







 本文涉及了多种数值计算方法,包括使用共轭梯度法解决线性方程组,最小二乘法进行多项式拟合,以及牛顿法和Broyden法求解非线性方程组。同时,文章还探讨了一个基于RCTV正则化的混合噪声去噪模型,利用ADMM优化算法进行求解,旨在提供高效且鲁棒的信号处理方案。
本文涉及了多种数值计算方法,包括使用共轭梯度法解决线性方程组,最小二乘法进行多项式拟合,以及牛顿法和Broyden法求解非线性方程组。同时,文章还探讨了一个基于RCTV正则化的混合噪声去噪模型,利用ADMM优化算法进行求解,旨在提供高效且鲁棒的信号处理方案。
实验一:共轭梯度法求解线性方程组
实验题目
用共轭梯度法求解线性方程组
A
x
=
b
Ax = b
Ax=b,其中:
A
=
[
2
−
1
−
1
2
−
1
⋯
⋯
⋯
−
1
2
−
1
−
1
2
]
A = \left[ \begin{array}{c} 2 & -1 & & & \\ -1 & 2 & -1 & & \\ & \cdots & \cdots & \cdots \\ & & -1 & 2 & -1\\ & & & -1 & 2 \end{array} \right]
A=
2−1−12⋯−1⋯−1⋯2−1−12
b
=
[
1
0
⋮
0
1
]
b = \left[ \begin{array}{c} 1 \\ 0 \\ \vdots \\ 0 \\ 1 \end{array} \right]
b=
10⋮01
矩阵A的阶数取100,指出计算结果是否可靠
实验代码
clear;
clc;
N=100;
a0=eye(N);
a1=eye(N-1);
a11=diag(a1);
a12=diag(a11,1);
A=a12'+a12+(-2)*a0;
A = -A;
b=zeros(N,1);
b(1)=-1;
b(N)=-1;
b = -b;
x=inv(A)*b;
x=zeros(N,1);
eps=0.0000001;
r=b-A*x;
d=r;
for k=0:N-1
a=(norm(r)^2)/(d'*A*d);
x=x+a*d;
rr=b-A*x;
if (norm(rr)<=eps)||(k==N-1)
break;
end
B=(norm(rr)^2)/(norm(r)^2);
d=rr+B*d;
r=rr;
end
x
实验结果
b
=
[
1
1
⋮
1
1
]
b = \left[ \begin{array}{c} 1 \\ 1 \\ \vdots \\ 1 \\ 1 \end{array} \right]
b=
11⋮11

实验二:用最小二乘法多项式
实验题目
给定数据如下表所示,求其最小二乘拟合四次多项式及其误差:
| x i x_i xi | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 |
|---|---|---|---|---|---|---|---|---|---|
| y i y_i yi | 5.1234 | 5.3057 | 5.5687 | 5.9375 | 6.4370 | 7.0978 | 7.9493 | 9.0253 | 10.3627 |
实验代码
import matplotlib.pyplot as plt
import numpy
fig = plt.figure()
ax = fig.add_subplot(111)
# 设置拟合阶数
order = 4
# 生成曲线上的各个点
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
y = [5.1234, 5.3057, 5.5687, 5.9375, 6.4370, 7.0978, 7.9493, 9.0253, 10.3627]
i = 0
xa = []
ya = []
for xx in x:
yy = y[i]
i += 1
xa.append(xx)
ya.append(yy)
ax.plot(xa, ya, color='m', linestyle='', marker='.')
