







一、逻辑回归的函数集
上一篇讲到分类问题的解决方法,推导出函数集的形式为:
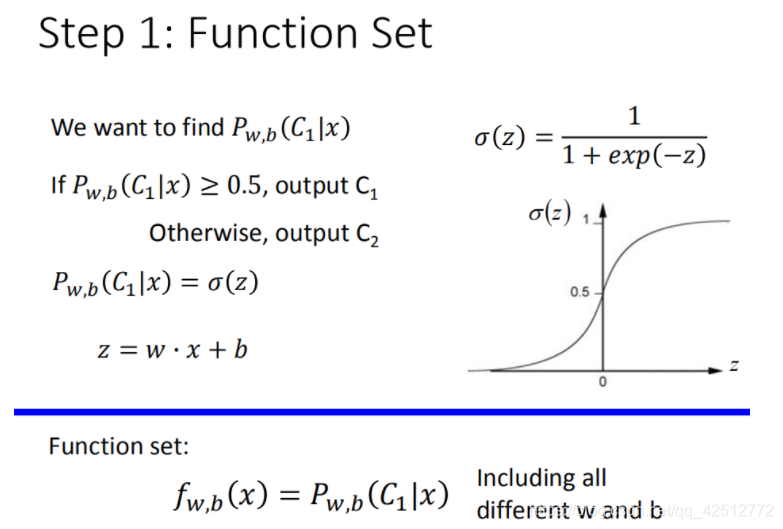
将函数集可视化:
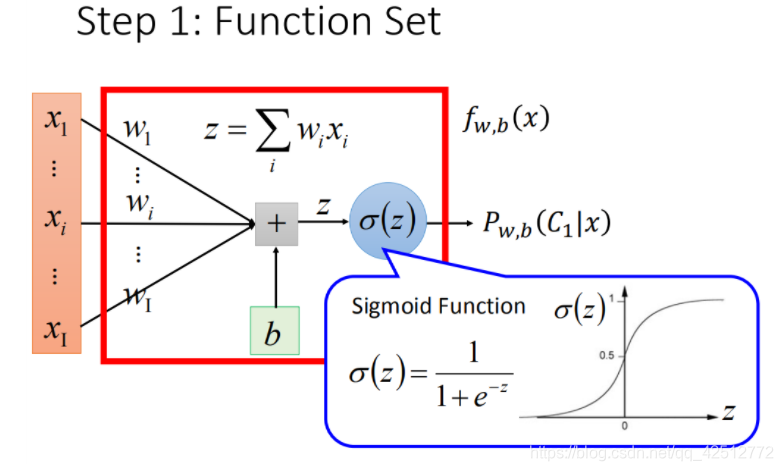
这种函数集的分类问题叫做Logistic Regression(逻辑回归)。
二、定义损失函数
如下图所示,每个对象分别对应属于哪个类型(例如
x
3
x^3
x3属于
C
2
C_2
C2 )。假设这些数据都是由后验概率
f
w
,
b
(
x
)
=
P
w
,
b
(
C
1
∣
x
)
\mathrm{f}_{\mathrm{w}}, \mathrm{b}(\mathrm{x})=\mathrm{P}_{\mathrm{w}, \mathrm{b}}\left(\mathrm{C}_{1} \mid \mathrm{x}\right)
fw,b(x)=Pw,b(C1∣x)产生的。
给定一组 w和b,就可以计算这组w,b下产生上图N个训练数据的概率,
L
(
w
,
b
)
=
f
w
,
b
(
x
1
)
f
w
,
b
(
x
2
)
(
1
−
f
w
,
b
(
x
3
)
)
⋯
f
w
,
b
(
x
N
)
\mathrm{L}(\mathrm{w}, \mathrm{b})=\mathrm{f}_{\mathrm{w}, \mathrm{b}}\left(\mathrm{x}^{1}\right) \mathrm{f}_{\mathrm{w}, \mathrm{b}}\left(\mathrm{x}^{2}\right)\left(1-\mathrm{f}_{\mathrm{w}, \mathrm{b}}\left(\mathrm{x}^{3}\right)\right) \cdots \mathrm{f}_{\mathrm{w}, \mathrm{b}}\left(\mathrm{x}^{\mathrm{N}}\right)
