







教程目录
零、引言
DeepSeek可以说最近已经刷爆全网。
2024年12月,DeepSeek-V3在全球AI领域掀起巨大波澜,它以极低的训练成本,实现了与GPT-4o等顶尖模型相媲美的性能,震惊业界。
随着DeepSeek推出新模型DeepSeek-R1,1月27日,Deepseek应用登顶苹果中国地区和美国地区应用商店免费App下载排行榜,在美区下载榜上超越ChatGPT。

之所以DeepSeek可以从众多模型之中异军突起,是因为它不仅率先实现了媲美OpenAI-o1模型的效果,更是将推理模型的成本压缩到了极低。DeepSeek的最大优势在于算法的改进和优化,如果说OpenAI是“大力出奇迹”,那么DeepSeek是小力也可以出奇迹。
在1月底的世界经济论坛年会开幕当天,中国深度求索公司发布其最新开源模型R1,再次引发全球人工智能领域关注。
DeepSeek-R1在技术上实现了重要突破——用纯深度学习的方法让AI自发涌现出推理能力,在数学、代码、自然语言推理等任务上,性能比肩OpenAI-o1模型正式版,该模型同时延续了该公司高性价比的优势。DeepSeek-R1模型训练成本仅为560万美元,远远低于美国开放人工智能研究中心、谷歌、“元”公司等美国科技巨头在人工智能技术上投入的数亿美元乃至数十亿美元。
关于价格,创始人梁文锋曾在接受媒体采访时表示,无论是API还是AI都应该是普惠的、人人可以用得起的东西。
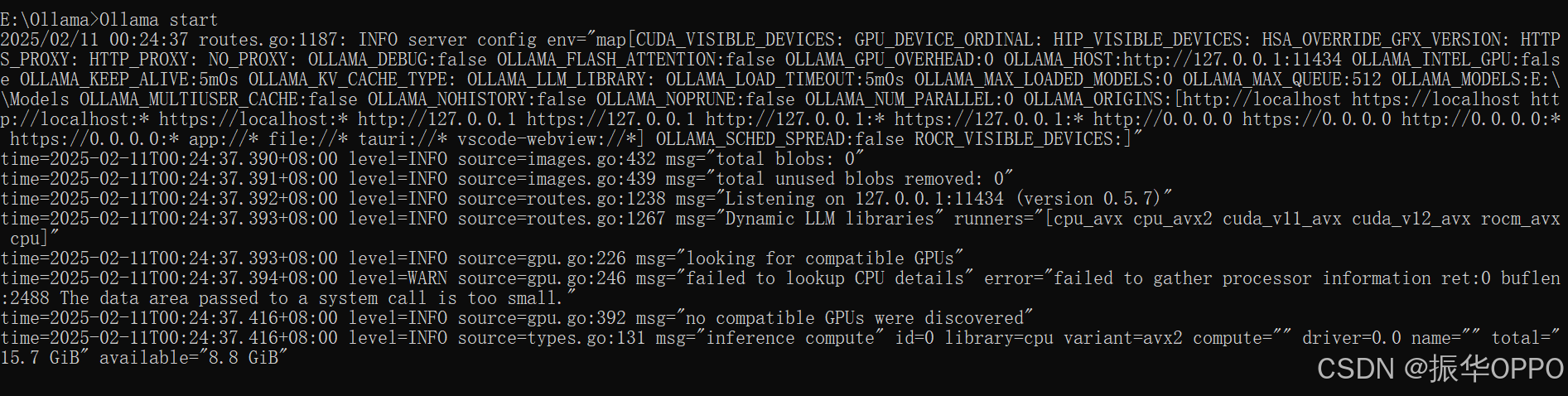
因此你无论在什么网站或者公众号中都能看到DeepSeek的身影。因为热度太高,访问量太大,官方服务器经常会出现下面的情况:

