



一. 什么是PySpark
使用过的bin/pyspark 程序, 要注意, 这个只是一个应用程序, 提供一个Python解释器执行环境来运行Spark任务
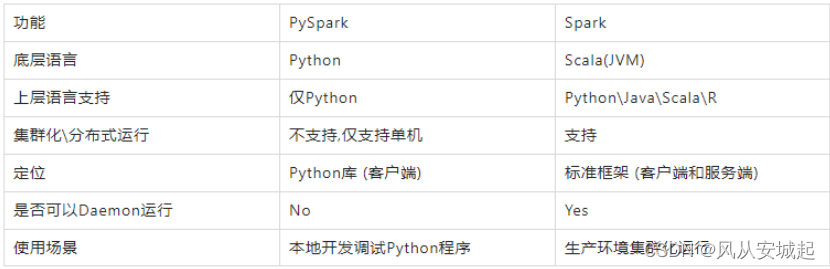
现在说的PySpark, 指的是Python的运行类库, 是可以在Python代码中:import pyspark PySpark 是Spark官方提供的一个Python类库, 内置了完全的Spark API, 可以通过PySpark类库来编写Spark应用程序,并将其提交到Spark集群中运行. 下图是,PySpark类库和标准Spark框架的简单对比
Anaconda是Python语言的一个发行版. 内置了非常多的数据科学相关的Python类库, 同时可以提供虚拟环境来供不同的程序使用.
我们写spark的时候在windows上开发不可避免的会用到部分hadoop功能
为了避免在windows上报错, 我们给windows打补丁.

二.PyCharm配置Python解释器
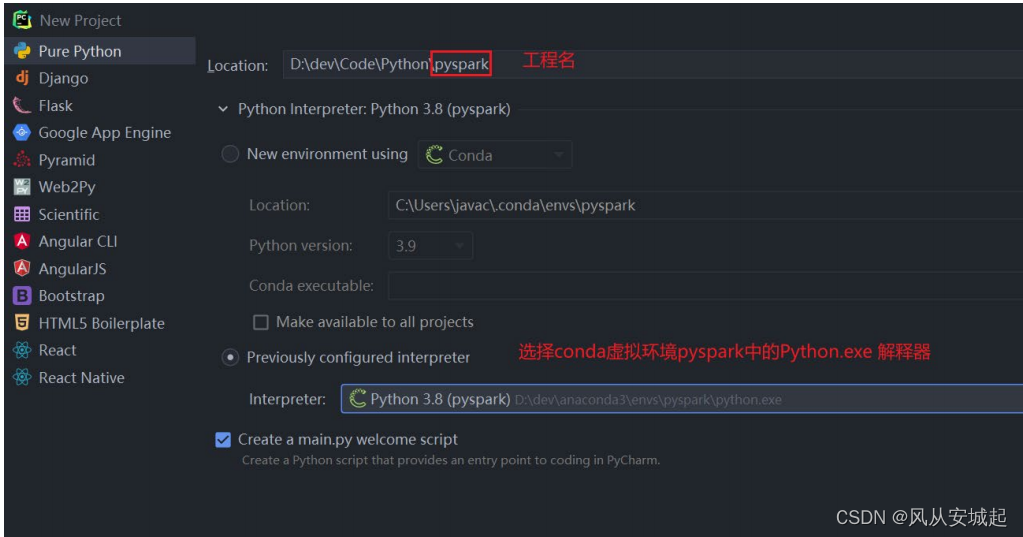
1.配置本地解释器
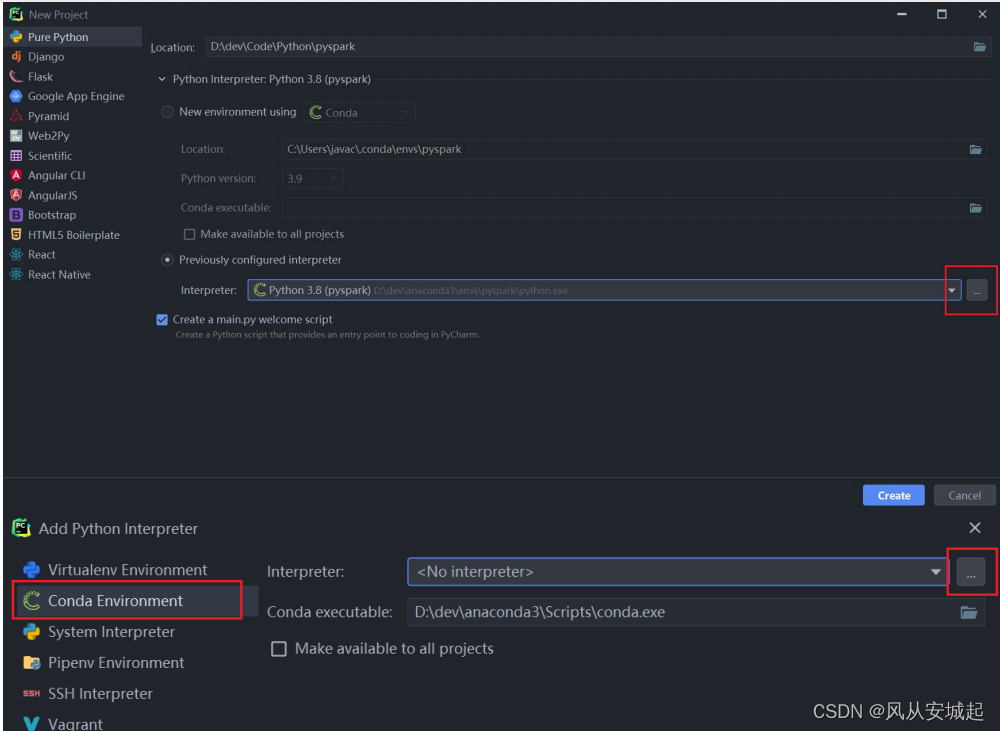
