






问题:
编译器编译源码之后生成的文件叫做目标文件。那么目标文件里面具体有啥呢?
目标文件从结构上讲,它是已经编译后的可执行文件格式,只是还没经历过链接的过程,其中可能有些符号或者地址还没有被调整。但是其本身就是按照可执行文件格式存储的,只是跟真正的可执行文件在结构上稍有不同。
1. 目标文件的格式
可执行文件格式:
- 在Windows系统下,主要是PE格式(Portable Executable)
- 在Linux系统下,主要是ELF格式(Executable Linkable Format)
其都是COFF(Common file format)格式的变种。
不光 可执行文件(Windows 的.exe和Linux 下的ELF可执行文件)按照可执行文件格式存储。
动态链接库(DLL,Dynamic Linking Library)(Windows的.dll和linux中的.so)
静态链接库(Static Linking Library)(Windows的.lib与linux下的.a)
ELF文件标准里面把系统中采用的ELF格式的文件视为4类
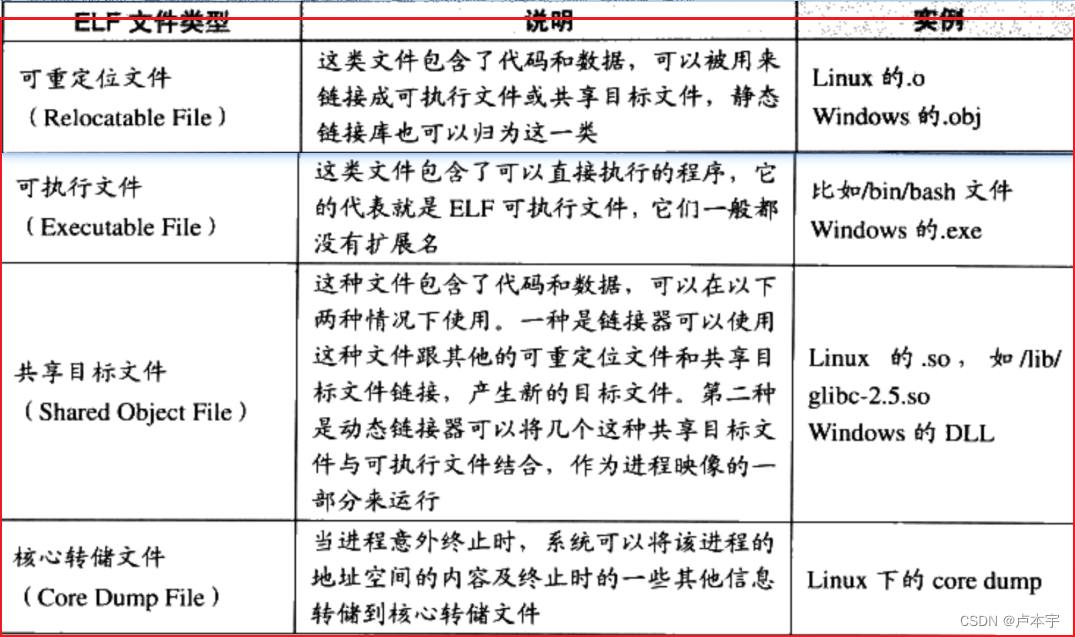
2. 目标文件是怎么样的
目标文件中按照信息的不同属性,以“段”的形式存储。以下为不同属性的数据、指令存放的具体位置:
- 代码段:程序源代码编译后的机器指令被放在代码段中(code section),常见的名字有".code"或者".text".