L(w,b)=fw,b(x1)fw,b(x2)(1−fw,b(x3))⋯fw,b(xN)
对于使L(w,b)最大的w和b,记作
w
∗
w^*
w∗和
b
∗
b^*
b∗,即:
w
∗
,
b
∗
=
argmax
w
,
b
L
(
w
,
b
)
\mathrm{w}^{*}, \mathrm{~b}^{*}=\operatorname{argmax}_{\mathrm{w}, \mathrm{b}} \mathrm{L}(\mathrm{w}, \mathrm{b})
w∗, b∗=argmaxw,bL(w,b)
将训练集数字化,并将上式求max通过取自然对数转化为求min:

图中蓝色下划线实际上代表的是两个伯努利分布(0-1分布,两点分布)的 cross entropy(交叉熵)。
假设有两个分布p和q,如图中蓝色方框所示,这两个分布之间交叉熵的计算方式就是 H(p,q);交叉熵代表的含义是这两个分布有多接近,如果两个分布是一模一样的话,那计算出的交叉熵就是熵。
三、寻找最好的函数
根据链式求导法则,利用梯度法求:
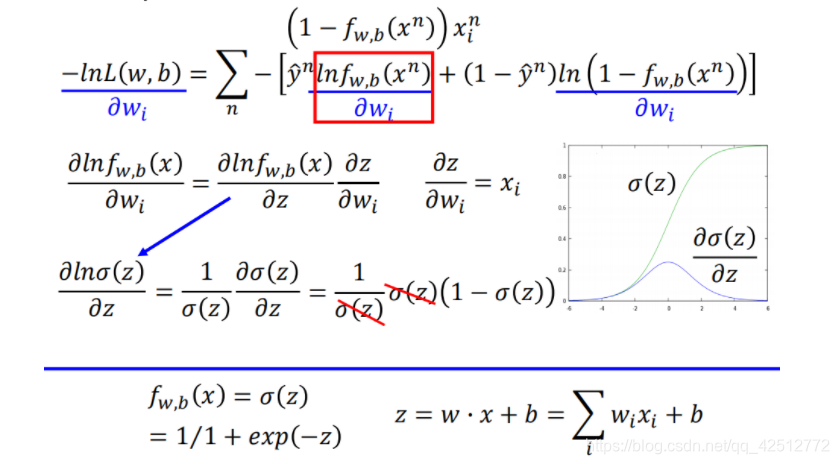
计算
ln
(
1
−
f
w
,
b
(
x
n
)
)
\ln \left(1-f_w, b\left(x_{n}\right)\right)
ln(1−fw,b(xn)) 的对
w
i
w_i
wi偏微分
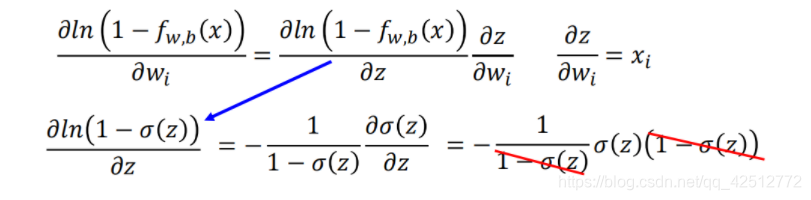
将求得两个子项的偏微分带入,化简得到结果。

现在
w
i
w_i
wi 的更新取决于学习率 η ,
x
i
n
x^n_i
xin 以及上图的紫色划线部分;紫色下划线部分直观上看就是真正的目标
y
n
y^n
yn与我们的function差距有多大。
下面再拿逻辑回归和线性回归作比较,这次比较如果挑选最好的function:

对于逻辑回归,target
y
n
y^n
yn是0或者1,输出是介于0和1之间。而线性回归的target可以是任何实数,输出也可以是任何值。
损失函数:为什么不学线性回归用平方误差?