如果没有找到conda虚拟环境的解释器,可以:

2.配置远程SSH Linux解释器
刚刚,配置了本地的Python(基于conda虚拟环境)的解释器, 现在我们来配置Linux远程的解释器.
PySpark支持在Windows上执行,但是会有性能问题以及一些小bug, 在Linux上执行是完美和高效的.
所以, 我们也可以配置好Linux上的远程解释器, 来运行Python Spark代码
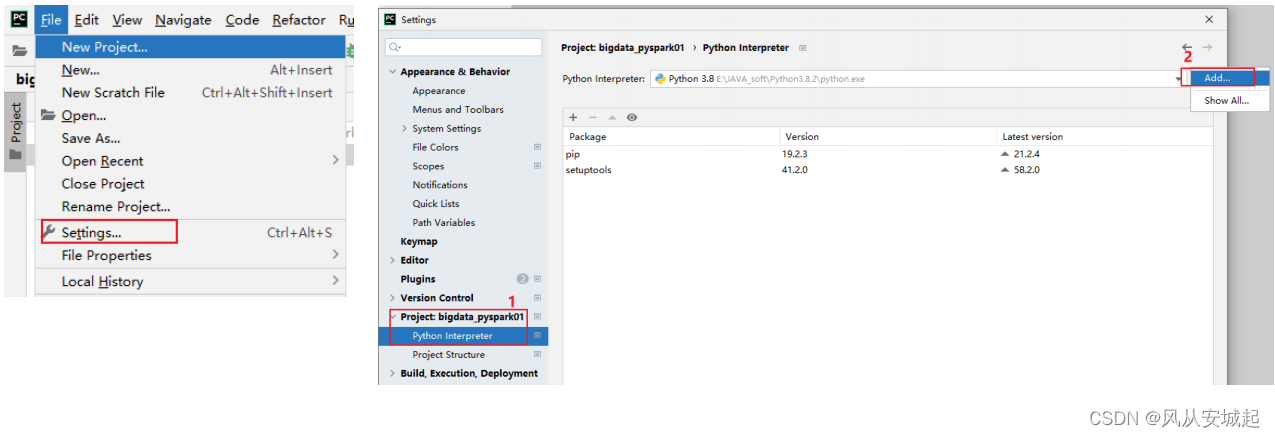
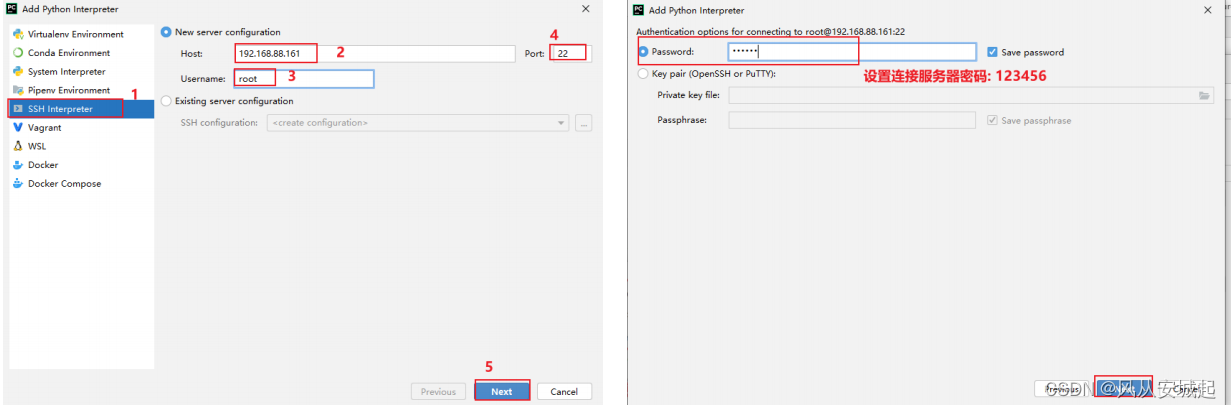
1) 设置远程SSH python pySpark 环境
2) 添加新的远程连接
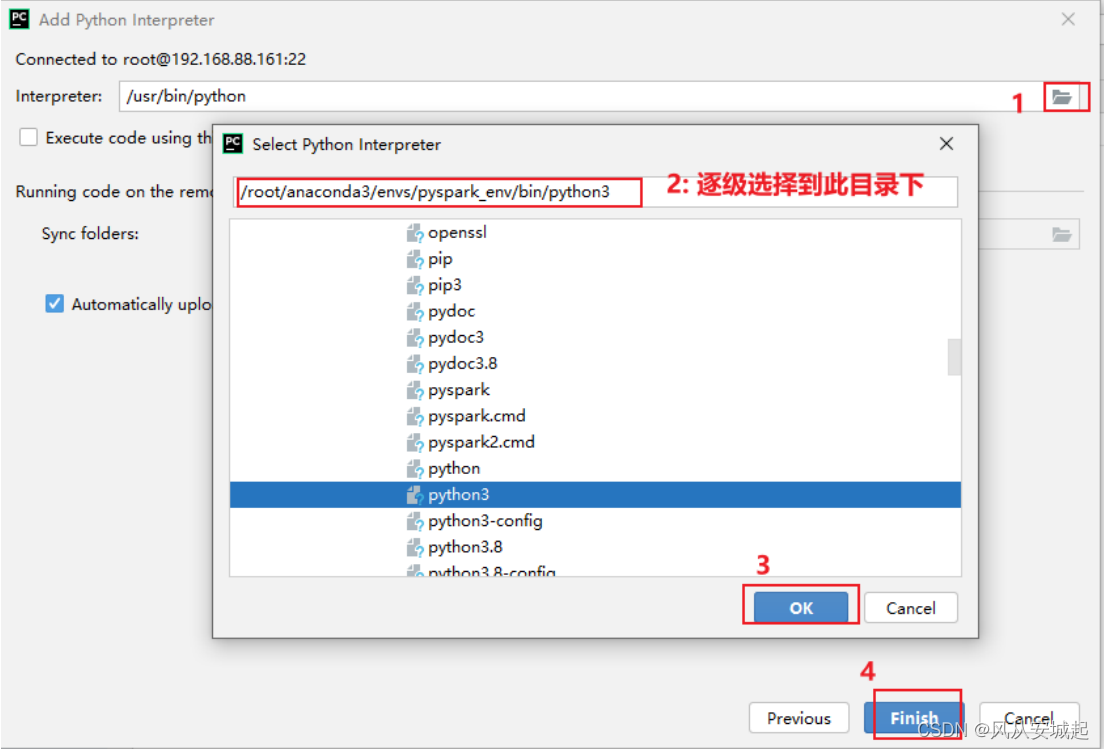
3) 设置虚拟机Python环境路径

三.应用入口:SparkContext
Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象,如下两步构建:
第一步、创建SparkConf对象
设置Spark Application基本信息,比如应用的名称AppName和应用运行Master
第二步、基于SparkConf对象,创建SparkContext对象