# 进行曲线拟合
matA = []
for i in range(0, order + 1):
matA1 = []
for j in range(0, order + 1):
tx = 0.0
for k in range(0, len(xa)):
dx = 1.0
for _ in range(0, j + i):
dx = dx * xa[k]
tx += dx
matA1.append(tx)
matA.append(matA1)
matA = numpy.array(matA)
matB = []
for i in range(0, order + 1):
ty = 0.0
for k in range(0, len(xa)):
dy = 1.0
for _ in range(0, i):
dy = dy * xa[k]
ty += ya[k] * dy
matB.append(ty)
matB = numpy.array(matB)
matAA = numpy.linalg.solve(matA, matB)
# 画出拟合后的曲线
xxa = numpy.arange(0, 1, 0.01)
yya = []
for i in range(0, len(xxa)):
yy = 0.0
for j in range(0, order + 1):
dy = 1.0
for k in range(0, j):
dy *= xxa[i]
dy *= matAA[j]
yy += dy
yya.append(yy)
ax.plot(xxa, yya, color='g', linestyle='-', marker='')
plt.show()
print(f'方程系数:{matAA}')
实验结果
方程系数:[5.00097222 0.99268907 2.01064782 3.00333463 0.99096737]

拟合多项式曲线
实验三:牛顿法求解方程组
实验题目
使用牛顿法求解下列方程组的解:
k
=
{
x
1
2
+
x
2
2
+
x
3
2
−
1.0
=
0
2
x
1
2
+
x
2
2
−
4
x
3
=
0
3
x
1
2
−
4
x
2
2
+
x
3
2
=
0
\begin{equation*} k = \begin{cases} x_1^2 + x_2^2 + x_3^2 - 1.0 = 0 \\ 2x_1^2 + x_2^2 - 4x_3 = 0 \\ 3x_1^2 - 4x_2^2 + x_3^2 = 0 \end{cases} \end{equation*}
k=⎩
⎨
⎧x12+x22+x32−1.0=02x12+x22−4x3=03x12−4x22+x32=0
给定初始向量
x
(
0
)
=
(
1.0
,
1.0
,
1.0
)
T
x^{(0)} = (1.0, 1.0, 1.0)^T
x(0)=(1.0,1.0,1.0)T
实验代码
import numpy as np
def Nonlinear_equation_sets_value(x0):
x0 = np.transpose(x0)
# 构造矩阵f
f = np.zeros(shape=(3, 1))
f_row0 = [x0[0, 0] ** 2 + x0[0, 1] ** 2 + x0[0, 2] ** 2 - 1]
f_row1 = [2 * x0[0, 0] ** 2 + x0[0, 1] ** 2 - 4 * x0[0, 2]]
f_row2 = [3 * x0[0, 0] ** 2 + -4 * x0[0, 1] ** 2 + x0[0, 2] ** 2]
f[0] = f_row0
f[1] = f_row1
f[2] = f_row2
value = f
return value
def Newton(x0, J, alpha):
x_next = np.linalg.solve(J, -Nonlinear_equation_sets_value(x0)) + x0
value = Nonlinear_equation_sets_value(x_next)
error = ((value[0, 0]) ** 2 + (value[1, 0]) ** 2 + (value[2, 0]) ** 2) ** (1 / 2)
k = 1
while error >= alpha:
k += 1
x_next = np.linalg.solve(J, -Nonlinear_equation_sets_value(x_next)) + x_next
value = Nonlinear_equation_sets_value(x_next)
error = ((value[0, 0]) ** 2 + (value[1, 0]) ** 2 + (value[2, 0]) ** 2) ** (1 / 2)
print('total_iteration_times:', k)
print('error:', error)
print('x* =', x_next)
if __name__ == '__main__':
x0 = np.array([[1.0], [1.0], [1.0]])
eps = 1e-10
J = np.zeros(shape=(3, 3))
J_row0 = [2 * x0[0, 0], 2 * x0[1, 0], 2 * x0[2, 0]]
J_row1 = [4 * x0[0, 0], 2 * x0[1, 0], -4]
J_row2 = [6 * x0[0, 0], -8 * x0[1, 0], 2 * x0[2, 0]]