因此,本地部署主要是为了3点:1.响应速度快。 2.数据安全性高。 3.亲自动手体验。
部署大模型的步骤非常简单,一行命令就可以搞定,因为Ollama框架帮我们完成了所有的源码下载、环境配置和启动运行的步骤。
需要注意,Ollama运行时,会检测本地的GPU硬件,如果电脑没有 NVIDIA 或 AMD 的 GPU,则无法正常使用,因此部署大模型的前提是需要电脑有图形处理器能够兼容Ollama。
一、安装Ollama
1、简介
Ollama是一个用于在本地运行大型语言模型(LLM)的开源工具。
- 本地部署:Ollama允许开发者在自己的计算机上加载和运行各种AI模型,无需依赖云端服务或昂贵的GPU服务器,从而降低了使用成本。
- 简化管理:提供了一个类似于软件包管理器的方式来下载和存储AI模型,用户可以通过简单的命令行操作来管理模型。还会自动优化模型加载和推理过程,提升执行效率。
- 跨平台支持:兼容多个操作系统,包括macOS、Linux和Windows(通过WSL),使得开发者可以在任何主流开发环境中使用Ollama运行AI模型。
2、下载
官网的下载链接是指向github仓库的,因此还是推荐使用我们国内的夸克网盘分享的链接:https://pan.quark.cn/s/57bda81b0391
3、安装
3.1、更改安装路径
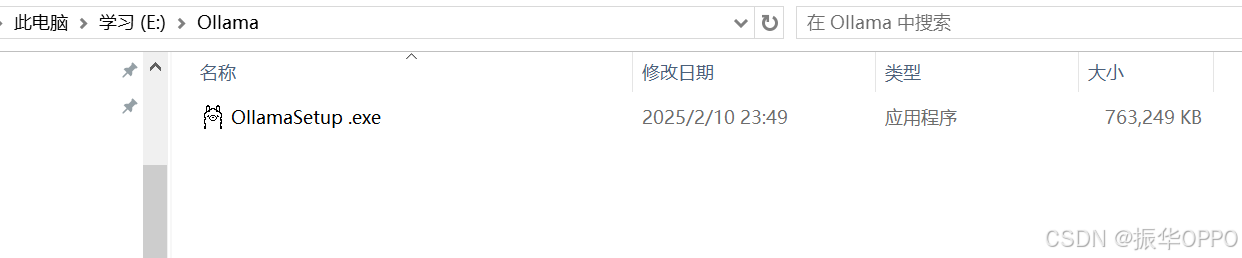
因为Ollama的安装程序非常简洁,就是解压文件,没有更换安装路径的选项,都是默认安装到C盘,而且软件占用空间很大,经常安装软件的同学肯定不会把它放在C盘,下面分享更改安装路径的方法。
