




 Spark作为一站式大数据处理引擎,提供快速、易用、通用的计算能力。基于内存的计算模型使其速度远超MapReduce,同时集成Hadoop实现数据存储与资源调度。Spark支持多种计算模式,包括离线批处理、交互式查询、流式计算、机器学习和图计算。
Spark作为一站式大数据处理引擎,提供快速、易用、通用的计算能力。基于内存的计算模型使其速度远超MapReduce,同时集成Hadoop实现数据存储与资源调度。Spark支持多种计算模式,包括离线批处理、交互式查询、流式计算、机器学习和图计算。
Spark简介
Spark概述
- Spark是一个一站式大数据计算框架。可以通过一个技术堆栈处理大数据各种领域的各种计算任务。就是一个通用的大数据快速处理引擎。
- Spark的各个组成部分
- Spark core 用于离线计算
- Spark SQL 用于交互式的查询
- Spark Streaming
- Spark MLlib 用于机器学习
- Spark GraphX 用于图计算
- Spark主要用于大数据的计算,hadoop主要用于大数据的存储、资源调度等所以我们正常工作都会结合Spark与Hadoop使用
- Spark是一个基于内存的计算框架,速度可以达到MapReduce的数倍甚至数十倍
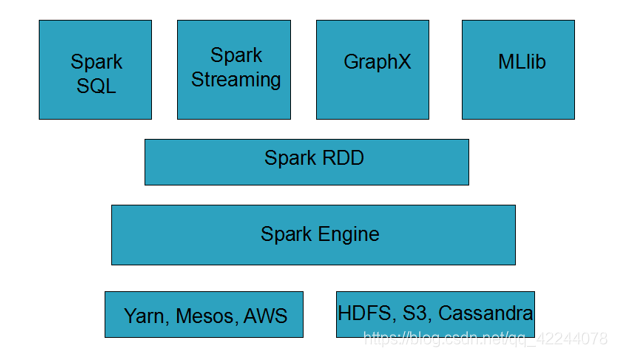
Spark整体架构
- 底层是资源调度管理以及数据存储
- 资源调度:常用yarn、也可以用Spark自己的等
- 数据存储:HDFS、S3等
- 中间层是Spark Engine和Spark RDD 其实就是Spark Core
- 上层是:Spark Sql、Spark Streaming、GraphX、MLlib
Spark的特点
- 速度快::基于内存进行的计算也有部分过程需要基于磁盘。
- 容易上手:是基于RDD的计算模型,比MapReduce更加易于理解,可以使用更加简单的操作完成比较复杂的运算
- 超强的通用性:Spark提供了Spark RDD、Spark SQL、Spark Streaming、Spark MLlib、Spark
GraphX等技术组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务 - 集成Hadoop:与hadoop高度集成,可以完美的配合使用。
Spark与其他框架的比较
-
Spark 与 MapReduce的比较
-
type Spark MapReduce 计算模型 基于RDD 基于map+reduce 运算速度 基于内存速度非常快 需要经过磁盘速度慢 可靠性 基于内存可靠性低 可靠性高 -
MapReduce计算模型太过死板,必须要经历map+reduce必须要经过shuffle过程,十分消耗性能。Spark则可以避免,只需要简单的shuffle。
-
spark基于内存的运算如果在进行大批量数据处理的话可能会产生内存溢出等风险,而MapReduce不会,虽然慢但是可靠性高
-
-
Spark SQL 与 hive 的比较
- hive是一个基于hdfs的数据仓库,并且提供了基于SQL模型的分布式查询引擎
- Spark SQL可以替代的是hive的查询引擎,在实际运用中spark SQL也是基于hive进行数据查询,spark自身是不存储数据的
- spark SQL相对于hive的查询引擎来说速度很快,同样的SQL语句spark SQL速度要比基于MapReduce的hive搜索引擎快的多
- 而Spark
SQL相较于Hive的另外一个优点,就是支持大量不同的数据源,包括hive、json、parquet、jdbc等等。此外,SparkSQL由于身处Spark技术堆栈内,也是基于RDD来工作,因此可以与Spark的其他组件无缝整合使用,配合起来实现许多复杂的功能。比如SparkSQL支持可以直接针对hdfs文件执行sql语句
-
Spark Streaming 与 Storm 的比较
-
type Spark Streaming Storm 计算模型 是近实时处理框架 全实时处理框架 延迟度 最高支持秒级别的延迟 可以支持毫秒级别的延迟 吞吐量 因为是批处理所以吞吐量高 吞吐量相对来说较低 动态调整并行度 不支持 支持 事务机制 支持但是不够完善 支持且完善
-
Spark的应用场景
- 首先是spark对于MapReduce可以立即替换且效果较好的,就是要求低延时,复杂大数据交互式计算系统。
- 比如某些大数据系统,可以根据用户提交的各种条件,立即定制执行复杂的大数据计算系统,并且要求低延时(一小时以内)即可以出来结果,并通过前端页面展示效果。在这种场景下,对速度比较敏感的情况下,非常适合立即使用Spark替代MapReduce。因为Spark编写的离线批处理程序,如果进行了合适的性能调优之后,速度可能是MapReduce程序的十几倍。从而达到用户期望的效果
- 其次是相对于hive来说,Ø对于某些需要根据用户选择的条件,动态拼接SQL语句,进行某类特定查询统计任务的系统,其实类似于上述的系统。此时也要求低延时,甚至希望达到几分钟之内。此时也可以使用SparkSQL替代Hive查询引擎。此时使用Hive查询引擎可能需要几十分钟执行一个复杂SQL,而使用Spark SQl,可能只需要使用几分钟就可以达到用户期望的效果
- 最后,对于Storm来说,如果仅仅要求对数据进行简单的流式计算处理,那么选择storm或者spark streaming都无可厚非。但是如果需要对流式计算的中间结果(RDD),进行复杂的后续处理,则使用Spark更好,因为Spark本身提供了很多功能,比如map、reduce、groupByKey、filter等等。

















 4824
4824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









