







 本文介绍了深度学习中的两种关键优化参数:学习率和动量。学习率控制着梯度下降的速度,合适的大小能有效影响模型的收敛。动量通过指数加权平均引入历史梯度信息,加速收敛过程。讨论了如何调整这两个参数以优化模型训练,并提到了torch.optim.SGD中的Nesterov动量。此外,还列举了Pytorch的多种优化器,如SGD和Adam,它们在不同的场景下有着不同的效果。
本文介绍了深度学习中的两种关键优化参数:学习率和动量。学习率控制着梯度下降的速度,合适的大小能有效影响模型的收敛。动量通过指数加权平均引入历史梯度信息,加速收敛过程。讨论了如何调整这两个参数以优化模型训练,并提到了torch.optim.SGD中的Nesterov动量。此外,还列举了Pytorch的多种优化器,如SGD和Adam,它们在不同的场景下有着不同的效果。
【目录】
learning rate学习率
momentum 动量 贝塔β
torch.optim.SGD
Pytorch的十种优化器
1、Learning Rate 学习率
-
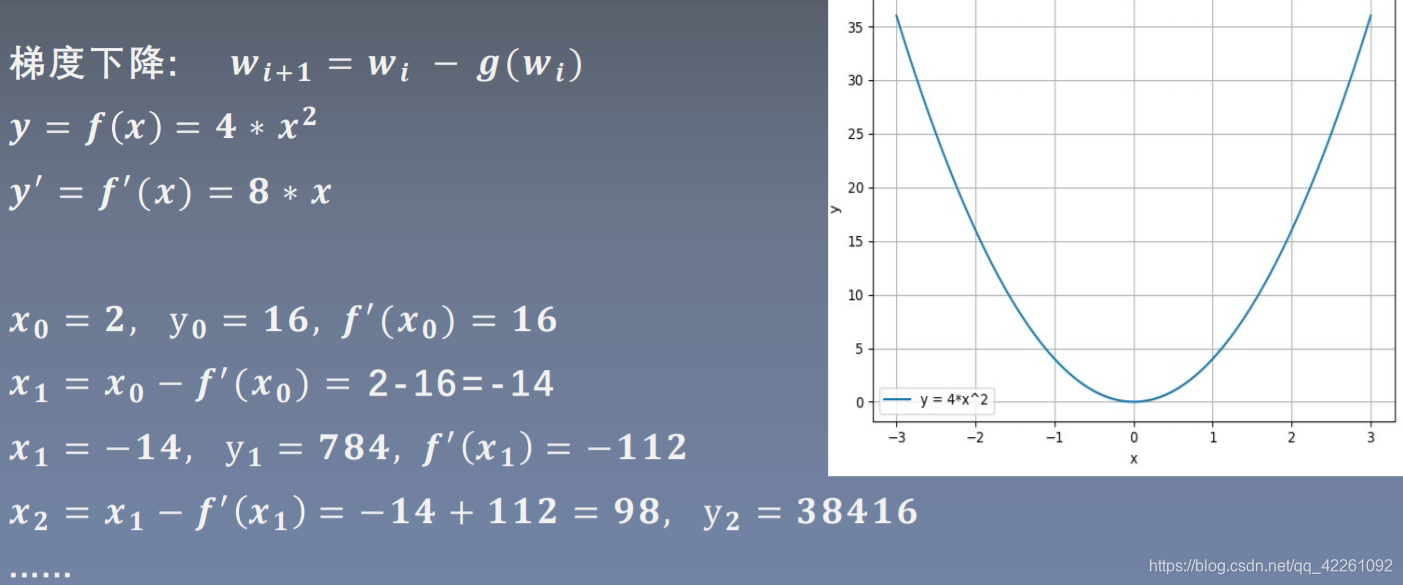
单纯的梯度下降
为了使得梯度下降需要加上负的梯度方向,也就是减去梯度g(wi)
初始位置x0,y0,求取在x0处y的导数,将x0的值带入得到梯度x1;
将x1带入函数y,得到y1,继续求取函数y在x1处的导数,将x1的值带入得到梯度x2;
将x2带入函数y,得到y2。若将y视为损失函数,可以看出:
y0->y1->y2发现y的值并没有减小,反而增大,是因为尺度太大,需要乘以一个系数来缩小尺度
-
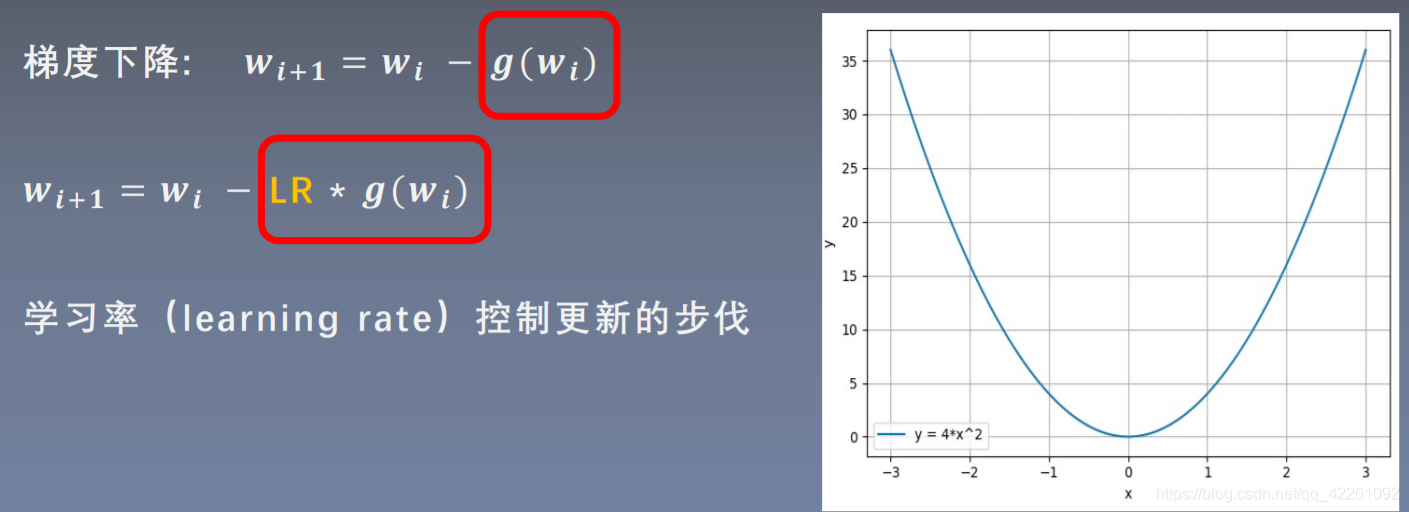
添加了学习率的梯度下降
学习率lr来减小更新的步伐
学习率过小会导致收敛速度减慢,学习率过大(如0.5,0.3)会导致模型不收敛,收敛速度最快的是与”上帝学习率“最近的那个学习率
2、momentum 动量 贝塔β
冲量能加速梯度下降,相当于添加了惯性属性

