







 本文详细介绍了数据仓库的五层架构,包括ODS原始数据层、DWD明细数据层、DWS服务数据层、DWT数据主题层和ADS数据应用层。各层功能和建模原则被阐述,强调了数据分层对于数据清洗、业务隔离和需求适应的重要性。
本文详细介绍了数据仓库的五层架构,包括ODS原始数据层、DWD明细数据层、DWS服务数据层、DWT数据主题层和ADS数据应用层。各层功能和建模原则被阐述,强调了数据分层对于数据清洗、业务隔离和需求适应的重要性。
1. 数据仓库五层架构规范
1.1 数据仓库为什么要分层
- 把复杂问题简单化,每一层只处理简单的任务,方便定位问题;
- 减少重复开发,规范数据分层,通过中间层数据能够减少重复计算,且增加计算结果的复用性;
- 隔离原始数据,不论是数据的异常还是数据的敏感性,使真实数据与统计数据解耦开。
1.2 DW五层架构的特点
- 细化DW建模,对DW中各个主题业务建模进行了细分,每个层次具有不同的功能。保留了最细粒度数据,满足了不同维度、不同事实的信息;
- 满足数据重新生产,不同层次的数据支持数据重新生成,无需备份恢复,解决了由不同故障带来的数据质量问题,消除了重新初始化数据的烦恼;
- 减少应用对DW的压力,以业务应用驱动为向导建模,避免直接操作基础事实表,降低数据获取时间;
- 快速适应需求变更和维度变化,明细基础数据层稳定,适应前端应用层业务需求变更,所有前端应用层模型之间不存在依赖,需求变更对DW整个模型影响范围小,能适应短周期内上线下线需求。
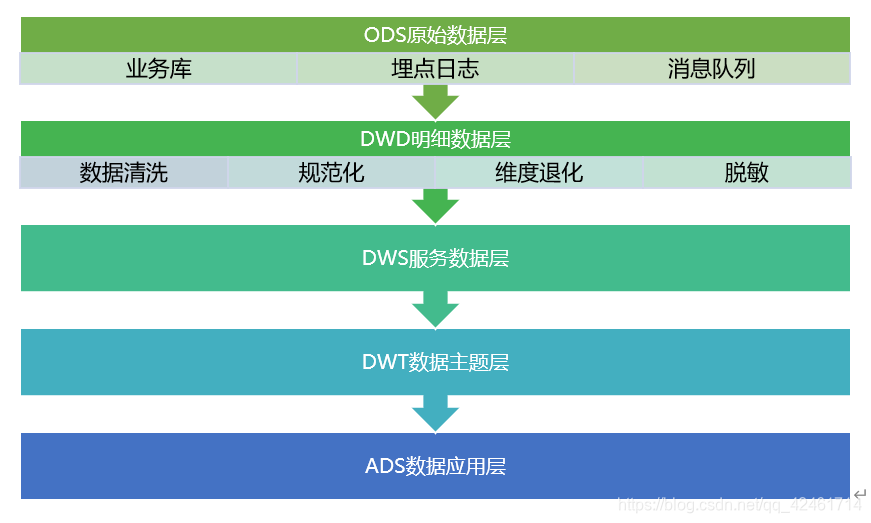
1.3 ODS(Operational Data Store)原始数据层
数据准备区,也称为贴源层。数据仓库源头系统的数据表通常会原封不动的存储一份,以此减少对业务系统的影响,也是后续数据仓库加工数据的来源。业务DB基本上是直接同步过来,LOG主要做结构化。
1.3.1 ODS层数据的来源方式
业务库
- 可使用Sqoop来抽取,例如每天定时抽取一次;
- 实时接入,考虑用canal监听MySQL的binlog;
- Flume、Sqoop、Kettle等ETL工具导入到HDFS,并映射到HIVE的数据仓库表中。
埋点日志
- 日志一般以文件的形式保存,可以选择用Flume定时同步;
- 可以用Spark Streaming或者Flink来实时接入;
- Kafka。
消息队列
- 来自ActiveMQ、Kafka的数据等。
1.3.2 建模方式及原则
- 从业务系统增量抽取;
- 保留时间由业务需求
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1414
1414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