在E盘新建一个目录Ollama,然后把下载好的安装程序剪切进来,就像这样:
然后在当前目录输入CMD回车进入命令行界面:
输入下面的指令,然后回车:
OllamaSetup.exe /DIR=E:\Ollama
#语法:软件名称 /DIR=Ollama的安装目录
然后点击Install开始安装。
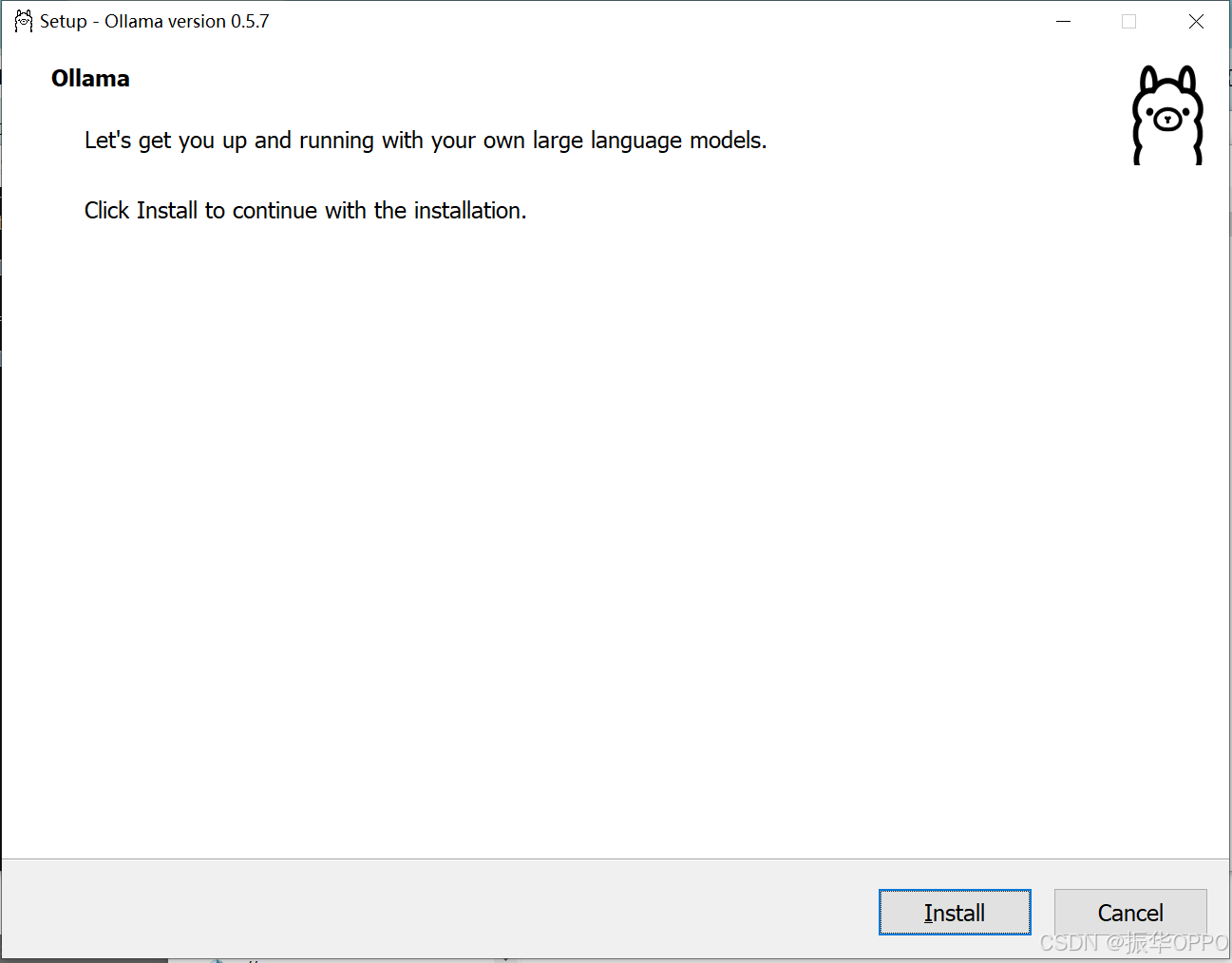
等待安装完成,会自动Running,可以看到Ollama的安装路径已经变成了我们指定的目录了:
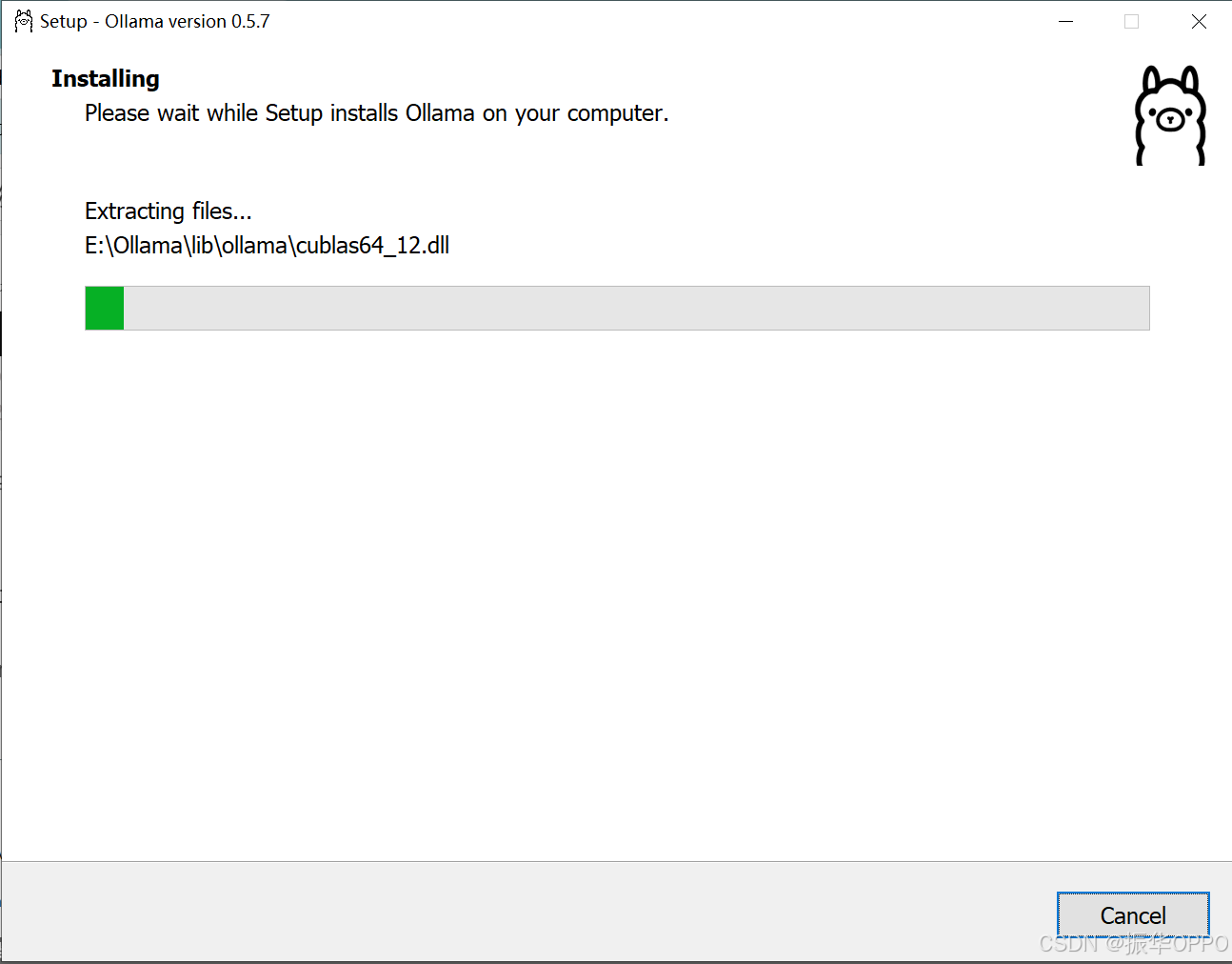
在Ollama命令行窗口中输入ollama -v,显示版本号说明安装成功。
3.2、更改大模型存储路径
在Ollama安装目录新建一个model目录。

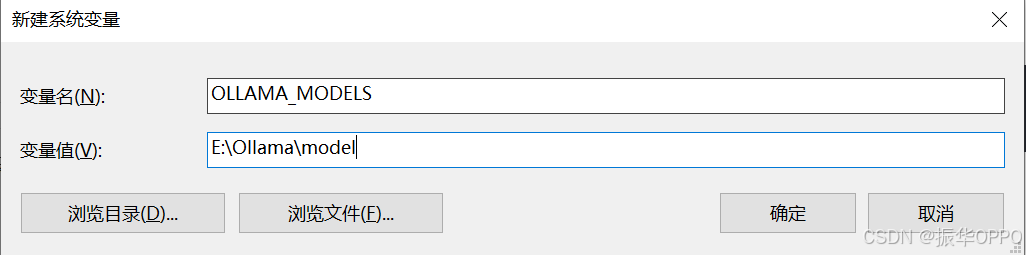
新建系统变量:
变量名:OLLAMA_MODELS
变量值:E:\Ollama\model
然后一直确定,重启Ollama程序,这样就设置了大模型的存储路径。
二、安装Deepseek-R1模型
1、点击Ollama官网的Models选项卡,出现所有的开源模型,按照下载量降序,显示模型名称、简介、常用版本、下载量、Tags、更新时间。我们的国产大模型之光——Deepseek跃居榜首,遥遥领先。
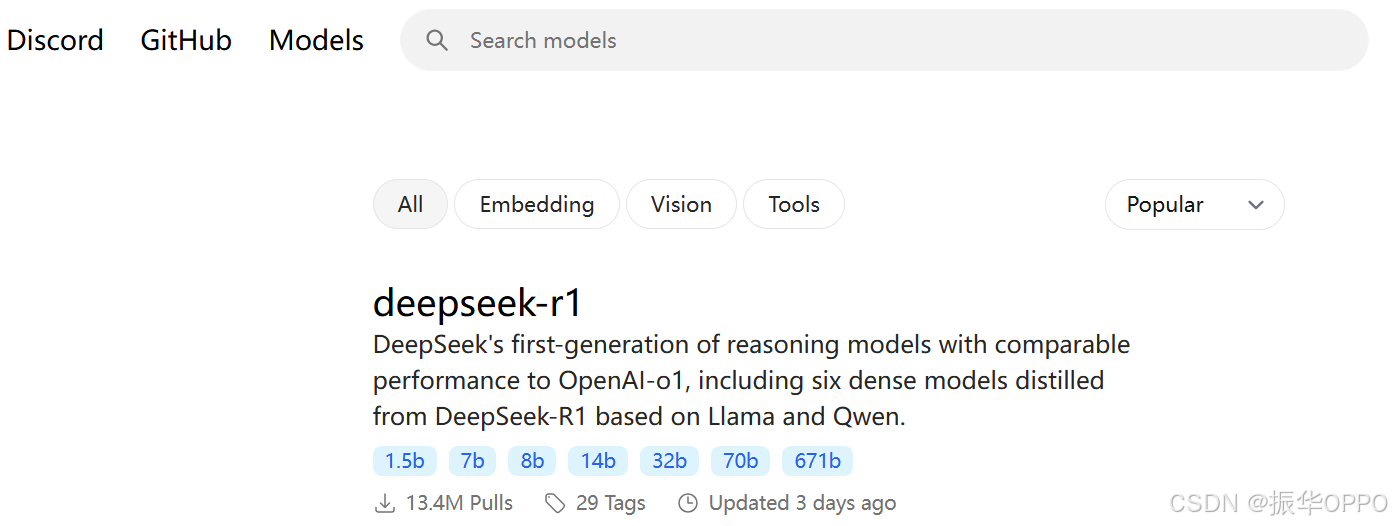
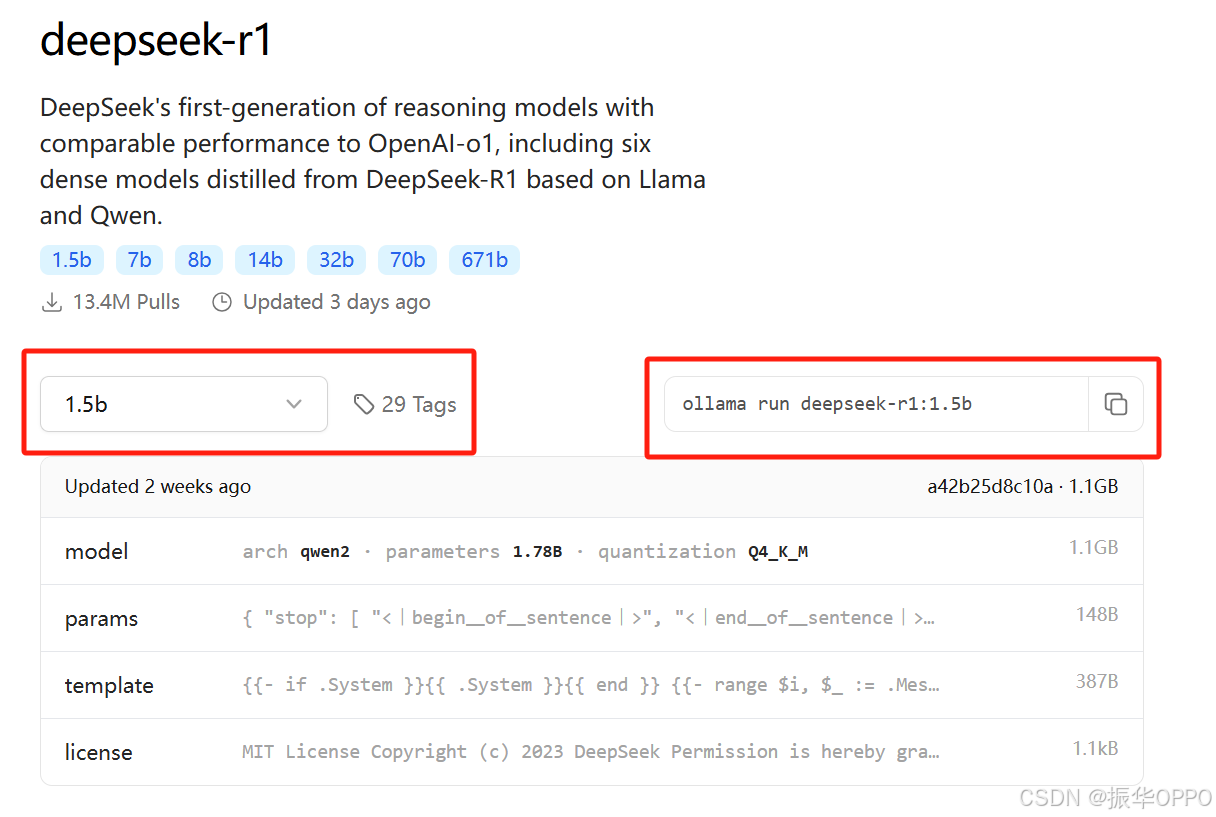
2、根据自己GPU的配置,选择合适的Tag,右侧会出现运行指令,复制下来。
3、不同参数量的模型对显卡的配置要求如下:
| 不一定非得4090才能本地部署 deepseek,真实测试结果是:1.5b 模型,4GB显存就能跑。 7b、8b 模型,8GB显存就能跑。 14b 模型,12GB显存能跑。 32b 模型,24GB显存能跑。 |
|---|
| 版本 | 配置 |
|---|---|
| DeepSeek-R1-1.5b | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-7b | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-8b | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-14b | NVIDIA RTX 3060 12GB or higher |
| DeepSeek-R1-32b | NVIDIA RTX 4090 24GB |
| DeepSeek-R1-70b | NVIDIA RTX 4090 24GB *2 |
| DeepSeek-R1-671b | NVIDIA A100 80GB *16 |
4、Ollama start启动窗口,若出现端口占用,则先netstat -aon | findstr 11434查看哪个进程占用了11434端口,然后taskkill /PID 18968 /F强制结束指定PID的进程。

5、在Ollama的命令行窗口中输入ollama run deepseek-r1:1.5b回车,开始pull模型。

6、下载过程中,最开始下载速度可能要快一些,下载到后面可能就几百KB了,此时我们可以按Ctrl+C停止下载,然后按上键再次执行下载,此时的下载速度又恢复到了几MB了。
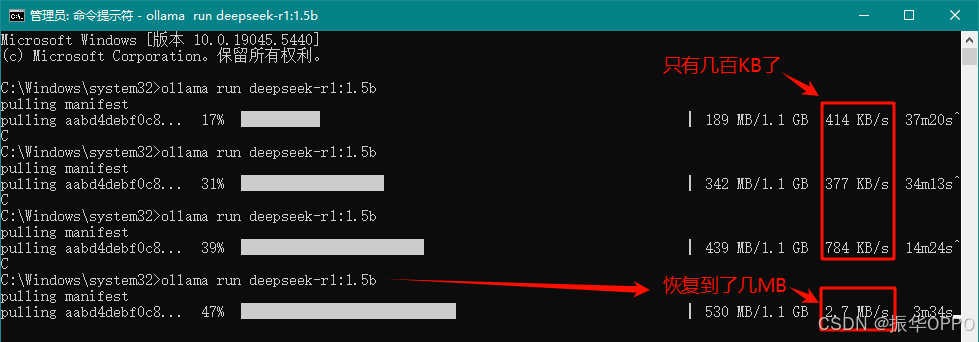
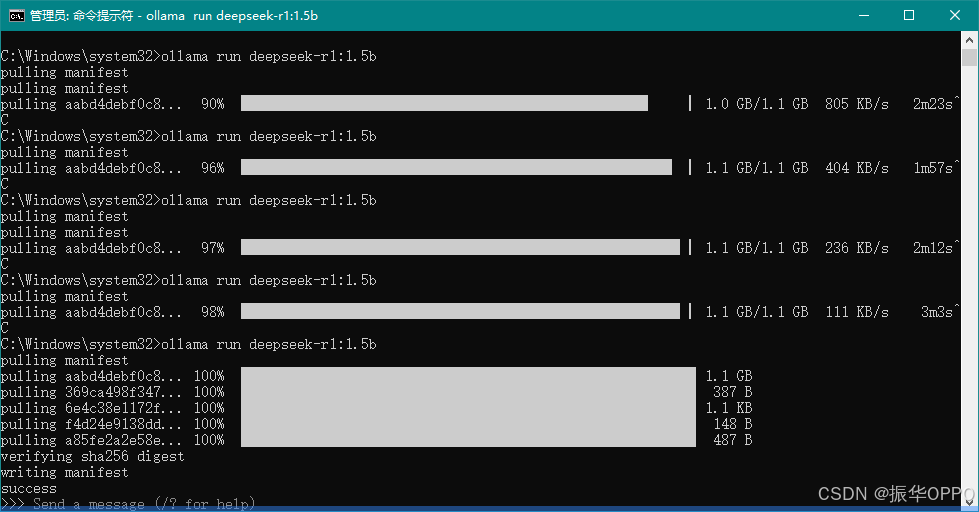
7、看到success信息就说明下载成功。

三、使用模型
1、在DeepSeek模型下载完成后,我们就可以在命令行窗口中与它对话:
2、假设我们安装了多个DeepSeek模型,我们可以通过ollama list命令查看已安装了的模型,如下图所示:

3、如果我们想运行某个模型,我们可以通过ollama run 模型名称命令运行即可,如下图所示:
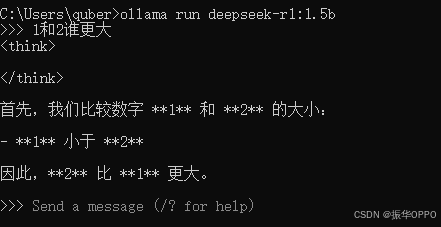
4、如果我们想退出对话,我们可以通过/bye命令退出,如下图所示:
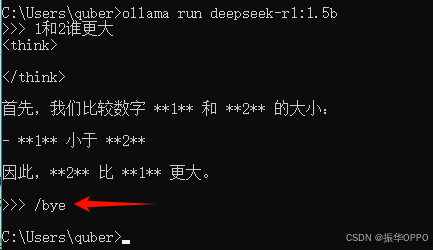
到此,DeepSeek R1的部署和使用就全部完成了。
四、Web UI对话
命令行界面因为没有任何格式,对用户不够友好。我们可以通过在线的Web UI 连接本地API进行对话。
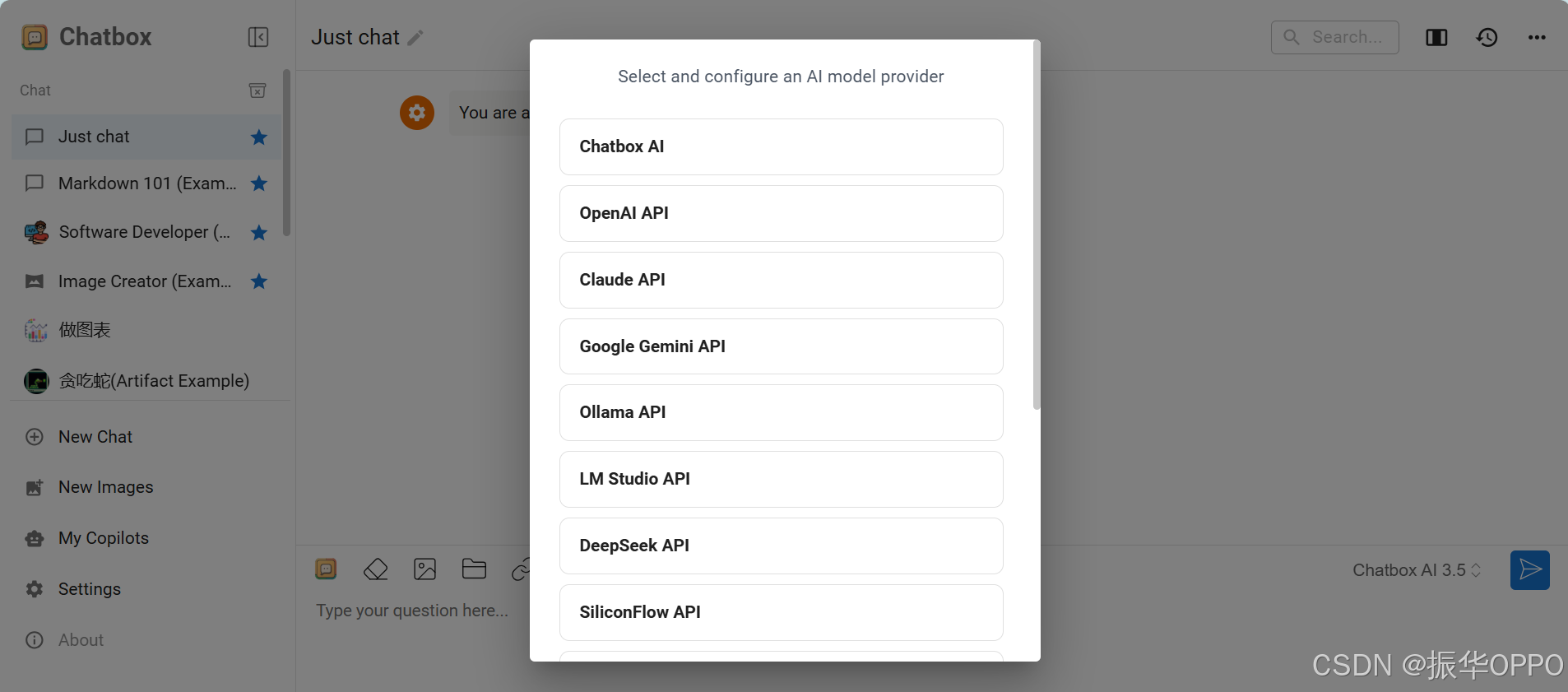
1、首先我们进入Chatbox官网(https://web.chatboxai.app/ ),打开后界面中间会有一个弹出框,我们选择Ollama API。
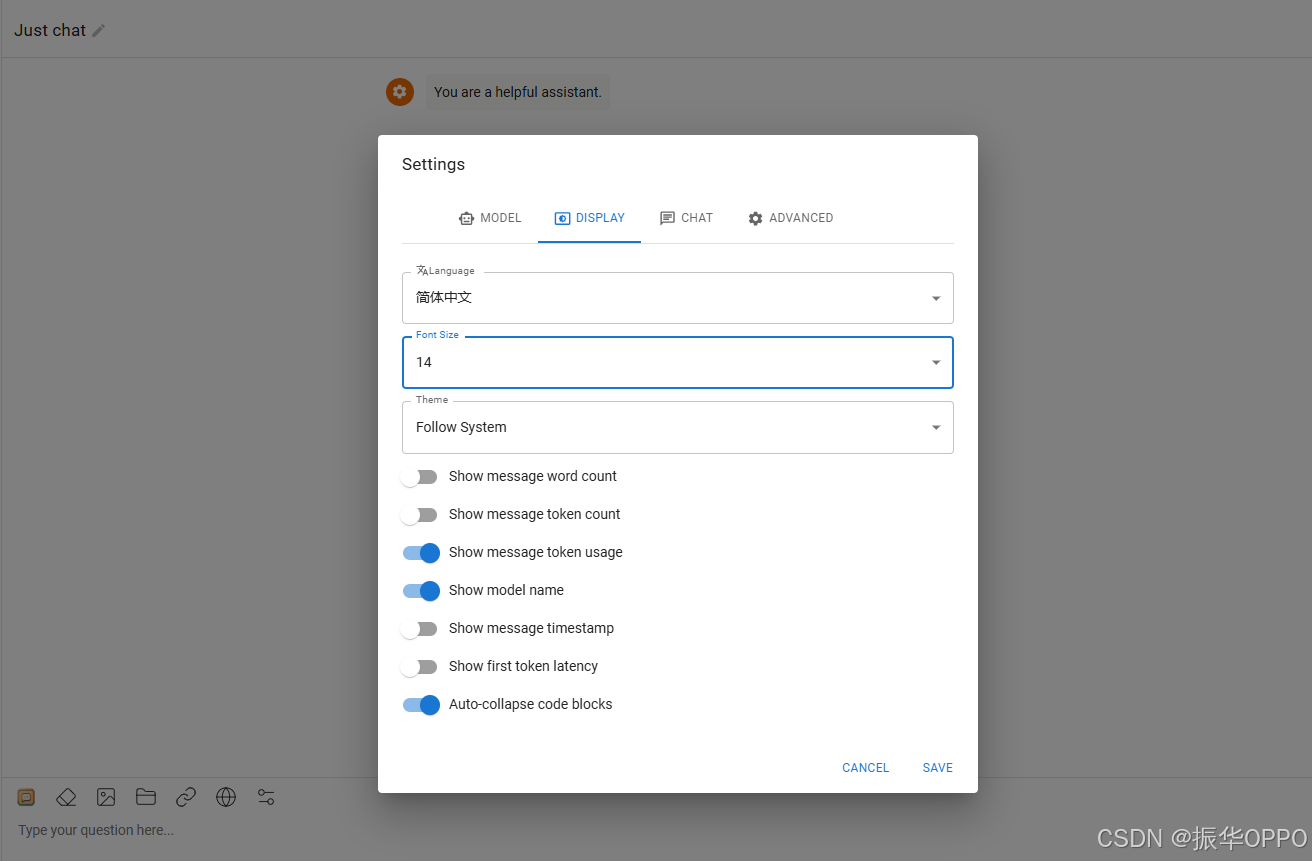
2、我们点击导航栏的DISPLAY,在第一个下拉框中选择简体中文,随后点击右下角的SAVE即可显示为中文了,如下图所示:
3、配置环境变量:在用户环境变量中新建下面两个变量,前面是变量名,后面是变量值,K-V结构。
OLLAMA_HOST 0.0.0.0
OLLAMA_ORIGINS *
4、配置好环境变量后,我们重启下Ollama,目的是让Chatbox能自动识别连接到Ollama服务,然后刷新下https://web.chatboxai.app/。
5、设置模型提供方和模型:点击左下角的设置按钮,然后在模型选项卡中选择模型提供方为Ollama API,模型选择deepseek-r1:1.5b,然后点击保存,如下图所示:
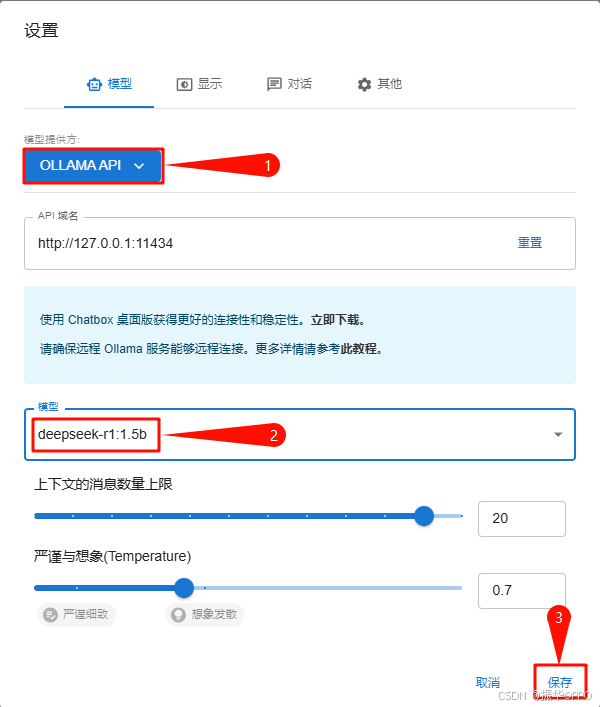
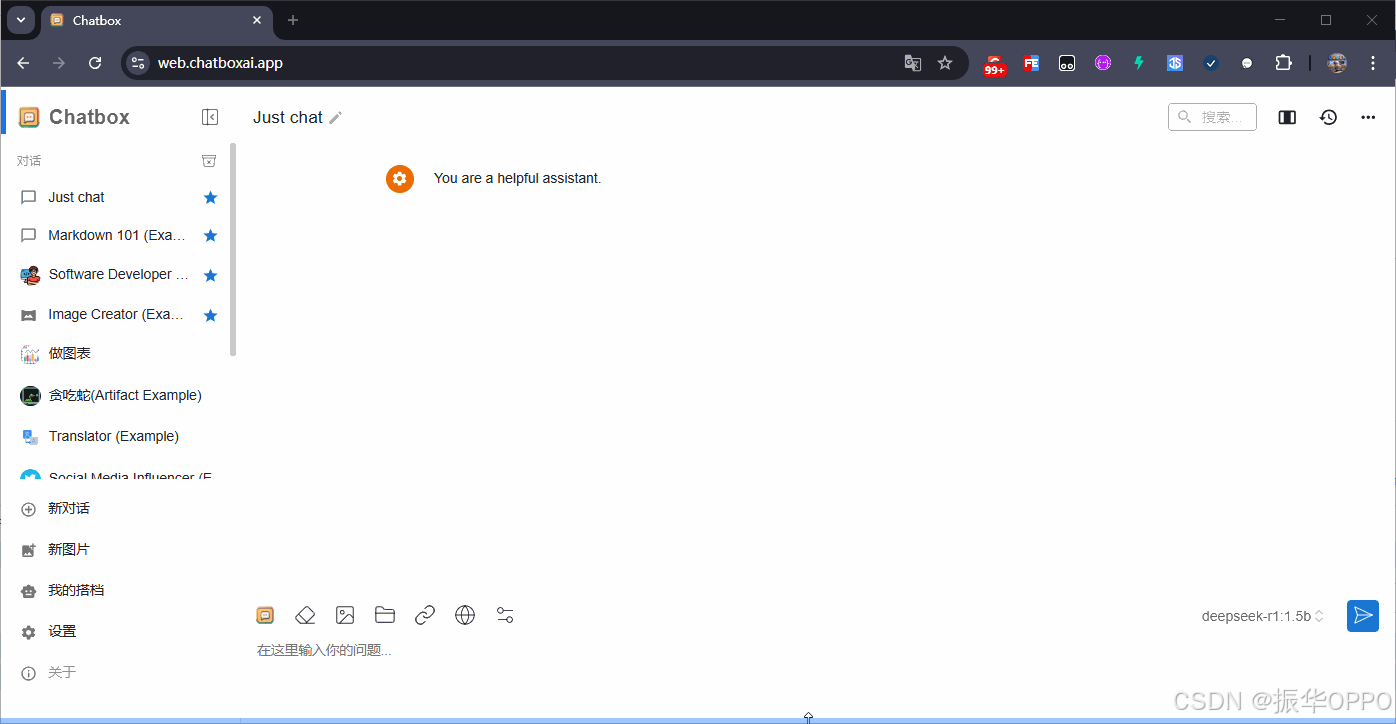
6、接下来我们就可以在Web端使用本地大模型进行对话和推理了。
五、补充
1、还可以使用规则库对下载的模型进行微调,让模型能够按照你设定的规则进行对话和推理。
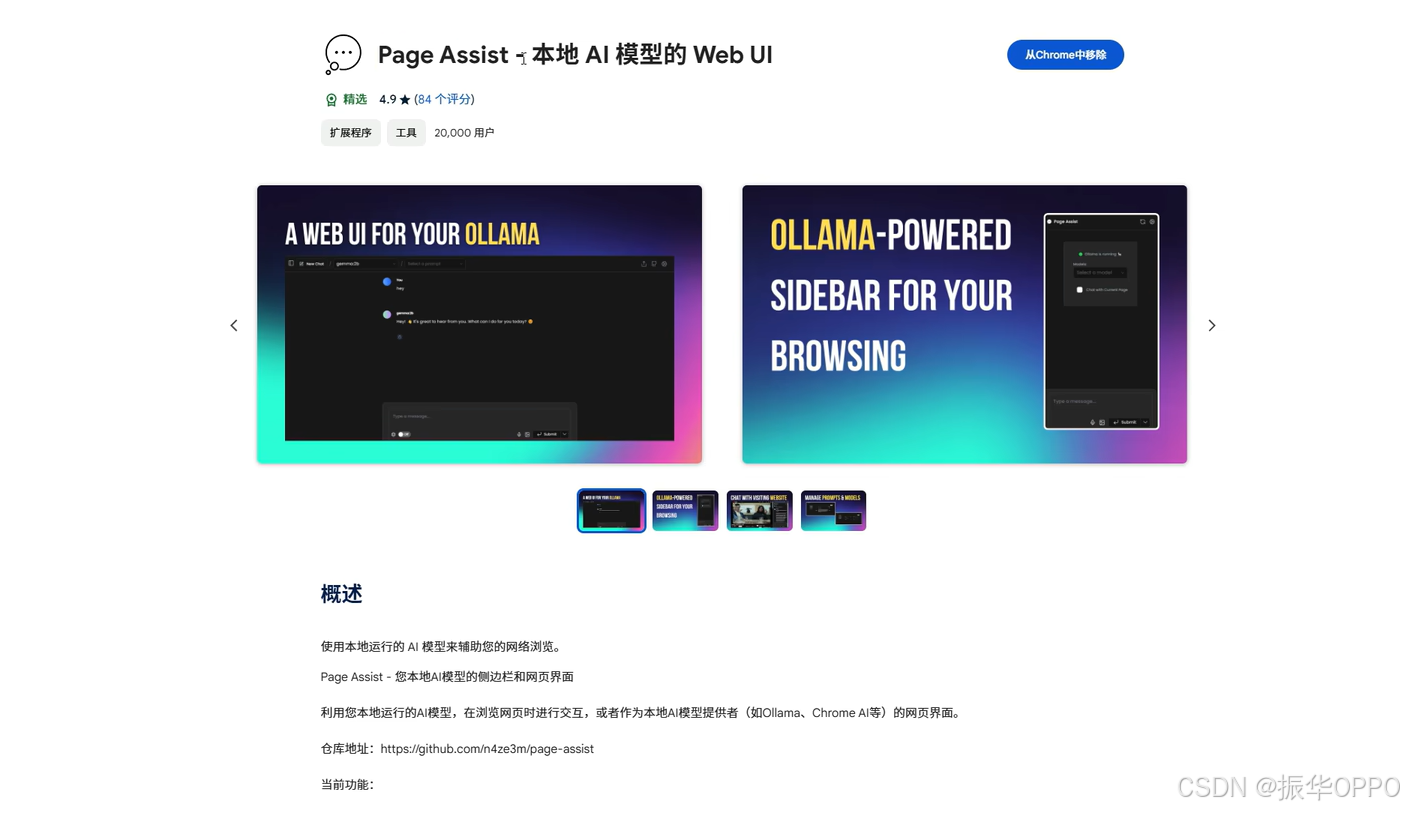
2、Chrome浏览器可以使用Page Assist插件实现本地模型的Web UI。
3、使用LM Studio完全断网地本地部署,行CPU和GPU的混合推理。
4、本地 RAG 应用实现,加载 PDF文档并将其切分为适当大小的文本块,使用 Chroma 数据库存储文档向量,并配置 Ollama 提供的嵌入模型,设置模型和提示模板,构建处理链,整合检索和问答功能。
from langchain_core.runnables import RunnablePassthrough
RAG_TEMPLATE = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
