










作业???排序???作业和排序有啥关系?
本人第一次听到这个名词也是一脸懵,下面将作业排序简单介绍一下。
问题介绍
“作业”指的并不是传统意义上的作业,而是指一个具有最后期限并且具有一定效益的工作。
那么,这个具体解决的问题是什么呢?
比如说在三天内,有三个作业,用p[i]和d[i]分别表示三个作业的效益值和最后的截止期限。
比如p[1]=10,d[1]=1 p[2]=15,d[2]=3 p[3]=20,d[3]=1。然后问你怎么安排三个作业的顺序来保证可以获得最大的效益值。
那么我们接下来分析一下解决问题的过程,我们先将每个作业的截止期限按照从大到小的顺序排序,可以看到分别为
d[2],d[1],d[3]。我们可以简单的发现d[1]和d[3]是一样的,然后可以比较一下p[1]和p[3]之间的大小,因为p[3]>p[1],所以我们取作业3。
最后放到作业顺序队列里面的顺序是 作业3 作业2,可以获得的总效益是20+15=35。
具体例子
一共有7个作业,即n=7,(p1,p2,p3,p4,p5,p6,p7)=(35,30,25,20,15,10,5)和(d1,d2,d3,d4,d5,d6,d7)=(4,2,4,3,4,8,3)。
一开始只用了一般的排序思路,发现当数据达到一定值的时候,运行的时间会变得很大很大,整体的代码可行性大大降低。
在不断踩坑之后,想到了用并查集来对作业进行连接,可以将复杂度大大降低。
直接上代码吧!!!
#include<iostream>
#include<algorithm>
#include<string.h>
#include<cstdio>
#include<vector>
#define ll long long
using namespace std;
const int maxn = 1e5;
int n;//输入总的作业数目
int counter;//计数
int pre[maxn];//根节点
int res[maxn];
ll sum;
struct node {
int p, d;
bool operator<(const node&t)const { //重载一下运算符
return p > t.p;
}
}point[maxn];
//用并查集查找并且压缩路径
int find(int i) {
int x = i;
if (pre[x] != x) {
pre[x] = find(pre[x]);
}
return pre[x];
}
void connect(int i, int j) {
int x = find(i);
int y = find(j);
if (x != y) {
pre[y] = x;
}
}
void fjs() {
for (int i = 0; i <= n; ++i) {
pre[i] = i;
}
counter = 0; sum = 0;
for (int i = 1; i <= n; ++i) {
int j = find(min(n, point[i].d));
if (pre[j]) {
++counter;
res[counter] = i;
sum+=point[res[counter]].p;
int k = find(pre[j] - 1);
connect(k, j);
pre[j] = pre[k];
}
}
}
int main() {
while(cin>>n&&n){
int _p, _d;
for (int i = 1; i <= n; ++i) {
cin >> _p >> _d;
point[i].p = _p; point[i].d = _d;
}
sort(point + 1, point + n + 1); //把效益值从大到小排序
fjs();
cout << "需要处理的作业总数是 " << counter << endl;
cout << "需要处理的作业分别是 ";
for (int i = 1; i <= counter; ++i) {
if (i == counter) {
cout << res[i] << endl;
}
else {
cout << res[i] << " ";
}
}
cout << "获得的总效益是" << sum << endl << endl;
}
}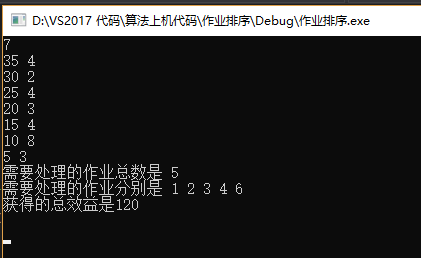
用这个算法可以将需要处理的作业数目和处理的顺序以及可以获得的最大效益值求出来!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