在logistic回归中采用平方误差形式。在step3计算出了对
w
i
w_i
wi的偏微分。假设
y
n
y^n
yn=1 ,如果
f
w
,
b
(
x
n
)
f_w,_b(x_n)
fw,b(xn)=1,就是非常接近target,会导致偏微分中第一部分为0,从而偏微分为0;而
f
w
,
b
(
x
n
)
f_w,_b(x_n)
fw,b(xn)=0,会导致第二部分为0,从而偏微分也是0。如下图所示。

根据得到的结果分析,针对两个参数的变化,对总的损失函数作图:
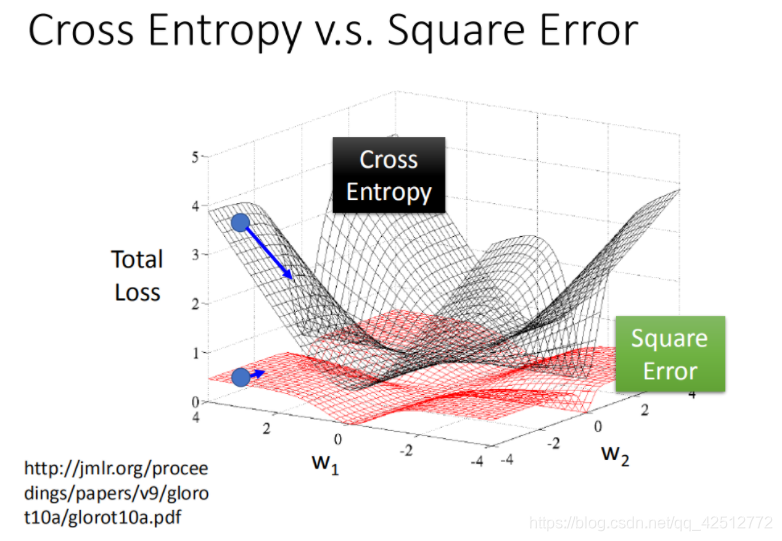
如果是交叉熵,距离target越远,微分值就越大,就可以做到距离target越远,更新参数越快。而平方误差在距离target很远的时候,微分值非常小,会造成移动的速度非常慢,这就是很差的效果了。所以在logistic回归中采用交叉熵的思想。
四、判别模型 VS 生成模型
逻辑回归的方法称为Discriminative(判别) 方法;上一篇中用高斯来描述后验概率,称为 Generative(生成) 方法。它们的函数集都是一样的:

如果是逻辑回归,就可以直接用梯度下降法找出w和b;如果是概率生成模型,像上篇那样求出