- 数据段:全局变量和局部静态变量数据放在数据段(data section),一般名字叫.data
- .bss段:未初始化的全局变量以及局部静态变量都存放在该段中。它是指为未初始化的全局变量等预留位置而已,并没有内容,所以其在文件中不占据空间。
数据与指令分段的好处:书本第59页
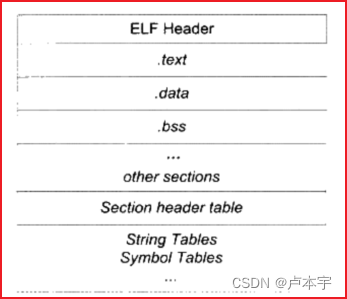
下图为C语言程序被编译成目标文件之后的结构:
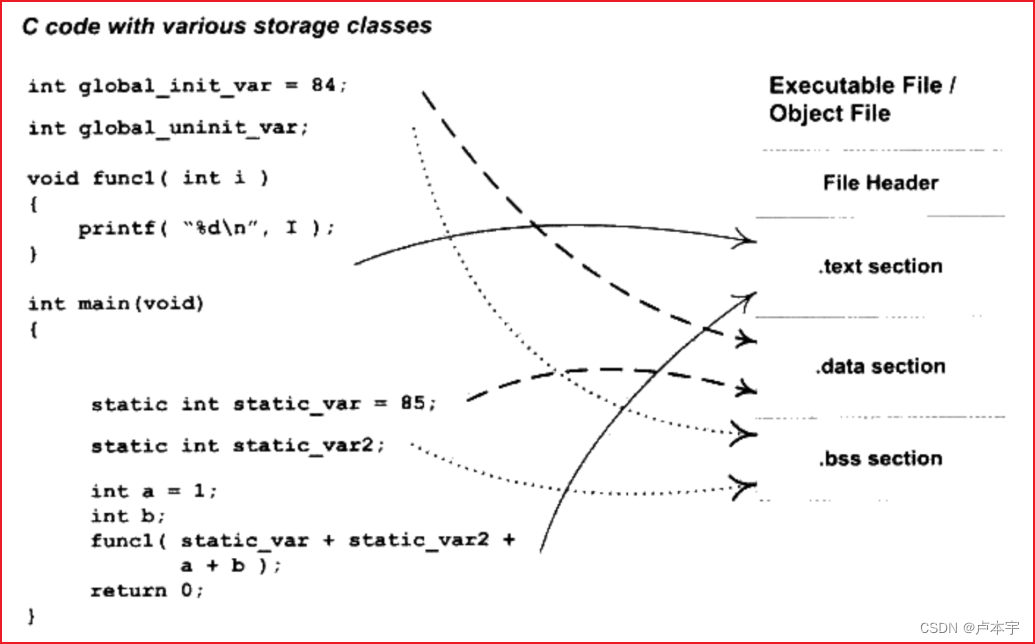
ELF文件的开头是一个 文件头:它描述了整个文件的属性,包括文件是否可以执行、是静态链接还是动态链接或者是入口地址等信息。文件头还包括一个 段表,段表是一个描述文件中各个段的数组。段表描述了文件中各个段在文件中的偏移位置以及段的属性等。
3. 实例分析目标文件
以下面程序经过编译和汇编形成的目标文件SimpleSection.o文件进行分析:
int printf(const char* format, ...);int global_init_var = 84;int global_uninit_var;void func1(int i){ printf("%d\n",i);}int main(void){ static int static_var = 85; static int static_var2; int a = 1; int b; func1(static_var + static_var2 + a + b); return a;}
通过下面语句对该源代码进行编译汇编形成目标文件:
gcc -c SimpleSection.c
查看ELF文件内部结构
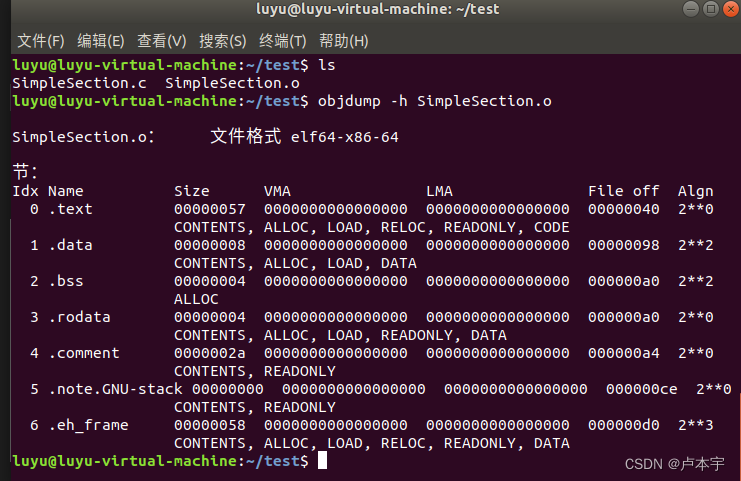
然后使用linux内置的objdump工具查看目标文件内部的结构:其会将目标文件的各个段的基本信息打印出来。
objdump -h SimpleSection.c
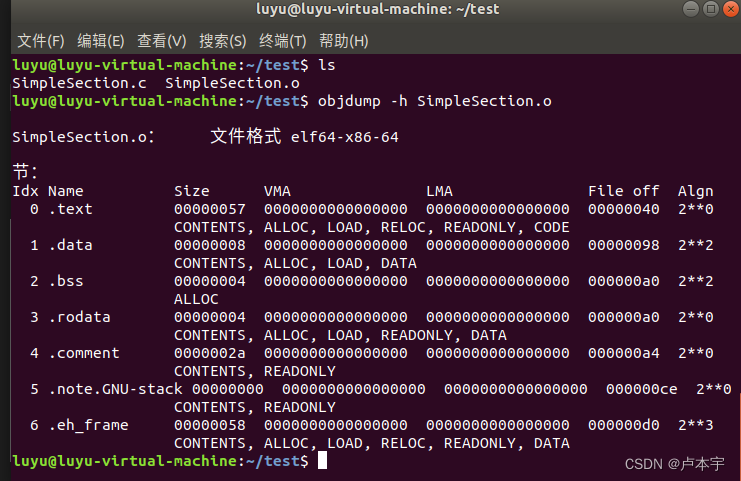
其中除了之前介绍的 .text、.data、.bss 等几个段之外,还有三个段分别是:
- 只读数据段(.rodata):
- 注释信息段(.comment):
- 堆栈提示段(.note.GUN-stack):
然后是几个段的属性,比较容易理解的是长度(size)和段所在位置(file offset)
