






 本文详细介绍了SpringBoot与Elasticsearch的整合过程,包括版本兼容性、ES的安装配置、Kibana的使用、索引操作、实体类映射、DAO层配置、批量数据插入、聚合查询等关键步骤,提供了丰富的代码示例。
本文详细介绍了SpringBoot与Elasticsearch的整合过程,包括版本兼容性、ES的安装配置、Kibana的使用、索引操作、实体类映射、DAO层配置、批量数据插入、聚合查询等关键步骤,提供了丰富的代码示例。
Springboot整合elasticsearch
springboot和elasticsearch版本对应关系
| Spring Boot Version (x) | Spring Data Elasticsearch Version (y) | x <= 1.3.5 |
|---|---|---|
| x <= 1.3.5 | y <= 1.3.4 | z <= 1.7.2* |
| x >= 1.4.x | 2.0.0 <=y < 5.0.0** | 2.0.0 <= z < 5.0.0** |
elasticsearch安装
一、ES的简介
在 Elasticsearch 中存储数据的行为就叫做 索引 (indexing)。
在 Elasticsearch 中,文档归属于一种类型(type),而这些类型存在于索引(index)中,一下是和传统关系型数据库的对比
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields
Elasticsearch集群可以包含多个
索引(indices)(数据库),每一个索引可以包含多个
类型(types)(表),每一个类型包含多个
文档(documents)(行),然后每个文档包含多个
字段(Fields)(列)。
二、ES的安装
1.环境信息
操作系统:centos7
jdk:1.8
Elasticsearch:6.7.2
2.安装步骤
(一)修改主机名
打开文件 /etc/hostname ,将内容改为node1)或其它
(二)修改hosts
打开 /etc/hosts 增加
10.10.10 node1
(三)修改linux 文件描述符限制
执行命令 ulimit -Hn,查看硬限制为:4096
执行命令 ulimit -Hn,查看硬限制为:4096
上述限制会导致 Elasticsearch启动失败,如下修改:打开 /etc/security/limits.conf,增加两行设置
* soft nofile 65536
* hard nofile 65536
(四)修改最大线程数
打开文件 /etc/security/limits.conf ,增加以下两行:
* soft nproc 4096
* hard nproc 4096
(五)修改内存限制
修改文件 /etc/sysctl.conf ,增加以下配置
vm.max_map_count=262144
(六)重启
(七)安装jdk
1、下载JDK,地址是:jdk下载地址,选择合适的版本下载(这里下载JDK1,8)

2、解压
tar -zxvf jdk_版本.tar.gz -C /usr/local
修改文件名
mv /usr/local/java_版本 /usr/local/java
3、配置JDK环境
vim /etc/profile 增加如下内容
export JAVA_HOME=/usr/local/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
4、执行 source /etc/profile 是JDK环境变量立即生效,执行 java -version 查看设置是否成功
(八)创建用户,给elasticsearch用户增加sudo权限
因为 Elasticsearch 不能用root用户启动,所以要创建新用户
1、创建用户(es)
执行命令:useradd es
修改用户密码:passwd es
2、给 es用户增加sudo权限
(1)赋予 /etc/sudoers 写权限:
chmod a+w /etc/sudoers
(2)vim /etc/sudoers,增加一行:
es ALL=(ALL:ALL) ALL
(3)保存后,去除 /etc/sudoers 的写权限
chmod a-w /etc/sudoers
(九)安装elasticsearch
(1)下载安装包,到 Elasticsearch官网下载:elasticsearch下载地址
(2)解压 elasticsearch-6.7.2.tar.gz
tar -zxvf elasticsearch-6.7.2.tar.gz -C /usr/local/ ;
mv /usr/local/elasticsearch-6.7.2.tar.gz /usr/local/elasticsearch
(3)更改 /usr/local/elasticsearch 用户及用户组为 es
chown -R es:es /usr/local/elasticsearch
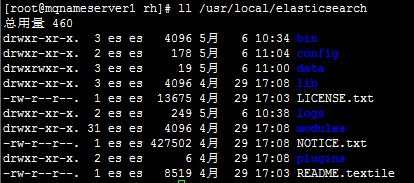
(4)验证是否更改成功
ll /usr/local/elasticsearch
(十、设置elasticsearch)
编辑 Elasticsearch 包下 conf 目录下,elasticsearch.yml 文件,添加如下内容:
cluster.name: my-application
node.name: node1
network.host: 10.10.10.10
http.port: 9200
discovery.zen.ping.unicast.hosts: ["node1"]
discovery.zen.minimum_master_nodes: 1
http.cors.enabled: true
http.cors.allow-origin: "*"
所有机器配置几乎一样,除了node.name 、 network.host 配置成各自机器的
(十一、启动elasticsearch)
启动节点1 的 Elasticsearch,直接运行 ./usr/local/elasticsearch/bin/elasticsearch,启动成功后。
访问 (http://10.10.10.10:9200/_cluster/health/?pretty) 查看集群状态如下:
至此集群搭建完成
Kibana安装
(一、下载Kibana)
下载地址
(二、解压)
tar -zxvf kibana-6.7.2-linux-x86_64.tar.gz
(三、修改kibana配置文件)
修改 /conf/kibana.yml 文件
将默认的server.host: “localhost” 改成server.host: “0.0.0.0”,以供外网访问。
如果 Kibana 和 Elasticsearch 不在同一个服务器上则需要配置参数:elasticsearch.url 为 Elasticsearch 真实的地址和端口(默认 9200)。
