







 本文详细解析了float和double浮点数的内部结构,包括符号、指数、尾数等组成部分,阐述了它们如何影响浮点数的取值范围和精度。并通过对比int和float的数据表示,解释了精度丢失的原因。
本文详细解析了float和double浮点数的内部结构,包括符号、指数、尾数等组成部分,阐述了它们如何影响浮点数的取值范围和精度。并通过对比int和float的数据表示,解释了精度丢失的原因。
一. float和double的范围
在此先补充一个知识点,浮点数的二进制转换。
| 长度 | 符号 | 指数 | 尾数 | 有效位数 | 指数偏移 | 说明 | |
|---|---|---|---|---|---|---|---|
| 单精度 | 32位 | 1 | 8 | 23 | 24 | 127 | 含有一个隐含位 |
| 双精度 | 64位 | 1 | 11 | 52 | 53 | 1023 | 含有一个隐含位 |
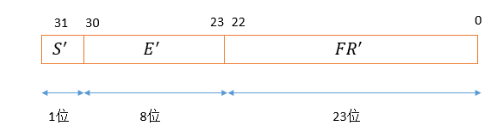
S’为符号位,0表示负数,1为正数;E’为阶码,即指数部分,八位可表示256个数值,指数偏移为127(见表格),即指数范围为-127~+128,计算时实际指数=E’-127;FR’为尾数部分,表示的是科学计数法中小数部分,整数部分默认为1,即计算时实际尾数为1.尾数,例尾数为10101010101010101010101,则计算时1.10101010101010101010101;
浮点数二进制转换为十进制为:
x = (-1)^s X(1.FR’)X 2^(E-127)
float为单精度浮点型,double为双精度浮点型,取值范围主要看指数部分,并且指数位是按补码的形式来划分的。其中负指数决定了浮点数所能表达的绝对值最小的非零数;而正指数决定了浮点数所能表达的绝对值最大的数,也即决定了浮点数的取值范围。float的范围为-2^128 ~ +2^128,也即-3.40E+38 ~ +3.40E+38;double的范围为-2^1024 ~ +2^1024,也即-1.79E+308 ~ +1.79E+308。
二 精度丢失
为什么int,float同用32位表示,但是float范围就比int大很多呢? float的精度缺失是什么原因呢?
因为int数值是连续的,而float数值是跳跃的,并且间隔不一定相等。同用32位表示意思为两个数据类型可存储数值的最大数量是相等的,为2的32次方。
举例:

由图可知,两种类型表示相同数量的数时,float表示的范围大,但同时有一些数float不能表示,如上图的2或4等,所以精度缺失,建议慎用float。

















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