μ
1
,
μ
2
μ^1,μ^2
μ1,μ2,协方差矩阵的逆,然后就能算出w和b。但是用逻辑回归和概率生成模型找出来的w和b是不一样的。
判别方法不一定比生成方法好
对于判别方法来说,其没有做出任何假设,只是根据训练集来计算,训练集数据量越大时所出现的error越小;而对于生成方法而言,它能够自我脑补,受到数据量的影响较小。因此在在训练集数据量很小的情况下,一般选用生成方法比较好。
五、多类别分类
Softmax
其所要做的事情就是将原本输入特征值差异不大的数据中的最大值进行强化,其输出就是用来估计后验概率(Posterior Probability)。
假设有3个类别,每个都有自己的weight和bias:
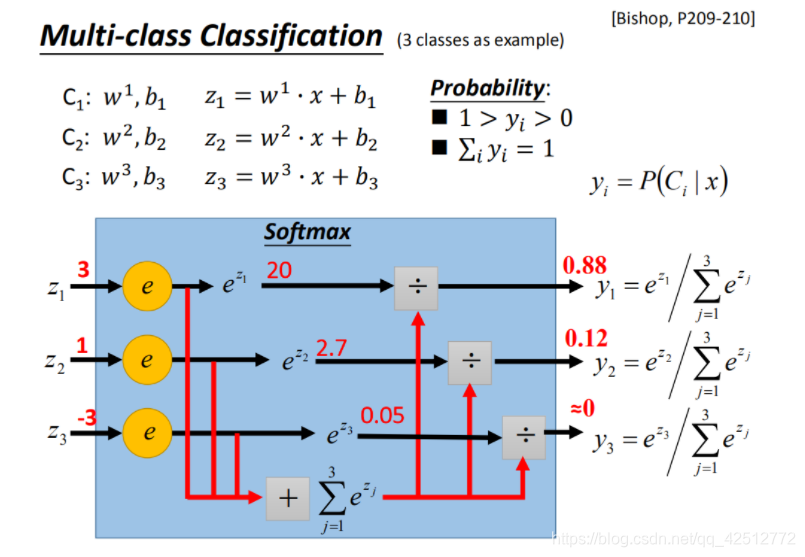
把
z
1
,
z
2
,
z
3
z_1,z_2,z_3
z1,z2,z3放到一个叫做Softmax的方程中,Softmax做的事情就是它们进行exponential(指数化),将exponential 的结果相加,再分别用 exponential 的结果除以相加的结果。原本
z
1
,
z
2
,
z
3
z_1,z_2,z_3