J[0] = J_row0
J[1] = J_row1
J[2] = J_row2
Newton(x0, J, eps)
实验结果

实验四:Broyden法求解方程组
实验题目
使用Broyden法求解下列方程组的解:
k
=
{
x
1
2
+
x
2
2
+
x
3
2
−
1.0
=
0
2
x
1
2
+
x
2
2
−
4
x
3
=
0
3
x
1
2
−
4
x
2
2
+
x
3
2
=
0
\begin{equation*} k = \begin{cases} x_1^2 + x_2^2 + x_3^2 - 1.0 = 0 \\ 2x_1^2 + x_2^2 - 4x_3 = 0 \\ 3x_1^2 - 4x_2^2 + x_3^2 = 0 \end{cases} \end{equation*}
k=⎩
⎨
⎧x12+x22+x32−1.0=02x12+x22−4x3=03x12−4x22+x32=0
给定初始向量
x
(
0
)
=
(
1.0
,
1.0
,
1.0
)
T
x^{(0)} = (1.0, 1.0, 1.0)^T
x(0)=(1.0,1.0,1.0)T
实验代码
import numpy as np
def Nonlinear_equation_sets_value(x0):
x0 = np.transpose(x0)
# 构造矩阵f
f = np.zeros(shape=(3, 1))
f_row0 = [x0[0, 0] ** 2 + x0[0, 1] ** 2 + x0[0, 2] ** 2 - 1]
f_row1 = [2 * x0[0, 0] ** 2 + x0[0, 1] ** 2 - 4 * x0[0, 2]]
f_row2 = [3 * x0[0, 0] ** 2 + -4 * x0[0, 1] ** 2 + x0[0, 2] ** 2]
f[0] = f_row0
f[1] = f_row1
f[2] = f_row2
value = f
return value
def Broyden(x0, J, eps):
A = J
A_inv = np.linalg.inv(A)
x_next = x0 - np.dot(A_inv, Nonlinear_equation_sets_value(x0))
value = Nonlinear_equation_sets_value(x_next)
error = ((value[0, 0]) ** 2 + (value[1, 0]) ** 2 + (value[2, 0]) ** 2) ** (1 / 2)
k = 1
while error >= eps:
k += 1
s = x_next - x0
y = Nonlinear_equation_sets_value(x_next) - Nonlinear_equation_sets_value(x0)
A_inv = A_inv + ((np.dot(np.dot((s - np.dot(A_inv, y)), np.transpose(s)), A_inv)) / np.dot(
np.dot(np.transpose(s), A_inv), y))
x_next = x_next - np.dot(A_inv, Nonlinear_equation_sets_value(x_next))
value = Nonlinear_equation_sets_value(x_next)
error = ((value[0, 0]) ** 2 + (value[1, 0]) ** 2 + (value[2, 0]) ** 2) ** (1 / 2)
print('total_iteration_times:', k)
print('error:', error)
print('x* =', x_next)
if __name__ == '__main__':
x0 = np.array([[1.0], [1.0], [1.0]])
eps = 1e-10
J = np.zeros(shape=(3, 3))
J_row0 = [2 * x0[0, 0], 2 * x0[1, 0], 2 * x0[2, 0]]
J_row1 = [4 * x0[0, 0], 2 * x0[1, 0], -4]
J_row2 = [6 * x0[0, 0], -8 * x0[1, 0], 2 * x0[2, 0]]
J[0] = J_row0
J[1] = J_row1
J[2] = J_row2
Broyden(x0, J, eps)
实验结果

实验五:关于实际工程问题的计算
提出的模型
我们提出了基于噪声建模的去噪模型。真实的HSI中的噪声结构总是非常复杂。之前有一些关于噪声分布建模的工作,例如混合高斯(MoG) 、和混合拉普拉斯。
具体来说,真实HSI中的噪声结构可以大致分为两种类型。一类是稀疏噪声,如条纹噪声、截止日期和丢失像素,另一类是高斯噪声。在这里,我们简单地使用1-范数和2-范数来分别表征稀疏和高斯噪声,这类似于LRTDTV 和LRTFDFR 中的建模机制。根据RCTV(6)的定义,我们提出基于RCTV正则化的去噪模型如下:
min
U
,
V
,
E
,
S
∑
i
=
1
2
τ
i
∣
∇
i
(
U
)
∣
1
+
β
∣
E
∣
F
2
+
λ
∣
S
∣
1
s
.
t
.
Y
=
U
V
T
+
E
+
S
,
V
T
V
=
I
\min_{U, V, E, S}{\sum_{i = 1}^2{\tau_i | \nabla_i(U)|_1 + \beta|E|^2_F + \lambda|S|_1}} \\ s.t. Y = UV^T + E + S, V^TV = I