(四、运行)
./bin/kibana
(五、访问kibana)
浏览器输入IP:5601,回车后,如下界面
这里放一下常用的查询语句
#查看索引
GET /jianxin1/_settings
#查看所有索引
GET _all/_settings
#删除索引
DELETE jianxin
#查询数据-
GET /jianxin/_search
#查询mapping
GET /jianxinrule/_mapping
springboot整合
pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.15.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.xxxx</groupId>
<artifactId>xxxxx</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>xxxxx</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<tomcat.version>9.0.37</tomcat.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-juli</artifactId>
<version>${tomcat.version}</version>
</dependency>
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>3.9</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
</resources>
</build>
</project>
这里springboot用的是2.1.5,elasticsearch用的是6.7.2
建立索引
PUT /jianxin
{
"mappings" : {
"conversation" : {
"properties" : {
"conversations" : {
"type" : "nested",
"properties" : {
"endTime" : {
"type" : "date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
},
"role" : {
"type" : "text"
},
"sentence" : {
"type" : "text"
},
"startTime" : {
"type" : "date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
}
}
},
"id" : {
"type" : "keyword"
},
"seatId" : {
"type" : "text"
},
"seatName" : {
"type" : "text"
}
}
}
}
}
索引对应的实体类
import lombok.Data;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.util.List;
@Data
@Document(indexName = "jianxin",type = "conversation")
public class JianXin {
@Field(type = FieldType.Keyword)
private String id;
@Field(type = FieldType.Text)
private String seatId;
@Field(type = FieldType.Text)
private String seatName;
@Field(type = FieldType.Nested)
private List<Conversation> conversations;
}
import com.fasterxml.jackson.annotation.JsonFormat;
import lombok.Data;
import org.springframework.data.elasticsearch.annotations.DateFormat;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import org.springframework.format.annotation.DateTimeFormat;
import java.text.Format;
import java.util.Date;
@Data
public class Conversation {
@Field(type = FieldType.Text)
private String sentence;
//下边这个时间格式设置,困扰了我好久,总的来说要想在Java插入数据到es,并且格式为yyyy-MM-dd HH:mm:ss||yyyy-MM-dd,就得这么做
@Field(type = FieldType.Date,format = DateFormat.custom,pattern = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd")
@DateTimeFormat
private String startTime;
@Field(type = FieldType.Date,format = DateFormat.custom,pattern = "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd")
@DateTimeFormat
private String endTime;
@Field(type = FieldType.Text)
private String role;
}
Dao层配置
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import java.util.List;
public interface JianXinRepository extends ElasticsearchRepository<JianXin,String> {
List<JianXin> findByIdAndSeatId(String id,String seatId);
}
批量插入数据到es
@Autowired
private JianXinRepository jianXinRepository;
@Autowired
private JianXinDao jianXinDao;
long start = System.currentTimeMillis();
List<JianXin> jianXinList = jianXinDao.queryJianXin();
if (jianXinList.size()>0){