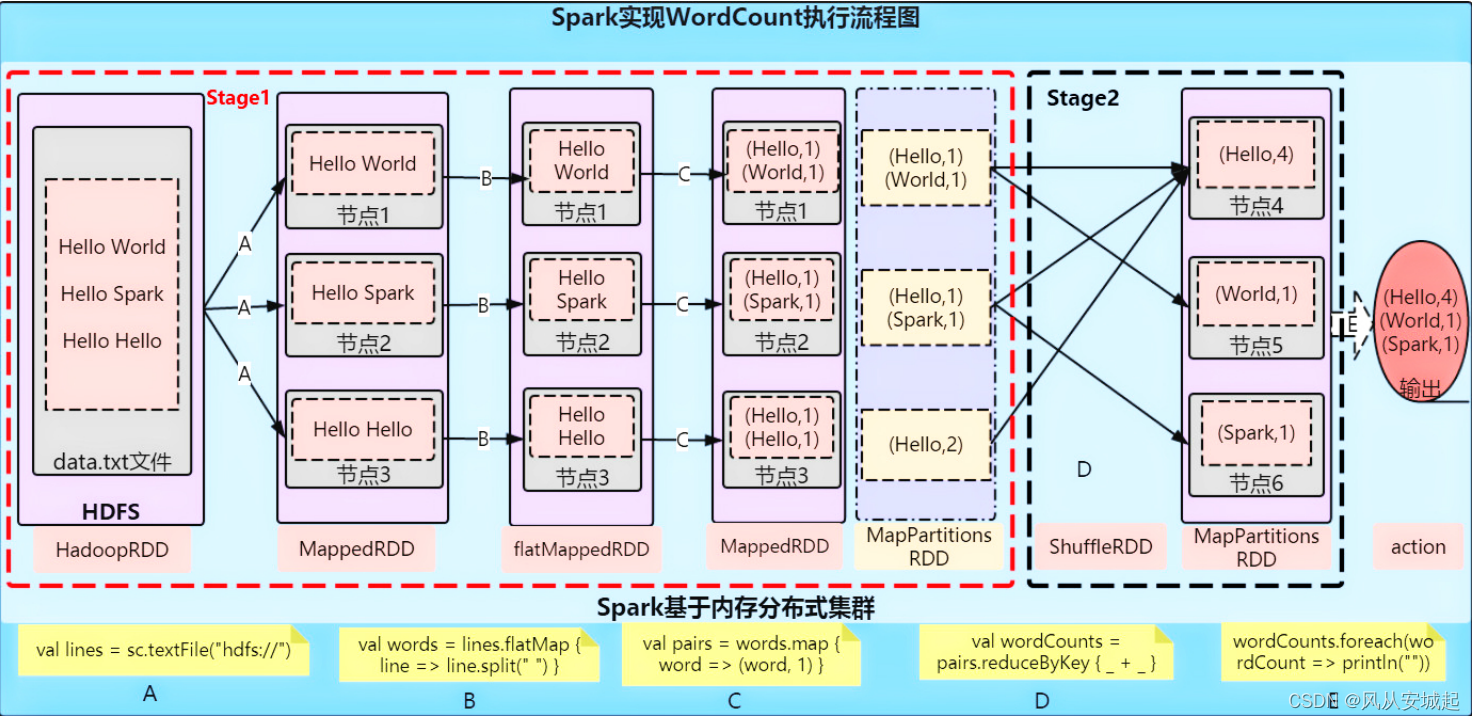
四.单词计数代码实践
from pyspark import SparkContext, SparkConf
import os
# 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置
os.environ['SPARK_HOME'] = '/export/servers/spark'
# PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
# os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
# os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
print('PySpark First Program')
# TODO: 当应用运行在集群上的时候,MAIN函数就是Driver Program,必须创建SparkContext对象
# 创建SparkConf对象,设置应用的配置信息,比如应用名称和应用运行模式
conf = SparkConf().setAppName("miniProject").setMaster("local[*]")