U,V,E,Smini=1∑2τi∣∇i(U)∣1+β∣E∣F2+λ∣S∣1s.t.Y=UVT+E+S,VTV=I
其中,
τ
i
\tau_i
τi、
β
\beta
β和
λ
\lambda
λ是权衡参数,用于平衡目标中各项的权重。
值得注意的是,所提出的RCTV正则化在一定程度上对噪声具有鲁棒性,并且能够充分捕捉代表系数矩阵U的空间信息。因此,该模型有望具有很强的混合噪声去除能力。由于U的大小远低于原始的HSI数据X,因此该模型的时间复杂度预计较低。因此,该模型有望为混合噪声去除带来稳健和快速的去噪结果。
优化算法
通过引入辅助变量 G 1 , G 2 G_1, G_2 G1,G2我们将模型重写为以下等价公式:
min U , V , E , S ∑ i = 1 2 τ i ∣ ∇ i ( U ) ∣ 1 + β ∣ E ∣ F 2 + λ ∣ S ∣ 1 s . t . ∇ i ( U ) = G i , i = 1 , 2 Y = U V T + E + S , V T V = I \min_{U, V, E, S}{\sum_{i = 1}^2{\tau_i | \nabla_i(U)|_1 + \beta|E|^2_F + \lambda|S|_1}} \\ s.t. \nabla_i(U) = G_i, i = 1, 2 \\ Y = UV^T + E + S, V^TV = I U,V,E,Smini=1∑2τi∣∇i(U)∣1+β∣E∣F2+λ∣S∣1s.t.∇i(U)=Gi,i=1,2Y=UVT+E+S,VTV=I
然后,我们使用众所周知的交替方向乘子法(ADMM)来推导求解模型的有效算法。模型的扩充拉格朗日函数为:
L
(
U
,
V
,
E
,
S
,
{
G
}
i
=
1
2
,
{
Γ
i
}
i
=
1
3
)
:
=
∑
i
=
1
2
τ
i
∥
G
i
∣
1
+
μ
2
∑
i
=
1
2
∥
∇
i
(
U
)
−
G
i
+
Γ
i
μ
∥
F
2
+
β
∥
E
∥
F
2
+
λ
∥
S
∥
1
+
μ
2
∥
Y
−
U
V
T
−
E
−
S
+
Γ
3
μ
∥
F
2
,
\mathcal{L}(U, V, E, S, \{G\}^2_{i = 1}, \{\mathbf{\Gamma}_i\}^3_{i = 1}) :=\sum_{i=1}^2 \tau_i\| G_i |_1 \\ \quad +\frac{\mu}{2} \sum_{i=1}^2\| \nabla_i(U)- G_i + \frac{\mathbf{\Gamma}_i}{\mu}\|_F^2 + \beta \| E \|_{\scriptsize{F}}^2 + \lambda \| S \|_1 \\ \quad + \frac{\mu}{2} \| Y - UV^{\scriptsize{T}} -E -S + \frac{\mathbf{\Gamma}_3}{\mu}\|_F^2, \\
L(U,V,E,S,{G}i=12,{Γi}i=13):=i=1∑2τi∥Gi∣1+2μi=1∑2∥∇i(U)−Gi+μΓi∥F2+β∥E∥F2+λ∥S∥1+2μ∥Y−UVT−E−S+μΓ3∥F2,
其中
μ
\mu
μ是罚参数,而
{
Γ
i
}
i
=
1
3
\{\mathbf{\Gamma_i\}}_{i=1}^3
{Γi}i=13是拉格朗日乘数。然后我们讨论如何解决每个相关变量的子问题:
arg
min
G
i
τ
i
∥
G
i
∥
1
+
μ
2
∥
∇
i
(
U
)
−
G
i
+
Γ
i
μ
∥
F
2
.
\arg \min_{G_i} \tau_i \| G_i \|_1 + \frac{\mu}{2} \| \nabla_i (U) - G_i + \frac{\mathbf{\Gamma}_i}{\mu}\|_F^2.\\
argGiminτi∥Gi∥1+2μ∥∇i(U)−Gi+μΓi∥F2.
利用定义的软阈值算子S,我们得到:
G
i
=
S
τ
i
/
μ
(
∇
i
(
U
)
+
Γ
i
/
μ
)
.
G_i = \mathcal{S}_{\tau_i/\mu}\left( \nabla_i(U) + \mathbf{\Gamma_i}/\mu \right).\\
Gi=Sτi/μ(∇i(U)+Γi/μ).
更新V:固定除V之外的其他变量,我们有
max
V
T
V
=
I
⟨
(
Y
−
E
−
§
+
Γ
3
/
μ
)
T
U
,
V
⟩
.
\max_{V^{\textrm{T}}V=\mathbf{I}} \left\langle (Y-E-\S+\mathbf{\Gamma}_3/\mu)^{\scriptsize{T}}U,V \right\rangle.
VTV=Imax⟨(Y−E−§+Γ3/μ)TU,V⟩.
我们可以得到的解如下:
{
[
B
,
D
,
C
]
=
s
v
d
(
(
Y
−
E
−
S
+
Γ
3
/
μ
)
T
U
)
,
V
=
B
C
T
.
\left\{ \begin{split} \left[\mathbf{B},\mathbf{D},\mathbf{C}\right]= {svd}( (Y-E-S+\mathbf{\Gamma}_3/\mu)^{\scriptsize{{T}}}U ),\\ V=\mathbf{B}\mathbf{C}^{\textrm{T}}. \end{split} \right.
{[B,D,C]=svd((Y−E−S+Γ3/μ)TU),V=BCT.