jianXinRepository.saveAll(jianXinList);
}else {
log.info("此次同步没有获得数据");
}
long finish = System.currentTimeMillis();
long timeElapsed = finish - start;
log.info("总耗时:"+timeElapsed);
聚合查询
这里搞一个聚合查询的例子
比如我的索引是这样的
PUT /jianxinrule
{
"mappings": {
"info":{
"properties": {
"id" : {
"type" : "keyword"
},
"serialNumber": {
"type": "keyword"
},
"seatId":{
"type":"keyword"
},
"provinceCode": {
"type": "keyword"
},
"tid": {
"type": "keyword"
},
"rtnCode": {
"type": "keyword"
},
"rtnMsg": {
"type": "keyword"
},
"flag": {
"type": "keyword"
},
"ruleInfos": {
"type": "nested",
"properties": {
"ruleId": {
"type": "long"
},
"ruleName": {
"type": "keyword"
},
"voiceSegments": {
"type": "nested",
"properties": {
"endTime": {
"type" : "date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
},
"startTime": {
"type" : "date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd"
}
}
}
}
}
}
}}
}
然后我需要在seatId下聚合ruleName的数量,在一startTime>=2020-07-06 12:02:00,并且ruleName的值
GET jianxinrule/info/_search
{
"size": 0,
"query": {
"bool": {
"must": [{
"nested": {
"path": "ruleInfos",
"query": {
"bool": {
"must": [{
"nested": {
"path": "ruleInfos.voiceSegments",
"query": {
"bool": {
"must": [
{"range": {
"ruleInfos.voiceSegments.startTime": {
"gte": "2020-07-06 12:02:00"
}
}}
]
}
}
}
}
]
}
}
}
}]
}
},
"aggs": {
"seatId": {
"terms": {
"field": "seatId"
},
"aggs": {
"ruleInfo": {
"nested": {
"path": "ruleInfos"
},
"aggs": {
"ruleName": {
"terms": {
"field": "ruleInfos.ruleName",
"size": 10,
"include": ".*"
}
}
}
}
}
}
}
}
这样查询的结果展示一下
{
"took" : 65,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 13,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"seatId" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "3028",
"doc_count" : 9,
"wordgroup" : {
"doc_count" : 450,
"word" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "4、5环节后答复不正确",
"doc_count" : 189
},
{
"key" : "3环节后答复不准确",
"doc_count" : 81
},
{
"key" : "服务禁语",
"doc_count" : 63
},
{
"key" : "确认客户登录的系统与页面",
"doc_count" : 54
},
{
"key" : "客户情绪搜集",
"doc_count" : 45
},
{
"key" : "材料告知不准确",
"doc_count" : 9
},
{
"key" : "材料告知不齐全",
"doc_count" : 9
}
]
}
}
},
{
"key" : "3025",
"doc_count" : 4,
"wordgroup" : {
"doc_count" : 200,
"word" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "4、5环节后答复不正确",
"doc_count" : 84
},
{
"key" : "3环节后答复不准确",
"doc_count" : 36
},
{
"key" : "服务禁语",
"doc_count" : 28
},
{
"key" : "确认客户登录的系统与页面",
"doc_count" : 24
},
{
"key" : "客户情绪搜集",
"doc_count" : 20
},
{
"key" : "材料告知不准确",
"doc_count" : 4
},
{
"key" : "材料告知不齐全",
"doc_count" : 4
}
]
}
}
}
]
}
}
}
对应的Java代码聚合,并且取得结果
public JSONObject getRuleTable(Integer pageNum,Integer pageSize,String ruleName,String seatId,String callStartTime,String callEndTime) {
SimpleDateFormat fm= new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String aggName = "ruleInfo";
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//这做了一个限定时间的条件,lte为<=,gte为>=
QueryBuilder queryBuilder2 =QueryBuilders.nestedQuery("ruleInfos",QueryBuilders.boolQuery()
.must(QueryBuilders.nestedQuery("ruleInfos.voiceSegments",QueryBuilders.boolQuery().