每个段的第二行中的 “CONTENTS”、"ALLOC"等表示段的各种属性,
- “CONTENTS”表示该段在文件中存在,可以看见.bss段没有,因此其在ELF文件中不存在内容
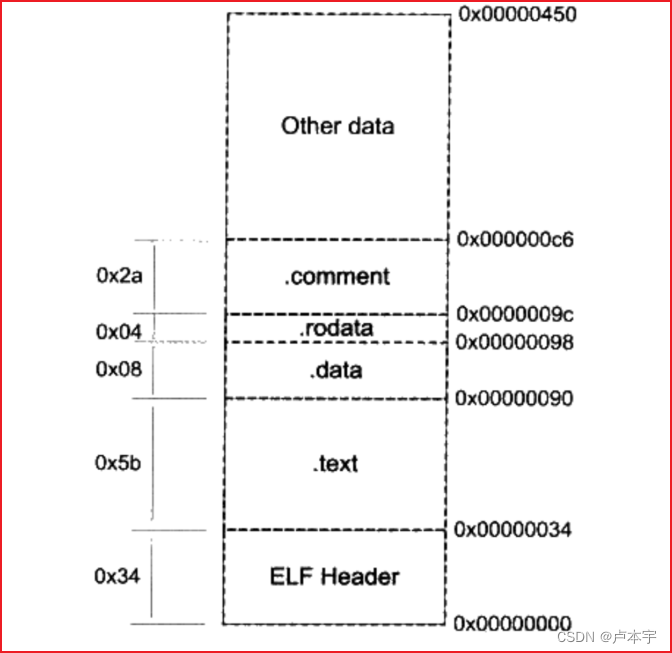
下图为各段在ELF文件中的布局。
通过size命令来查看ELF文件的代码段、数据段、BSS段的长度
size SimpleSection.o

通过-S命令以十六进制打印所有段内容
objdump -s SimpleSection.o
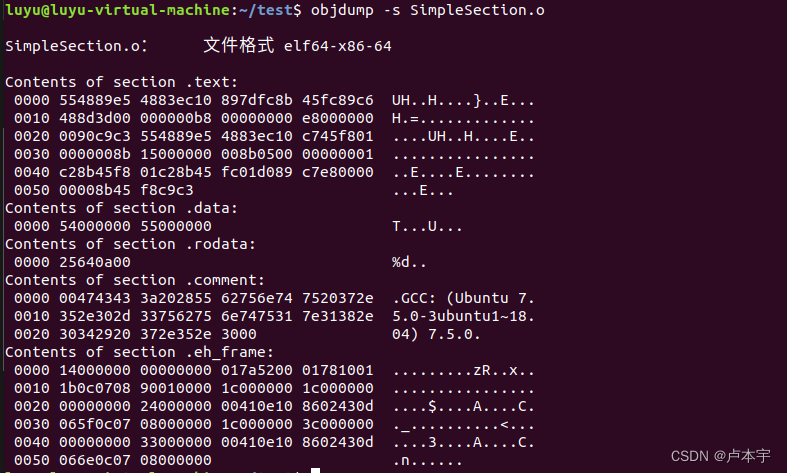
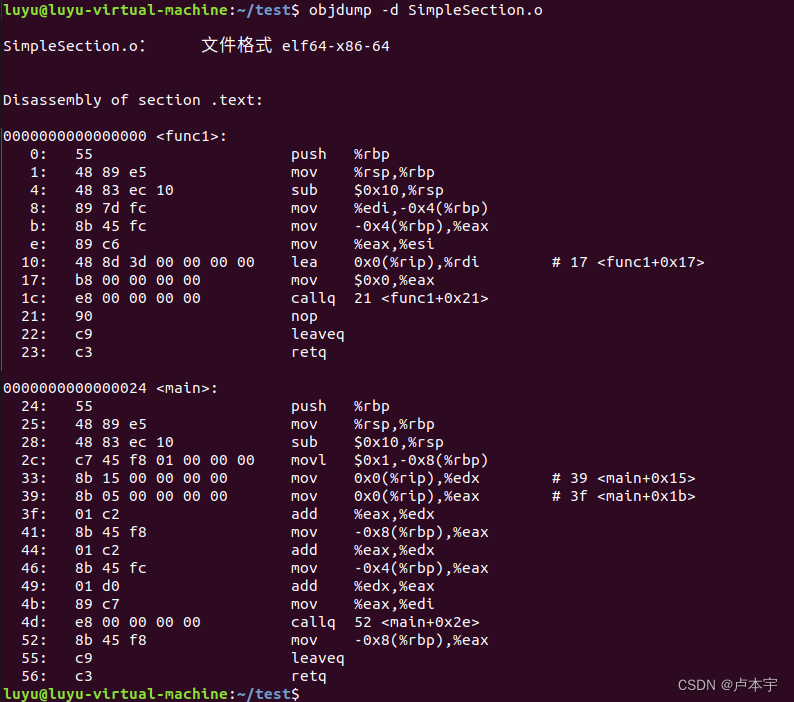
3.1 代码段内容分析
通过-d命令反汇编指令内容
objdump -d SimpleSection.o
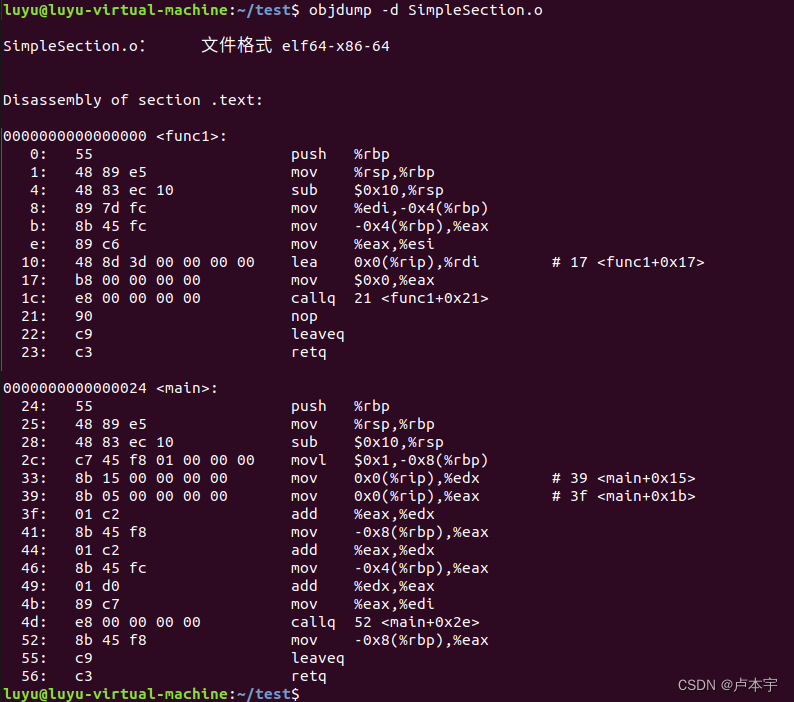
3.2 数据段和只读数据段
- .data段:保存的都是初始化了的全局静态变量和局部静态变量,代码中分别是global_init_var与static_var两个变量,一共8个字节。所有.data这个段中有8个字节。
