手动标注方法。
3.2 损失函数
通过最小化以下损失函数对网络f的参数Θ进行估计:
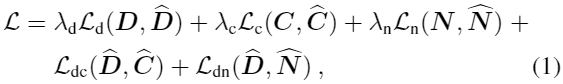
其中
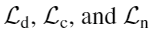 分别是深度、轮廓边缘、法向量的监督项,通过调节权重
分别是深度、轮廓边缘、法向量的监督项,通过调节权重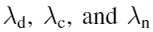 ,先对局部几何(法向量和边缘)调节,然后是深度
,先对局部几何(法向量和边缘)调节,然后是深度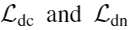 分别是估计的深度图与轮廓边缘(depth and contour)、以及深度图与法向量(depth and normal)之间的约束 所有的损失只在有效像素区计算,PBRS合成数据及提供了一个mask,当对NYUv2-Depth微调时,在图像边缘用Mask移出白色像素
分别是估计的深度图与轮廓边缘(depth and contour)、以及深度图与法向量(depth and normal)之间的约束 所有的损失只在有效像素区计算,PBRS合成数据及提供了一个mask,当对NYUv2-Depth微调时,在图像边缘用Mask移出白色像素
3.3 监督项
Depth prediction loss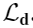
对深度估计采用log-distance(对数),使用BerHu 损失函数 [21, 40],在[18]中具有快速收敛的好结果
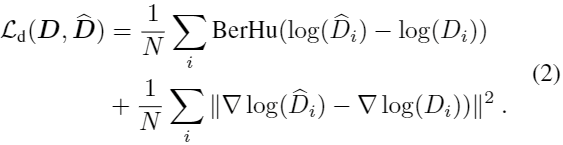
加和为所有的N个有效像素区,BerHu(也叫Huber)函数高阶导数用L2范数定义,低阶用L1,如[18]内,将BerHu函数的c参数取为:![]()
Occluding contours prediction loss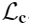
使用[29]中的attention loss,用来进行2D边缘检测来学习轮廓边缘,这种loss有助于处理边缘像素相对于非边缘像素的不平衡: 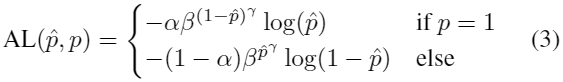
其中![]() 是设置为(4,0.5)的超参数,
是设置为(4,0.5)的超参数,![]() 用来计算每张图中轮廓所占比例,使用这个pixel-wise的attention loss来定义边缘估计损失:
用来计算每张图中轮廓所占比例,使用这个pixel-wise的attention loss来定义边缘估计损失: 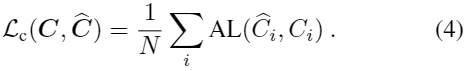
这个损失在调节NYUv2-Depth时不可用
Normals prediction loss
对于法向量估计,使用Eigen[5]的方法,对所有有效像素i 最小化法向量![]() 以及ground truth的
以及ground truth的![]() 的角度。通过最大化它们的dot-product(点积,角度越小 cos越大)来最小化角度:
的角度。通过最大化它们的dot-product(点积,角度越小 cos越大)来最小化角度:
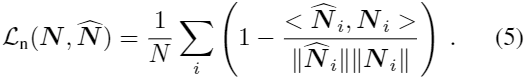
与[5]不同,这个损失仅限于正值
3.4 一致项 和
和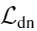
Depth-contours consensus term
为了使网络对明显深度不连续的轮廓能预测出明显边缘,提出以下loss在估计的轮廓概率图![]() 和深度图
和深度图![]() 之间:
之间:
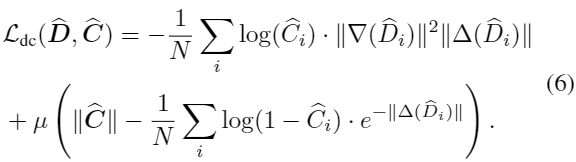
这将使网络将具有大深度梯度的像素点与边缘相连:除非该区域的轮廓概率接近1,否则高梯度区域会造成大loss。[10 Godard, 13]也使用这样的edge-aware gradient-loss,尽管他们用来加强的是光度梯度和深度梯度之间的一致性。但是依赖于光度梯度很危险,纹理区域可以表现出较强的光度梯度,但深度梯度不大。
Depth-normals consensus loss
由于深度和法向量高度相关,因此在法向量和深度预测之间加强几何一致性:
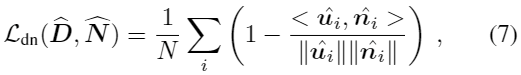
其中![]() 是从3D向量
是从3D向量![]() 提取出来的,
提取出来的,![]() 是使用有限差分的深度图的2阶梯度。此约束项比之前的更简单,因为之前的方法需要在3D世界坐标进行约束,必须进行相机标定。本约束只需假设正交投影成立,这是一个很好的一阶假设[32]。 在finetuning期间施加这个约束允许我们约束法线和深度,即使ground truth的法线N不可用。
是使用有限差分的深度图的2阶梯度。此约束项比之前的更简单,因为之前的方法需要在3D世界坐标进行约束,必须进行相机标定。本约束只需假设正交投影成立,这是一个很好的一阶假设[32]。 在finetuning期间施加这个约束允许我们约束法线和深度,即使ground truth的法线N不可用。

















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