z1,z2,z3可以是任何值,但做完Softmax之后输出会被限制住,都介于0到1之间,并且和是1。
如上图所示,输入x,属于类别1的几率是0.88,属于类别2的几率是0.12,属于类别3的几率是0。
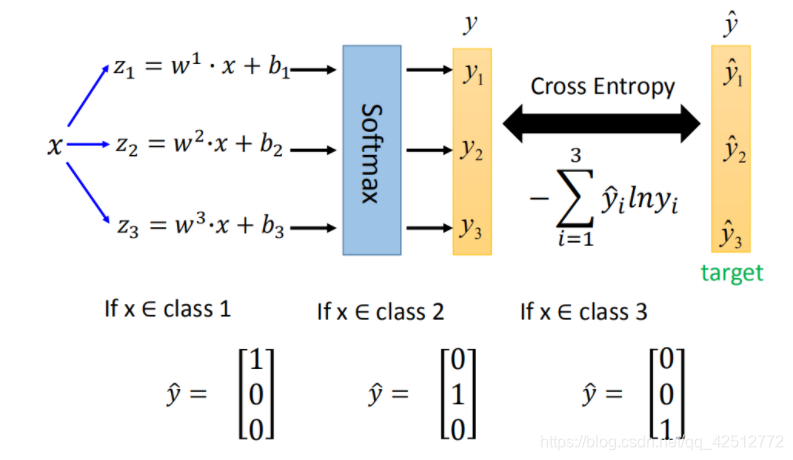
定义target
将
y
^
\hat{y}
y^定义为矩阵,且为了方便计算交叉熵。
六、逻辑回归的限制
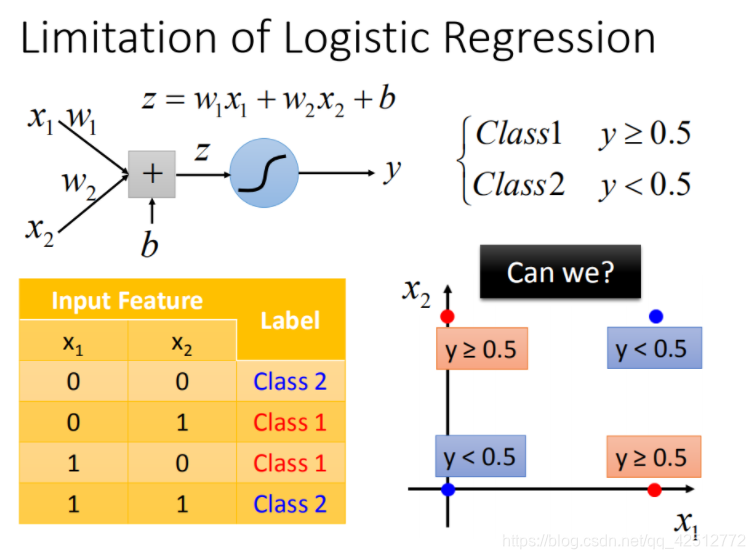
根据上图右下角得到的结果,两个类别分布分别在两个对角线的两端,当我们使用逻辑回归处理时,逻辑回归所能做的分界线就是一条直线,没有办法很好的将两个类别用一条直线分开。如下图所示。
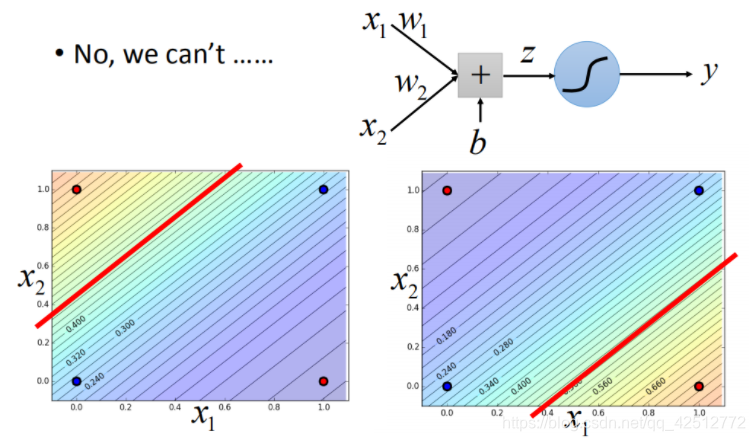
特征转换
特征转换的方式很多,举例类别1转化为某个点到 (0,0)(0,0) 点的距离,类别2转化为某个点到 (1,1)(1,1) 点的距离。然后问题就转化右图,此时就可以处理了。
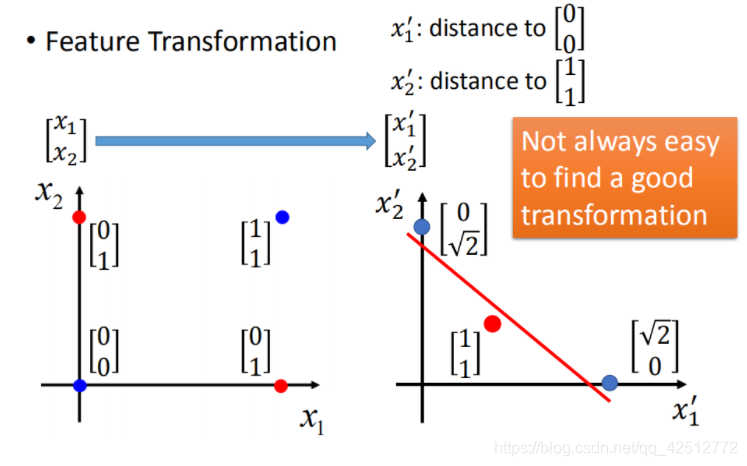
但是实际中并不是总能轻易的找到好的特征转换的方法。
七、级联逻辑回归模型