- .rodata段:存放到的是只读数据,一般是程序里的只读变量(如const修饰的)和字符串常量。这里的4个字节存放的是%d这个字符串常量
3.3 BSS段
- .bss段:存放的是未初始化的全局变量和局部静态变量。上述代码中global_uninit_var与static_var2存放在.bss段,但是在符号表中只有static_var2存放在了.bss段,这跟编译器实现有关。
最终会在连接成可执行程序的时候再给.bss段分配空间。
Quiz变量存放位置

3.4 其他段
下面列举了一些常见的段:
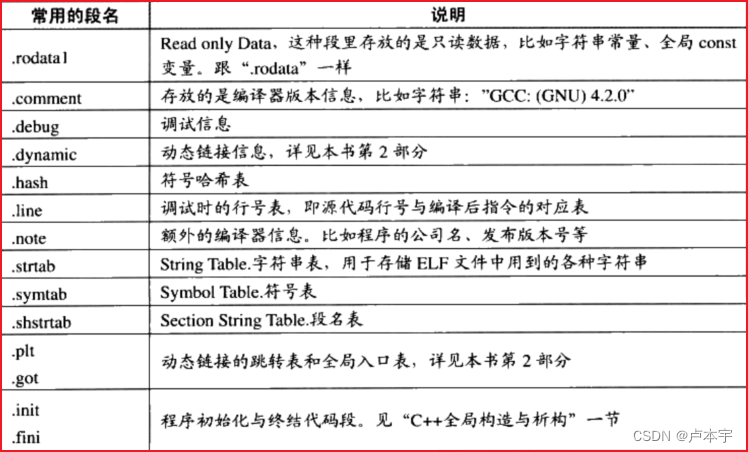
自定义段
正常情况下,GCC编译出来的目标文件中,代码会被放到“.text”段,全局变量和静态变量会被放到“.data”和“ .bss”段,正如我们前面所分析的。但是有时候你可能希望变录或某些部分代码能够放到你所指定的段中去,以实现某些特定的功能。比如为了满足某些硬件的内存和IO的地址布局,或者是像Linux 操作系统内核中用来完成一些初始化和用户空间复制时出现页错误异常等。GCC提供了一个扩展机制,使得程序员可以指定变量所处的段,