<context>
{context}
</context>
Answer the following question:
{question}"""
rag_prompt = ChatPromptTemplate.from_template(RAG_TEMPLATE)
retriever = vectorstore.as_retriever()
qa_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| rag_prompt
| model
| StrOutputParser()
)
question = "What is the purpose of the DeepSeek project?"
# Run
qa_chain.invoke(question)
参考链接:
https://www.cnblogs.com/qubernet/p/18702147
https://www.bilibili.com/video/BV1MsFkeoEGf/
六、总结
1、对DS的赞誉
Deepseek大模型在人工智能领域展现出了卓越的性能和巨大的潜力。它不仅在自然语言处理任务中取得了令人瞩目的准确率,还在量化投资、医疗诊断、教育辅导等多个领域发挥了重要作用。特别是在性价比方面,Deepseek模型相比其他顶级模型具有显著优势,这使得它更易于被广泛应用和推广。
OpenAI的联合创始人兼首席执行官Sam Altman对Deepseek的R1模型给予了高度评价,认为它是一款令人印象深刻的模型。这一认可不仅证明了Deepseek的实力,也进一步推动了人工智能领域的竞争和发展。国内各大厂商也争先恐后地接入DeepSeek-R1大模型。
2、对程序员的寄语
雷军说:“AI是如今最热门的科技创新话题,年轻人应尽快适应这个新时代,学会利用AI工具解决问题。”雷军强调年轻人要尽快学会AI,近日这个话题还登上了微博热搜。
AI再强,也只是个工具,程序员才是掌控工具的大佬。所以,程序员的未来,不是淘汰,而是起飞。程序员要做的就是接受AI,学习AI,使用AI,成为新时代的复合型人才。能够掌握AI的人,才是未来的赢家。
站在时代的分水岭上,有人看到的是深渊,有人看到的却是满天星群。机会,永远留给有准备的人的。在AI时代,学会AI、善用AI就是你最好的准备!
3、对AI未来的期望
对于Deepseek大模型的未来,我们充满期待和信心。希望它能够持续进化升级,不断提升技术性能和应用范围。同时,我们也期望Deepseek能够积极应对数据安全、隐私保护等挑战,确保用户权益得到充分保障。
此外,我们还希望Deepseek能够带动更多企业和机构加大在人工智能领域的投入,共同推动技术的不断进步和创新。相信在Deepseek等领先企业的引领下,人工智能领域将迎来更加繁荣和美好的未来!

色盗人精竭者死,要知精力有限时,不节色欲定夭折,人虽未老身先衰。银钱人人多吝惜,不晓吝惜精力身。不爱自身骨髓液,反爱银钱斗死生。天律淫罪最严厉,人祸淫为最惨凄。酒不醉人人自醉,色不迷人人自迷。奉劝世人当自省,色淫两件深戒之,道德善书常阅读,百病顿消大丈夫。


















 946
946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











