







 本文介绍了机器学习中的分类算法,包括KNN、朴素贝叶斯和决策树。讲解了数据集划分、转换器与估计器的概念,以及模型选择与调优的交叉验证和网格搜索方法。同时,讨论了KNN的优缺点和决策树的信息熵、信息增益。最后,提到了集成学习中的随机森林及其优势。
本文介绍了机器学习中的分类算法,包括KNN、朴素贝叶斯和决策树。讲解了数据集划分、转换器与估计器的概念,以及模型选择与调优的交叉验证和网格搜索方法。同时,讨论了KNN的优缺点和决策树的信息熵、信息增益。最后,提到了集成学习中的随机森林及其优势。
1.机器学习分类
监督学习:输入数据特征有标签(有标准答案),按照目标值离散还是连续又分为回归(目标值值连续 ),分类(目标值离散)
无监督学习:输入数据特征无标签值(无标准答案),聚类
2.数据集划分
机器学习一般将数据划分为两个部分:训练集、测试集
训练集:用来训练,构建模型
测试集:在模型检验的时候,评估模型的有效性
sklearn数据集划分API:sklearn.model.selection.train_test_split
sklearn数据集划分API介绍:
sklearn.datasets:加载获取流行数据集
datasets.load_*():读取小规模数据集,数据包含在datasets中
datasets.fetch_*(data_home=None):获取大规模数据集,需要从网上下载,datahome表示数据集下载目录
获取数据集返回的类型:
load*和fetch*返回的数据类型是datasets.base.Bunch(字典格式)
data:特征数据数组,类型是[n_samples*n_features]的二维numpy.ndarray数组
target:标签数组,是n_samples的一维numpy.ndarray数组
DESCR:数据描述
feature_names:特征名(新闻数据、手写数字、回归数据集没有)
target_names:标签名
数据集进行分割:sklearn.model.selection.train_test_split(*arrays,**options)
x:数据集的特征值
y:数据集的目标值
test_size:测试集的大小,一般为float
random_state:随机数种子,不同的种子会造成不同的随机采样结果,相同的种子结果相同
return:训练集特征值(x_train),测试集特征值(x_test),训练集目标值(x_test),测试集目标值(y_test)
3.转换器与估计器
转换器:fit_transform、fit、transform 的区别
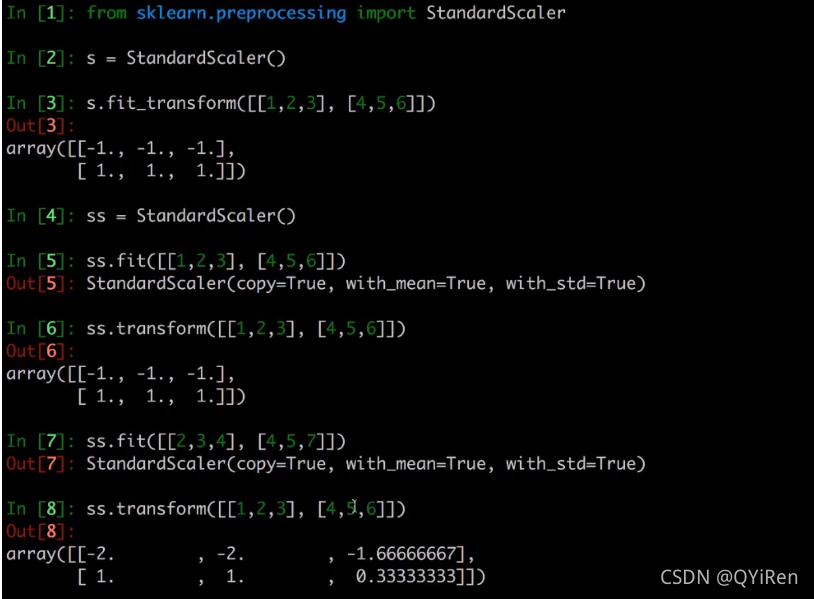
sklearn机器学习算法的实现——估计器(算法实现模型),一类实现了算法的API
1.用于分类的估计器
-sklearn.neighbors——KNN(k近邻算法)
-sklearn.naive_bayes——贝叶斯
-sklearn.linear_model.LogisticRegression——逻辑回归
-sklearn.tree——决策树与随机森林
2.用于回归的分类器
-sklearn.linear_model.LinearRegression——线性回归
-sklearn.linear_model.Ridge——岭回归
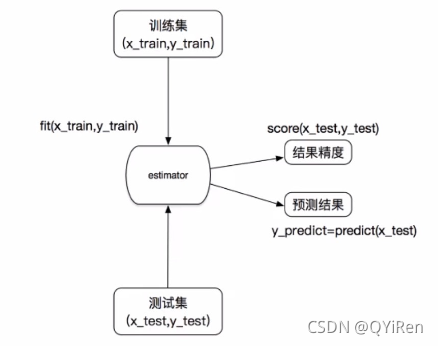
估计器的工作流程:
4.分类算法-KNN(k-近邻算法)
定义:如果一个样本在特征空间中的k个最邻近(距离:详见李航统计学习方法)的样本大多属于某一个类别,则该样本也属于这个类别
API:sklearn.neighbors.KNeighborsClassifier(n_neighbor=5,algorithm='auto')
demo:
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
def knncls():
"""
KNN预测用户签到位置
:return: None
"""
#读取数据
data = pd.read_csv("./train.csv")
# print(data.head(10))
#处理数据
#1.缩小数据,查询数据筛选
data = data.query("x>1.0 & x<1.25 &y>2.5 & y<2.75")
#处理时间的数据,将时间戳转化为标准时间格式1970-01-01 18:09:40
time_value = pd.to_datetime(data["time"],unit="s")
# print(time_value)
#把日期转换为字典格式,方便后边取出单独的值
time_value = pd.DatetimeIndex(time_value)
#构造一些特征,增加对预测结果有用的列数据
data["day"] = time_value.day
data["hour"] = time_value.hour
data["weekday"] = time_value.weekday
#把时间戳这个无用特征删除,删除一列
data = data.drop(["time"],axis=1)
# print(data)
#把签到数量少于3个的数据删除,没有参考意义
place_count = data.groupby("place_id").count()
# print(place_count)
tf = place_count[place_count.row_id>3].reset_index()
# print(tf)
# print(type(tf)) #<class 'pandas.core.frame.DataFrame'>
data = data[data["place_id"].isin(tf.place_id)]
#取出数据当中的特征值和目标值
y = data["place_id"]
x = data.drop(["place_id"],axis=1)
#进行数据集的划分,训练集和测试集,固定格式不可改变
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5942
5942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