__attribute__((section("FOO"))) int global = 42;__attribute__((section("BAR"))) void foo(){}
在全局变量或函数之前加上“attribute((section("name")))”属性就可以把相应的变量或者函数放到以name作为段名的段中。
4. ELF文件结构描述
总体结构描述:
4.1 文件头
作用:描述整个文件的信息,控制整个文件的属性。
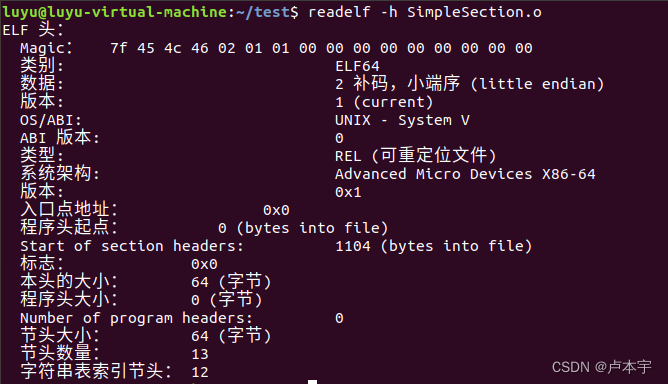
可以使用readelf命令详细查看ELF文件的文件头信息;
readelf -h SimpleSection.o
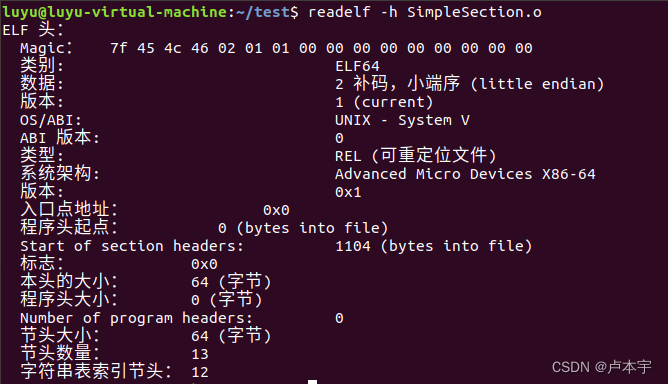
ELF文件头结构成员含义
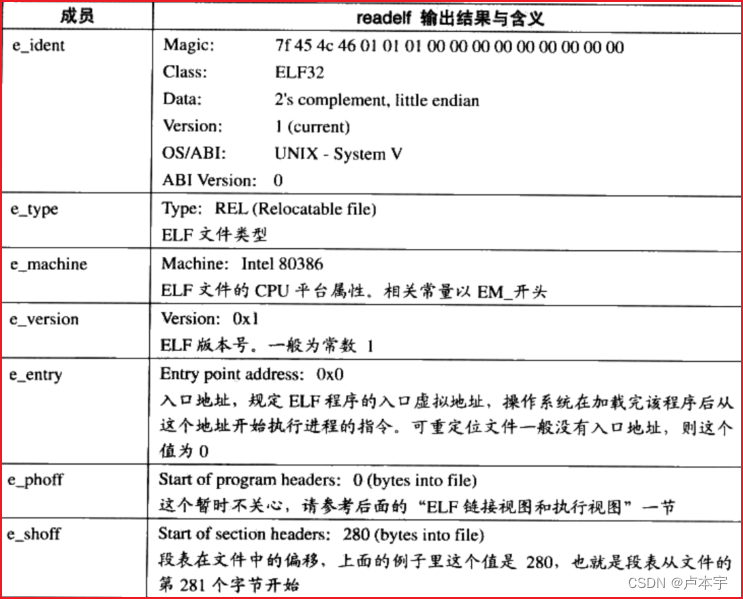
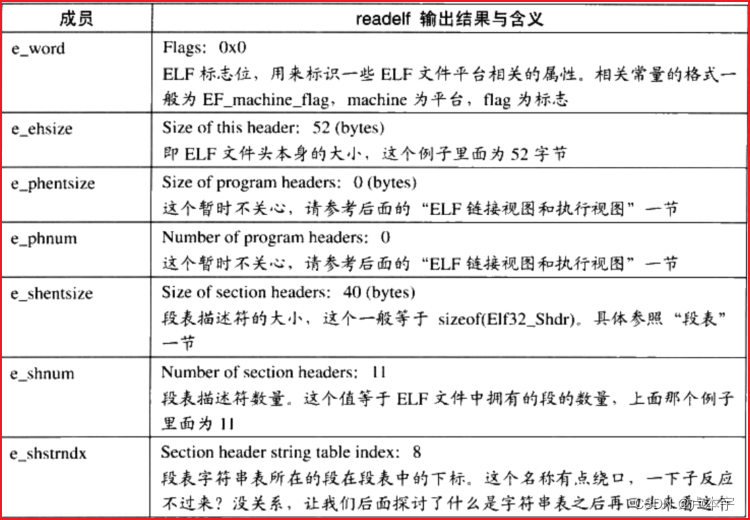
- 魔数:这16个字节主要用来标识ELF文件的平台属性。
- 前四个字节0x7f、0x45、0x4c、0x46,第一个字节对应ASCLL字符的DEL控制符,后面三个字节正好是ELF三个字母的ASCLL码。这种魔数用来确认文件的类型。