-
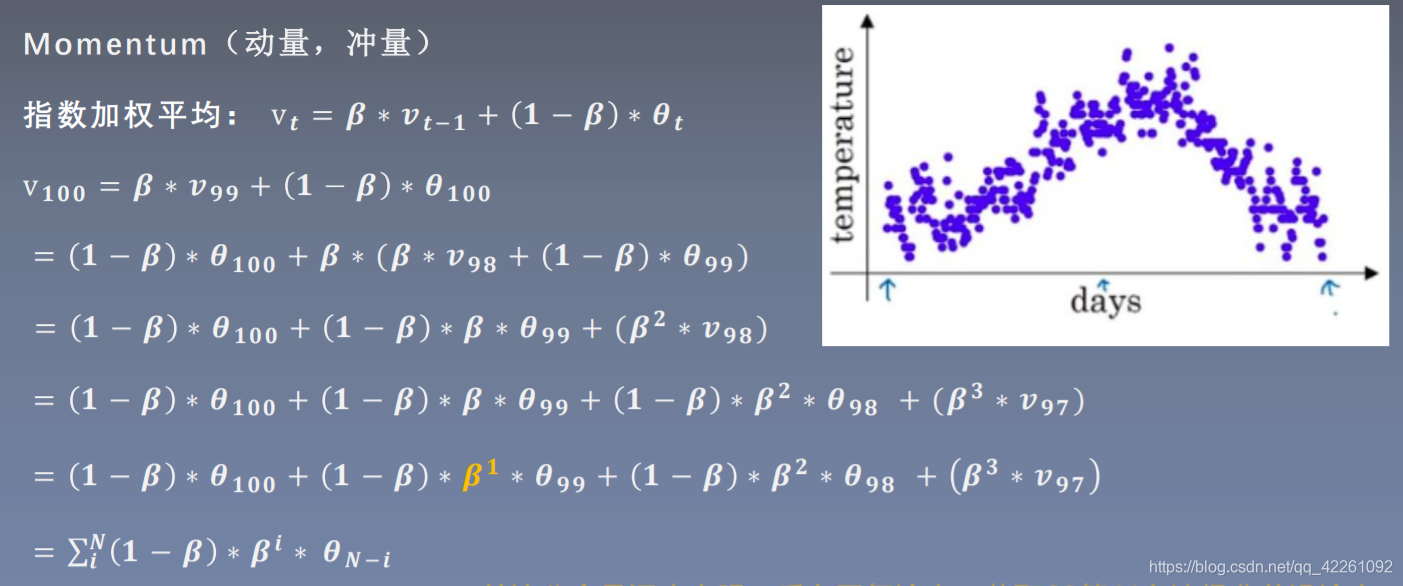
指数加权平均
100天温度的平均值 = β*第99天温度的平均值 + (1-β)*第一百天的温度
距离100天越远的那些天的温度的权重是越小的
β值可以理解为记忆周期的概念,β值越小记忆周期越短,β越大,记得越远,能把好些天之前的影响也算进来
1/(1-β)为记忆周期,如β=0.9,则表示更关注近10天左右的数据
-
添加了momentum(动量,冲量)的梯度下降
pytorch中加入动量的更新公式:当前更新量 = m系数×前一次更新量 +当前权重的梯度
加入动量之后能使模型收敛更迅速,在一些点位结合之前的更新量,更好的梯度下降(相当于增加一些步长的感觉)
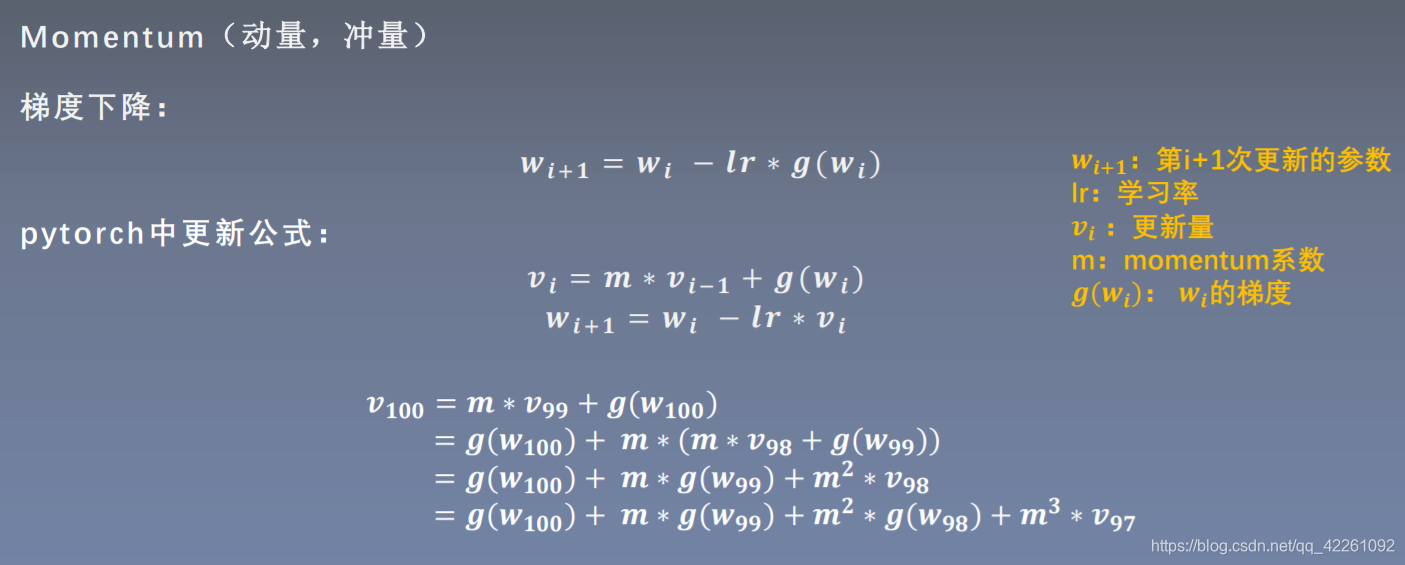
第100的更新量 = m×第99次的更新量 + 第100次的梯度
= 第100次的梯度 + m×第99次的梯度 + m²×第98次的更新量
= 第100次的梯度 + m×第99次的梯度 + m²×第98次的梯度 + m³×第97次的更新量
当前的更新量会考虑当前的梯度,上一的梯度,上上次的梯度...等等之前的梯度信息
lr = 0.01 M = 0 ; lr = 0.03 M = 0时;lr = 0.01的曲线收敛得更缓慢
lr = 0.01 M = 0.9 ; lr = 0.03 M = 0时;前一条曲线能够更快的达到loss = 0,但是因为momentun太大,后期会出现波动,将M改小为0.63
选择合适的momentum能够加速更新梯度信息
3、torch.optim.SGD

nesterov是一个布尔变量,决定是否采用NAG这个梯度下降方法,通常为false,即不采用
4、Pytorch的十种优化器
最常用的优化器为SGD,可以解决90%的问题
其次,还可以去了解一下Adam

- 1. optim.SGD: 《On the importance of initialization and momentum in deep learning 》
- 2. optim.Adagrad: 《Adaptive Subgradient Methods for Online Learning and Stochastic Optimization》
- 3. optim.RMSprop: http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf
- 4. optim.Adadelta: 《 AN ADAPTIVE LEARNING RATE METHOD》
- 5. optim.Adam: 《Adam: A Method for Stochastic Optimization》
- 6. optim.Adamax: 《Adam: A Method for Stochastic Optimization》
- 7. optim.SparseAdam
- 8. optim.ASGD:《Accelerating Stochastic Gradient Descent using Predictive Variance Reduction》
- 9. optim.Rprop:《Martin Riedmiller und Heinrich Braun》
- 10. optim.LBFGS:BDGS的改进


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