# TODO: 构建SparkContext上下文实例对象,读取数据和调度Job执行
sc = SparkContext(conf=conf)
# 第一步、读取本地数据 封装到RDD集合,认为列表List
wordsRDD = sc.textFile("file:///export/pyfolder1/pyspark-chapter01_3.8/data/word.txt")
# 第二步、处理数据 调用RDD中函数,认为调用列表中的函数
# a. 每行数据分割为单词
flatMapRDD = wordsRDD.flatMap(lambda line: line.split(" "))
# b. 转换为二元组,表示每个单词出现一次
mapRDD = flatMapRDD.map(lambda x: (x, 1))
# c. 按照Key分组聚合
resultRDD = mapRDD.reduceByKey(lambda a, b: a + b)
# 第三步、输出数据
res_rdd_col2 = resultRDD.collect()
# 输出到控制台
for line in res_rdd_col2:
print(line)
# 输出到本地文件中
resultRDD.saveAsTextFile("file:///export/pyfolder1/pyspark-chapter01_3.8/data/output1/")
print('停止 PySpark SparkSession 对象')
# 关闭SparkContext
sc.stop()
切换到远程SSH 解释器执行(在Linux系统上执行)
要注意, 远程解释器,本质上是在服务器上执行, 那么读取的文件,也应该是服务器上的文件路径.
如果是提交自己的代码到服务器上,那么需要对代码进行一些改动:
# 第一步、读取本地数据 封装到RDD集合,认为列表List
wordsRDD = sc.textFile("hdfs://node1:8020/pydata/")
# 输出到本地文件中
resultRDD.saveAsTextFile("hdfs://node1:8020/pydata/output1/")
print('停止 PySpark SparkSession 对象')
hdfs dfs -cat /output/output1/*
现在将代码提交到YARN集群进行测试.
提交集群对代码:
setMaster部分进行删除
因为提交到集群可以通过客户端工具的参数指定master, 比如spark-submit工具.
