







哈夫曼树和哈夫曼编码
关于编码
- 常用编码方式
等长码:每个字符对应码字的码长都一样,例如ASCII码表中的128个字符可以用7位码长的01位串表示( 2 7 = 128 2^7=128 27=128 )。 - 思考
能不能用不等长的编码方式来编码字符,出现次数较多的字符用较短的码长的码字来存储,出现次数较少的字符用较长的码长的码字来存储,使得存储所有字符用更少的空间? - 问题
-
如何进行不等长编码?
想要采用不等长编码的方式,那么应该怎么构造一个字符与不同码长的码字之间的一一对应的关系?最长的码字的码长应该是多少?最短的码字的码长有应该是多少? -
如何避免不等长编码方式的二义性?
例:假定以下字符采用下面的不等长编码方式
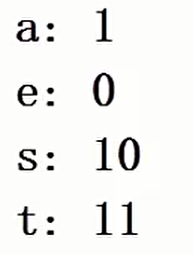
那么1011表示的是哪个字符串的编码?可以看出,1011可以表示aeaa、aet和st。这就产生了编码的二义性。所以编码时一定要是前缀码,这样才能避免编码的二义性。
- 前缀码(Prefix Code): 任何字符的编码都不是另一个字符的前缀。
-
- 解决
利用哈夫曼树来构造前缀码。
哈夫曼树
-
带权路径长度(WPL)
设二叉树有n个叶子节点,每个叶子节点带有权值 W k W_k Wk,从根节点到每个叶子节点的长度为 L k L_k Lk,则每个叶子节点的带权路径长度之和就是
W P L = ∑ k = 1 n W k L k WPL=\sum_{k=1}^{n}{{W_k}{L_k}} WPL=k=1∑nWkLk -
哈夫曼树(最优二叉树)
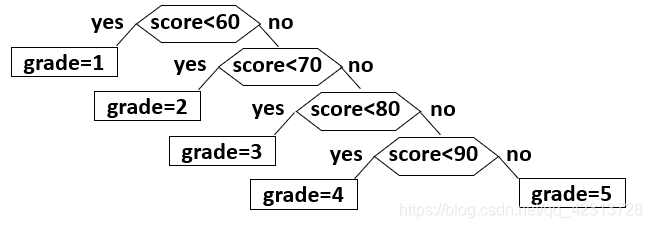
WPL最小的二叉树。例:写一个程序将百分制的考试成绩转换成五分制的成绩。60分以下是等级1,60到70分是等级2,70到80分是等级3,80到90分是等级4,90到100是等级5。
学生成绩分布概率如下:分数段 0-59 60-69 70-79 80-89 90-100 比例 0.05 0.15 0.40 0.30 0.10 对比以下两种程序结构:
结构1:
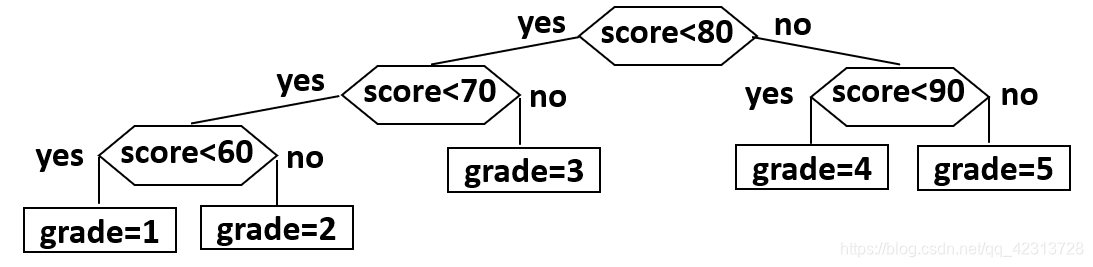
结构二:
结构1的平均查找速率(这棵判定树的WPL):
0.05 × 1 + 0.15 × 2 + 0.4 × 3 + 0.3 × 4 + 0.1 × 4 = 3.15 0.05 \times 1+0.15 \times 2+0.4 \times 3+0.3 \times 4+0.1 \times 4=3.15 0.05×1+0.15×2+0.4×3+0.3×4+0.1×4=3.15结构2的平均查找速率(这棵判定树的WPL):
0.05 × 3 + 0.15 × 3 + 0.4 × 2 + 0.3 × 2 + 0.1 × 2 = 2.2 0.05 \times 3+0.15 \times 3+0.4 \times 2+0.3 \times 2+0.1 \times 2=2.2 0.05×3+0.15×3+0.4×2+0.3×2+0.1×2=2.2可以看出,将结构1、2看成一棵判定树,每个等级就成了树的叶子节点,叶子节点的权值就是其成绩分布概率,而需要判断的个数就是该节点到树根的距离。这样,平均查找速率就是这棵树的WPL。不同的结构,树的WPL不同,而WPL最小的那棵树就是哈夫曼树。
哈夫曼编码
-
利用二叉树构造前缀码
- 左右分支分别代表0和1;
- 字符只在叶节点上。
例:对字符a、u、x和z四个字符进行编码。
- 等长码:
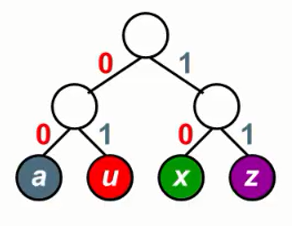
a:00
u:01
x:10
z:11 - 不等长码:
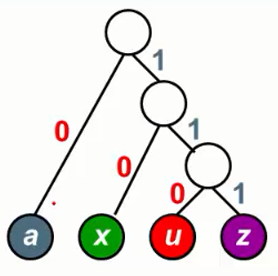
a:0
u:110
x:10
z:111
可以看到利用二叉树可以构造出前缀码,使得编码没有二义性。
-
利用哈夫曼树编码使得存储空间最小
例:一段字符由a、u、x和z组成,其中a出现4次,u出现1次,x出现2次,z出现一次。怎样的编码方式才能使这段字符存储空间最小?首先,我们可以计算利用等长码编码所用到的存储空间:
C o s t = 2 × 4 + 2 × 1 + 2 × 2 + 2 × 1 = 16 Cost=2 \times 4+2 \times 1+2 \times 2+2 \times 1=16 Cost=2×4+2×1+2×2+2×1=16我们可以看到,存储空间的计算就相当于将字符出现的频率当作叶子结点的权值,每个字符码字的码长当作根节点到叶子节点的长度,所用存储空间就是这棵树的WPL。所以构造一棵哈夫曼树用来编码,所用的存储空间最小,如上不等长编码就是一棵哈夫曼树,其所用到的存储空间为:
C o s t = 1 × 4 + 3 × 1 + 2 × 2 + 3 × 1 = 14 Cost=1 \times 4+3 \times 1+2 \times 2+3 \times 1=14 Cost=1×4+3×1+2×2+3×1=14
构造哈夫曼树
-
步骤:
- 将所有叶子节点的权值从小到大排列;
- 取出权值最小的两个节点,构成一棵二叉树,他们是两个子节点,他们的父节点的权值等于他们权值的和。在将他们的父节点权值与剩下的叶子节点的权值排序;
- 重复这个过程,直到序列中只有一个节点的权值
-
过程示例:
- 将所有叶子节点的权值从小到大排列:

- 取出最小两个节点构成一棵二叉树,他们的权值和加入序列并重新排序;
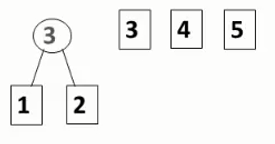
- 重复第二步:
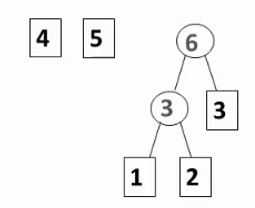
- 重复第二步:
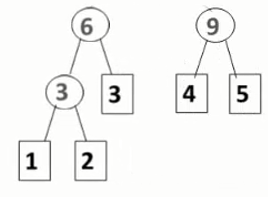
- 直到序列中只有一个权值:
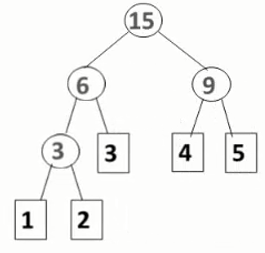
- 依照这个步骤,一棵哈夫曼树就构造好了
- 将所有叶子节点的权值从小到大排列:
-
代码分析
-
哈夫曼树节点表示
typedef struct TreeNode{ int Weight;//节点的权值 struct TreeNode *Left;//指向左子树的指针 struct TreeNode *Right;//指向右子树的指针 }HuffmanTreeNode,*HuffmanTree; -
代码执行过程中,每次都要取权值序列中最小的两个节点出来,所以每次都要进行一次排序;不过还有一种方法就是利用最小堆的特性,进行两次取出操作,取出最小值,然后插入新的权值。相较于前者,后者的时间复杂度比较低。(堆的一些方法与实现)
-
具体代码(C语言)
//构造哈夫曼树 //所有权值都存在HuffmanTreeNode类型的数组中,HT指向该数组,数组元素个数为Size HuffmanTree BuildHuffmanTree(HuffmanTree HT, int Size) { MinHeap H = NULL;//构建最小堆 HuffmanTree HTRoot = NULL; int i = 0,size; //用数组构建一个最小堆 H = BuildHeap(MaxSize, HT, Size); size = H->Size;//用size暂存堆中元素个数,否者在插入和删除过程中,H->Size会改变 for (i = 0; i <size-1; i++) { HTRoot = (HuffmanTree)malloc(sizeof(HuffmanTreeNode));//构建一个新的节点 HTRoot->Left = DeleteHeap(H); HTRoot->Right = DeleteHeap(H);//新节点左右子树指针分别指向权值最小的两个节点 HTRoot->weight = (HTRoot->Left->weight) + (HTRoot->Right->weight);//新节点权值为两个权值最小节点的权值的和 InsertHeap(H, HTRoot);//将新节点插入堆中 } HTRoot = DeleteHeap(H);//将HTRoot指向堆中最后的一个节点,作为哈夫曼树的根 //释放堆的空间 DestroyHeap(H); return HTRoot;//返回哈夫曼树的根节点 }
-

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