其中对SVD的过程解释如下:
对矩阵作奇异值分解:
X
=
U
^
Σ
V
^
T
=
∑
k
=
1
B
σ
k
u
k
v
k
T
X = \hat{U}\mathbf{\Sigma}\hat{V}^{\textrm{T}} = \sum_{k=1}^B \sigma_k \mathbf{u_k} \mathbf{v_k}^{\textrm{T}}
X=U^ΣV^T=∑k=1BσkukvkT
即原始的矩阵可以通过两个或者多个比原始矩阵的行列数少的矩阵进行表示。“为了刻画矩阵的低秩性,比较常见的方法是用核范数,即上面的公式中奇异值的L1范数(即所有奇异值的加和)。奇异值需要用到SVD分解,而SVD的分解时间复杂度是很高的。此外矩阵数据除了低秩性,还有局部平滑性,一般的平滑性通过矩阵的TV 范数进行刻画,是直接加到原始数据X上面。本文证明了加到原始数据上的TV范数可以加到X的低秩分解后的稀疏矩阵U上面从而使得我们在利用正则来刻画原始数据的低秩性和局部平滑性的时候,避免直接在原始数据上操作,而是直接在U上面操作,U的尺寸远远小于X,这导致在U上面的定义TV正则会大幅度的提高模型的求解效率。
更新U:关于U求导,我们可以得到下面的线性系统:
(
μ
I
+
μ
∑
i
=
1
2
∇
i
T
∇
i
)
(
U
)
=
μ
(
Y
−
E
−
S
+
Γ
3
/
μ
)
V
+
∑
i
=
1
2
∇
i
T
(
μ
G
i
−
Γ
i
)
.
\left(\mu\mathbf{I}+\mu\sum_{i=1}^2\mathbf{\nabla}_i^{\scriptsize{{T}}}\mathbf{\nabla}_i\right)(U) = \mu(Y-E-S+\mathbf{\Gamma}_3/\mu)V\\ +\sum_{i=1}^2\mathbf{\nabla}_i^{\scriptsize{{T}}}\left(\mu G_i-\mathbf{\Gamma}_i\right).\\
(μI+μi=1∑2∇iT∇i)(U)=μ(Y−E−S+Γ3/μ)V+i=1∑2∇iT(μGi−Γi).
其中
∇
i
T
(
⋅
)
\mathbf{\nabla}_i^{\textrm{T}}(\cdot)
∇iT(⋅)表示
∇
i
(
⋅
)
{\nabla}_i(\cdot)
∇i(⋅)的“转置”运算符。将差分运算∇i(U)作为差分滤波器Di ⊗fold(U)的卷积,其中Di是相关差分滤波器,我们可以容易地采用FFT来有效地求解。具体而言,通过在方程的两侧执行傅立叶变换并采用卷积定理,可以容易地将U的封闭形式的解推导为
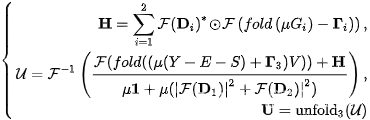
其中1表示所有元素都为1的张量,是元素式乘法,F()是傅立叶变换,而|·|^2是元素式平方运算。
更新E:提取包含E的所有项,我们可以得到
E
=
(
μ
(
Y
−
U
V
T
−
§
)
+
Γ
3
)
/
(
μ
+
2
β
)
.
E = (\mu(Y-UV^{\textrm{T}}-\S) +\mathbf{\Gamma}_3)/(\mu+2\beta).
E=(μ(Y−UVT−§)+Γ3)/(μ+2β).
更新S:提取中包含S的所有项,我们可以得到:
S
=
S
λ
/
μ
(
Y
−
U
V
T
−
E
+
Γ
3
/
μ
)
.
S = \mathcal{S}_{\lambda/\mu} (Y-UV^{\textrm{T}}-E+\mathbf{\Gamma}_3/\mu).
S=Sλ/μ(Y−UVT−E+Γ3/μ).
更新乘数:基于一般的ADMM原理,乘数通过以下等式进一步更新:
{
Γ
i
=
Γ
i
+
μ
(
∇
i
(
U
)
−
G
i
)
,
i
=
1
,
2
,
Γ
3
=
Γ
3
+
μ
(
Y
−
U
V
T
−
E
−
S
)
,
μ
=
μ
ρ
,
\left\{ \begin{split} \mathbf{\Gamma}_i &=\mathbf{\Gamma}_i+\mu\left(\nabla_i(U)-G_i\right),i=1,2,\\ \mathbf{\Gamma}_3&=\mathbf{\Gamma}_3+\mu\left(Y -UV^{\textrm{T}} - E -S \right), \\ \mu & = \mu\rho,\ \\ \end{split} \right.
⎩
⎨
⎧ΓiΓ3μ=Γi+μ(∇i(U)−Gi),i=1,2,=Γ3+μ(Y−UVT−E−S),=μρ,
其中ρ是大于1的常数值。
总结前面的描述,我们可以得到算法1。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











