







 这篇博客介绍了在Windows环境下配置PySpark的步骤,包括环境变量设置、PySpark和py4j包的导入,以及如何编写WordCount程序。文章强调了在打包和提交集群运行时的注意事项,如正确打包zip文件、避免命名冲突等,最后展示了提交脚本和成功运行的结果。
这篇博客介绍了在Windows环境下配置PySpark的步骤,包括环境变量设置、PySpark和py4j包的导入,以及如何编写WordCount程序。文章强调了在打包和提交集群运行时的注意事项,如正确打包zip文件、避免命名冲突等,最后展示了提交脚本和成功运行的结果。
一、环境准备
windows
python3.+
pycharm或者anaconda
spark安装版(解压好之后)
二、设置环境变量
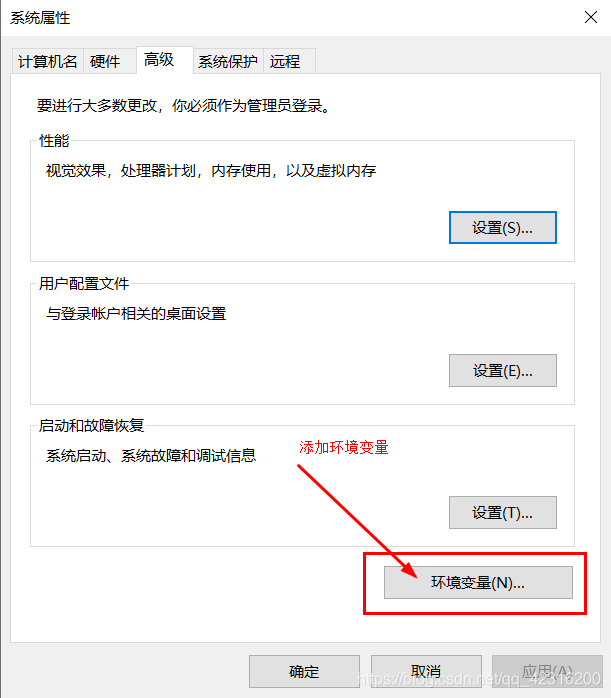
添加系统变量(设置自己的路径)
1.spark
SPARK_HOME=D:/bigdatashare/spark-2.4.3-bin-hadoop2.7
Path=D:/bigdatashare/spark-2.4.3-bin-hadoop2.7/bin2.Python
PYTHON_HOME=D:/Python3.7.0
Path=D:/Python3.7.0/bin三、导入pyspark包+py4j包
1.可以复制解压好的spark安装包内的pyspark和py4j文件夹解压之后---->anaconda的安装目录下的site-packages文件夹下:
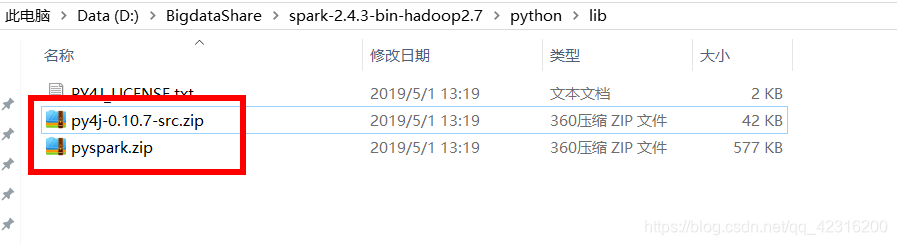
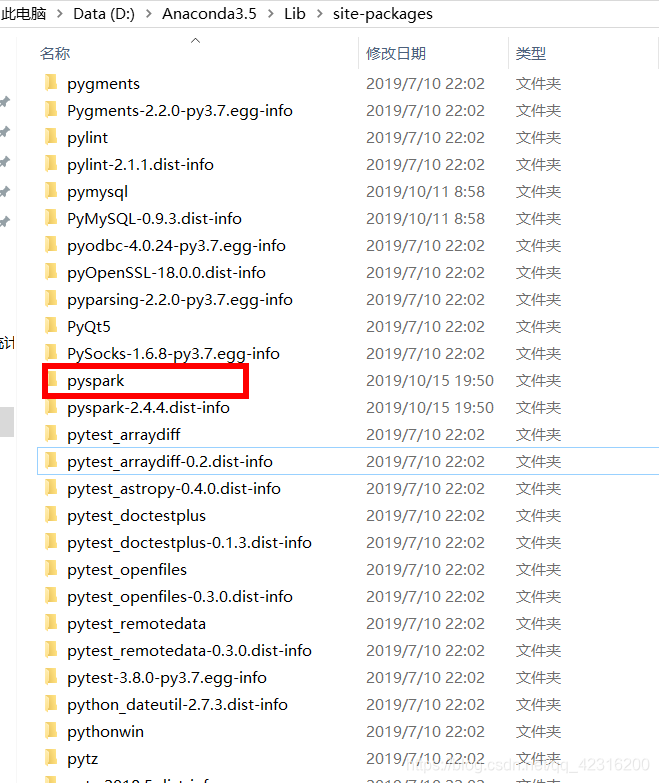
2.可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