must(QueryBuilders.rangeQuery("ruleInfos.voiceSegments.startTime").
lte(callEndTime).
gte(callStartTime).
format("yyyy-MM-dd HH:mm:ss"))
,ScoreMode.None)),ScoreMode.None);
//规定的query放入builder
queryBuilder.withQuery(queryBuilder2);
queryBuilder.withPageable(new PageRequest(1,10));
AggregationBuilder aggregationBuilder;
List<FieldSortBuilder> fieldSorts=new ArrayList<>();
//这个是聚合为了统计ruleName,IncludeExclude为了让ruleName=“xxxxxx”,size设置为2147483647就是不限制查出来的数量
if (ruleName!=null&&!ruleName.equals("全部")){
aggregationBuilder = AggregationBuilders.terms("seatId").field("seatId").subAggregation(AggregationBuilders.nested("ruleInfo","ruleInfos").
subAggregation(AggregationBuilders.terms("ruleName").field("ruleInfos.ruleName").size(2147483647).includeExclude(new IncludeExclude(ruleName,""))
));
}else { //demo
aggregationBuilder = AggregationBuilders.terms("seatId").field("seatId").subAggregation(AggregationBuilders.nested("ruleInfo","ruleInfos").
subAggregation(AggregationBuilders.terms("ruleName").field("ruleInfos.ruleName").size(2147483647))
);
queryBuilder.addAggregation((AbstractAggregationBuilder) aggregationBuilder);
AggregatedPage<JianXinRule> result = elasticsearchTemplate.queryForPage(queryBuilder.build(), JianXinRule.class);
//解析聚合
Aggregations aggregations = result.getAggregations();
StringTerms terms=aggregations.get("seatId");
log.info("terms"+terms);
//获取桶
List<StringTerms.Bucket> bucketsSeatId = terms.getBuckets();
JSONArray jsonArray = new JSONArray();
JSONObject jsonObject1 = new JSONObject();
int count=0;
List<RuleStatisticBean> list1 = new ArrayList<>();
for (StringTerms.Bucket bucketSeatId : bucketsSeatId) {
Aggregations aggregations1=bucketSeatId.getAggregations();
InternalNested internalNested = aggregations1.get(aggName);
Aggregations aggregations2=internalNested.getAggregations();
StringTerms terms1=aggregations2.get("ruleName");
List<StringTerms.Bucket> bucketsRuleName = terms1.getBuckets();
for (StringTerms.Bucket bucketRuleName :bucketsRuleName){
JSONObject jsonObject = new JSONObject();
jsonObject.put("seatId",bucketSeatId.getKeyAsString());
jsonObject.put("hitCount",bucketRuleName.getDocCount());
jsonObject.put("ruleName",bucketRuleName.getKeyAsString());
jsonObject.put("groupId","全部");
jsonArray.add(jsonObject);
count++;
}
}
jsonObject1.put("data",jsonArray);
jsonObject1.put("count",count);
jsonObject1.put("pageNum",pageNum);
jsonObject1.put("pageSize",pageSize);
return jsonObject1;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