可以将很多的逻辑回归接到一起,就可以进行特征转换。比如下图就用两个逻辑回归 对
z
1
,
z
2
z_1,z_2
z1,z2来进行特征转换,然后对于
x
1
′
,
x
2
′
x_1^{'},x_2^{'}
x1′,x2′,再用一个逻辑回归z来进行分类。
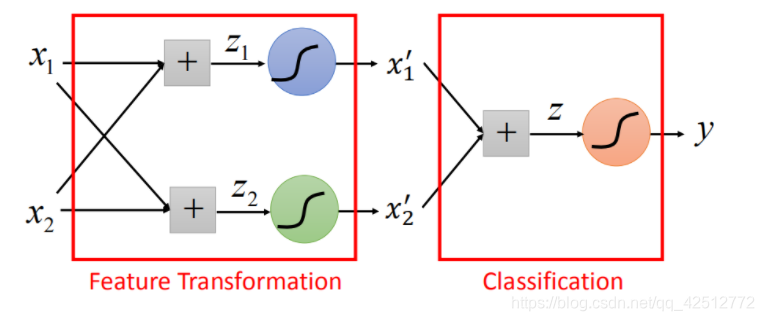
对上图进行处理,
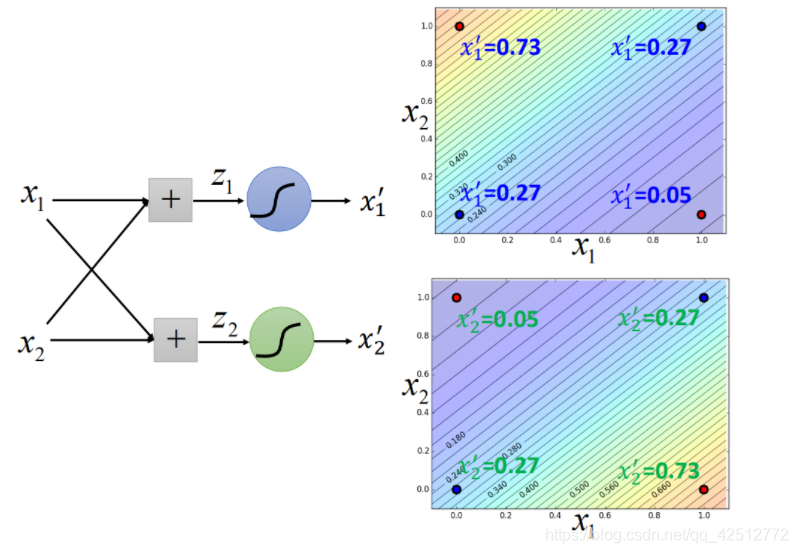
对上面右图调整参数,进行特征变换:
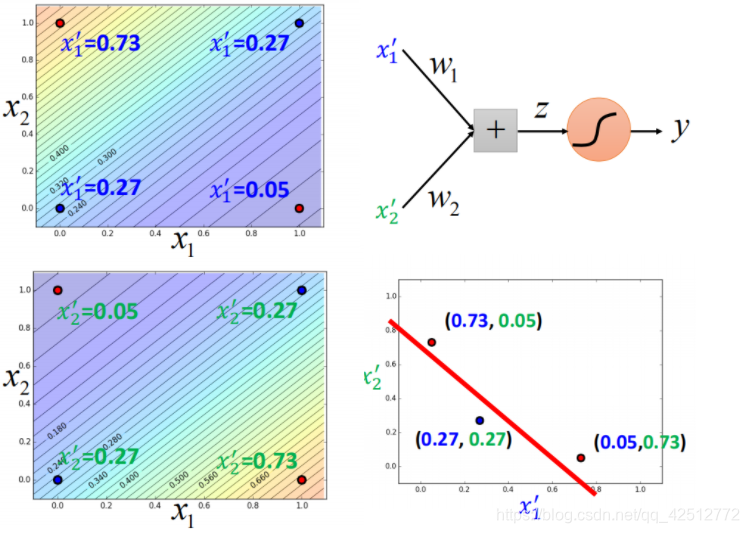
由右下角的图所得到的结果,每个点就被处理为可分类的结果。
八、Deep Learning
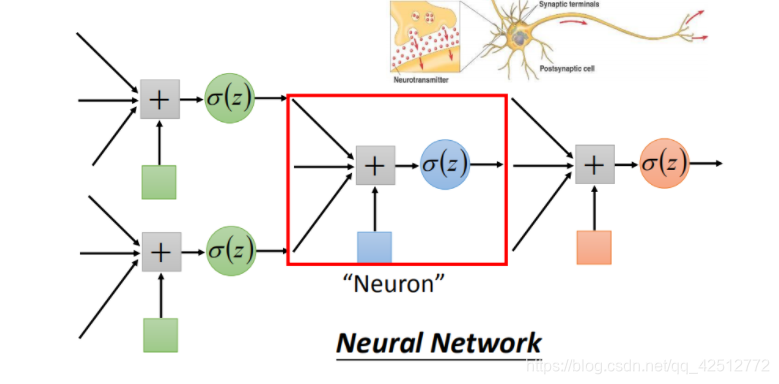
一个逻辑回归的输入可以来源于其他逻辑回归的输出,这个逻辑回归的输出也可以是其他逻辑回归的输入。把每个逻辑回归称为一个 Neuron(神经元),把这些神经元连接起来的网络,就叫做 Neural Network(神经网络)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