所以,我们不在代码中固定master的设置, 不然客户端工具参数无效, 代码的优先级是最高的.
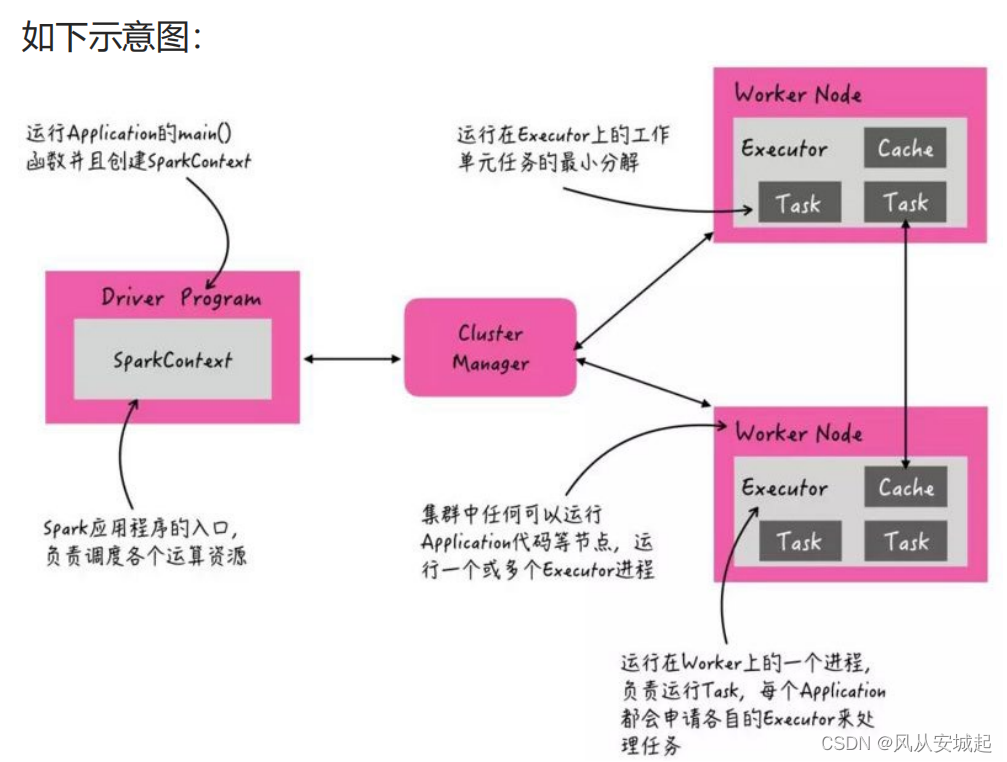

分布式代码的分析
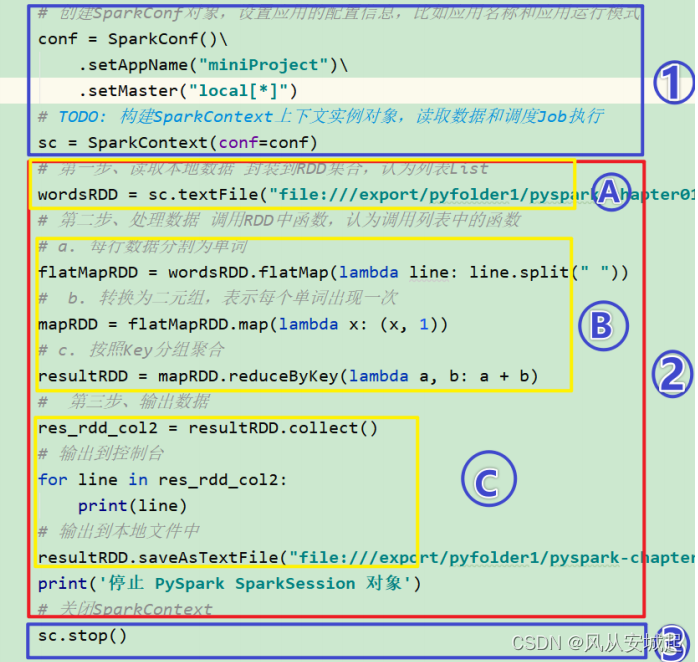
2是由executor运行的,1和3是由driver运行的,因此地址一定要可以共享访问的HDFS地址
当1结束后,序列化SparkContext对象会发送给各个Executor,每个Executor对象就拿到了sc对象。就可以读取文件来计算数据。代码是一份代码,但是执行是好多个Executor
上图中②的加载数据【A】、处理数据【B】和输出数据【C】代码,都在Executors上执行,从WEB UI监控
页面可以看到此Job(RDD#action触发一个Job)对应DAG图

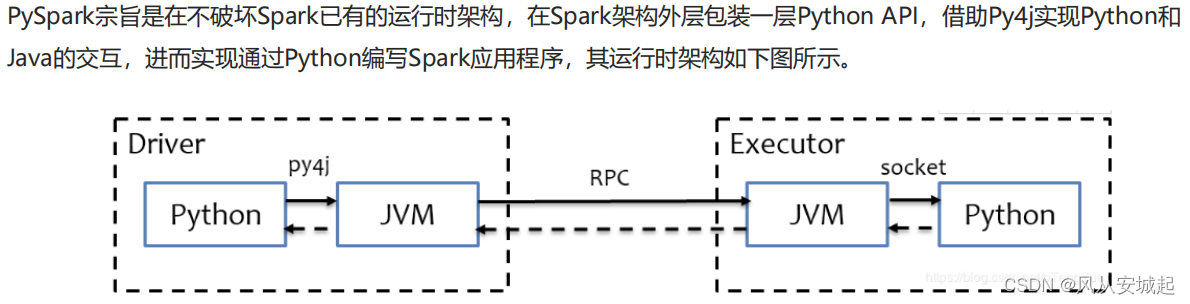
Driver端是由JVM执行,Executor端由JVM命令转发,底层由Python解释器进行工作

















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









