







类比-细节双通道神经网络论文的模型复现(pytorch)
三种ADNet
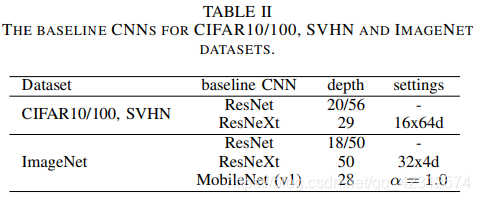
如图为本文针对不同数据库采用的typical CNN结构。
AD-ResNet
下图为各个AD-ResNet的详细网络结构图。每层旁边的数字表示输出feature map的大小。
左边的AD-ResNet-20、AD-ResNet-56是将ResNet-20、ResNet-56变形实现,用于训练CIFAR10/100、SVHN等数据集;右边的AD-ResNet-18、AD-ResNet-50是将ResNet-18、ResNet-56变形实现,用于训练ImageNet。
AD-ResNeXt
下图为两个AD-ResNeXt的详细网络结构图。每层旁边的数字表示输出feature map的大小。
右边的AD-ResNeXt-29是将ResNeXt-29变形实现,用于训练CIFAR10/100、SVHN等数据集;左边的AD-ResNeXt-50是将ResNeXt-50变形实现,用于训练ImageNet。

AD-MobileNet
下图为两个AD-MobileNet的详细网络结构图。每层旁边的数字表示输出feature map的大小。
左边的AD-MobileNet是在AD block中堆叠两个深度可分卷积(DW卷积+PW卷积)实现,;右边的AD-MobileNet是将一个深度可分卷积放到detail路径中。它们都用于训练ImageNet等数据集。
注意:在MobileNet(v1)最后一个深度可分离卷积的stride应该为1,而不是论文中的2,这样才能保证尺寸为7*7不变。

模型代码
AD_ResNet
AD_ResNet_20/56
class AD_Basic_block(nn.Module):
def __init__(self, ch_in, ch_out, stride = 1):
super(AD_Basic_block, self).__init__()
#LF
self.convl1 = nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride)
self.bnl1 = nn.BatchNorm2d(ch_out)
#HF
self.convh1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bnh1 = nn.BatchNorm2d(ch_out)
self.convh2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bnh2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
self.extra = nn.Sequential(
#如果输入的通道数和输出的通道数不一样,就用1x1的卷积来改变通道数
nn.Conv2d(ch_in,ch_out,kernel_size=1,stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
#分频
LF = self.FrequencyDecomposer(x)
HF=x
#resnet
HF1 = F.relu(self.bnh1(self.convh1(HF)))
HF1 = self.bnh2(self.convh2(HF1))
# print("HFshape:" ,HF1.shape)
# Short Cut
# element-add
HF = self.extra(HF) + HF1
#LF
LF = self.bnl1(self.convl1(LF))
# 融合
# print("LFshape:",LF.shape)
# print("HFshape:" ,HF.shape)
out = F.relu(HF.mul(torch.sigmoid(LF)))
return out
#定义频率解析器
def FrequencyDecomposer(self,x):
#########################均值滤波器----获取LF
#设置kernel=3, stride=2;
w = [[1 / 9, 1 / 9, 1 / 9],
[1 / 9, 1 / 9, 1 / 9],
[1 / 9, 1 / 9, 1 / 9]]
min_batch = x.size()[0]
channels = x.size()[1]
out_channel = channels
# 将卷积核扩展到任意通道大小
# w = torch.cuda.FloatTensor(w).expand(out_channel, channels, 3, 3)
w = torch.FloatTensor(w).expand(out_channel, channels, 3, 3)
LF = F.conv2d(x, w, stride=1, padding=1)
###########################通过减法获取HF=X-u*LF
# LF的shape与x一致
# u 是向量,为LF的每个Channel赋予权重。向量长度与LF的channel数一致。
# 论文中在AD-ResNet-20实验中u=0时的准确率最高,故实现中选取u=0,HF=x
###########################
return LF
#AD_ResNet_20/56
class AD_ResNet_ci(nn.Module):
def __init__(self,num_blocks):
super(AD_ResNet_ci, self).__init__()
#第一层 卷积输出为32x32x16
self.conv1 = nn.Conv2d(3,16,kernel_size=3,stride=1,padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.relu1 = nn.ReLU(inplace=True)
#3个blocks
#[b, 16, h, w] --> [b, 32, h, w]
self.layer1 = self._make_layer_(16, 16, num_blocks[0], stride=1)
self.layer2 = self._make_layer_(16, 32, num_blocks[1], stride=2)
self.layer3 = self._make_layer_(32, 64, num_blocks[2], stride=2)
self.outlayer = nn.Linear(1*1*64,10)
def _make_layer_(self,in_ch, out_ch,block_num,stride=1):
layers=[]
layers.append(AD_Basic_block(in_ch,out_ch,stride=stride))
in_ch=out_ch
for _ in range(1,block_num):
layers.append(AD_Basic_block(in_ch,out_ch))
return nn.Sequential(*layers)
def forward(self, x):
#第一层
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = F.adaptive_avg_pool2d(x,[1,1])
# x = x.view(x.size(0),-1)
x = torch.flatten(x,1)
x = self.outlayer(x)
x = F.softmax(x,dim =1)
# print("xshape:" ,x)
return x
# AD_ResNet_20和AD_ResNet_56都是针对CIFAR10/100,SVHN数据集
def AD_ResNet_20():
return AD_ResNet_ci([3,3,3])
def AD_ResNet_56():
return AD_ResNet_ci([9,9,9])
AD_ResNet_18/50
# 这个类对应了AD-ResNet-18残差结构
class BasicBlock(nn.Module):
# 标识残差结构中卷积核的个数是否发生变化
# 系数为1表示层数的卷积核个数相同
expansion = 1
# 初始化函数
# 传入参数:输入特征矩阵的深度、输出特征矩阵的深度(主分支上卷积核的个数)、默认步长为1、下采样参数(对应虚线的残差结构)
def __init__(self, in_channel, out_channel, stride=1, downsample=None):
super(BasicBlock, self).__init__()
# LF
self.convl1 = nn.Conv2d(in_channel, out_channel, kernel_size=1, stride=stride)
self.bnl1 = nn.BatchNorm2d(out_channel)
# HF
# 卷积层1 卷积核大小为3,步长默认为1(当步长为2时则对应虚线的残差结构)
# 输出矩阵的高和宽有一个计算方式 =(输入特征矩阵的高宽-kernel_size+2*padding)/stride+1
# bias = False 表示不使用偏置
self.conv1 = nn.Conv2d(in_channels=in_channel, out_channels=out_channel,
kernel_size=3, stride=stride, padding = 1, bias = False)
# 定义BN层1 输入的参数就是对应输入的特征矩阵的深度——也就是上一层输出的
self.bn1 = nn.BatchNorm2d(out_channel)
# 定义激活函数
self.relu = nn.ReLU()
# 定义第二层卷积层
self.conv2 = nn.Conv2d(in_channels=out_channel, out_channels=out_channel,
kernel_size = 3, stride = 1, padding = 1, bias = False)
# 第二个BN层
self.bn2 = nn.BatchNorm2d(out_channel)
# 定义下采样方法————对应虚线/实线残差结构
self.downsample = downsample
# 正向传播的过程
def forward(self, x):
# 分频
LF = self 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 114
114

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