- 第五个字节是用来标识ELF的文件类别的,0x01表示是32位的,0x02是64位的
- 第六个字节表示字节序,规定是大端还是小端序,0x01表示是小端序
- 第七个字节规定ELF文件的主版本号,一般是1
- 文件类型:e_type成员表示ELF文件类型,即前面提到过的三种ELF文件类型,每一个对应一个常量。

- 机器类型:虽然ELF文件格式被设计成多个平台下可以使用,但是并不表示同一个ELF文件能在所有平台使用。
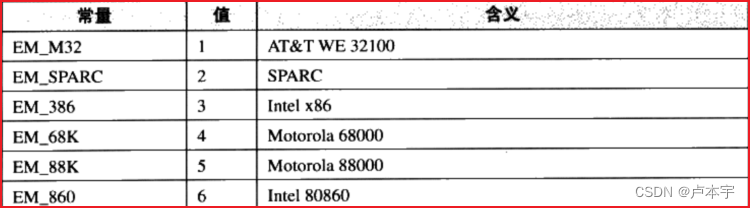
4.2 段表
作用:用来保存段的基本属性
ELF文件中有很多各种各样的段,这个段表就是保存这些段的基本属性的结构。
通过readelf的 -s参数来查看elf文件中段表所有信息
readelf -S SimpleSection.o
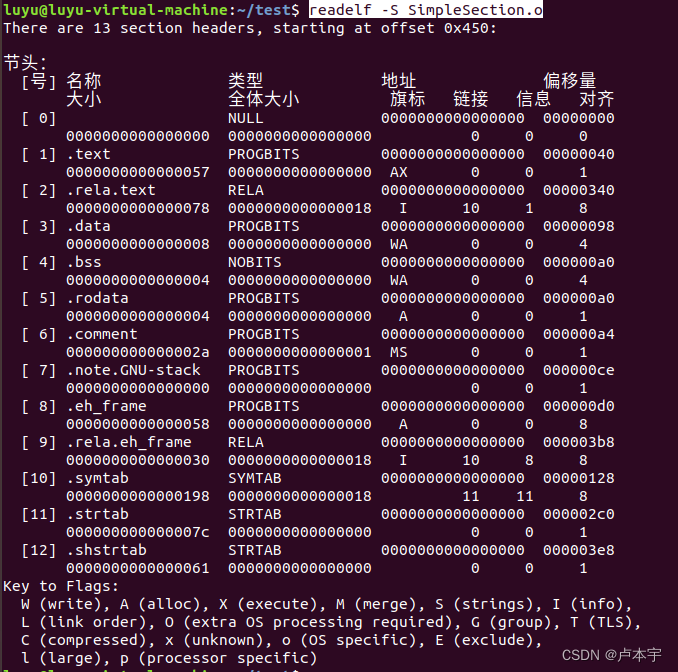
段表是一个数组,数组的元素是“Elf32_Shdr”的结构体,其被称为段描述符。
段表的第一个元素是无效的段描述符,它的类型为NULL。所以这个目标文件有11个有效的段。
以下为段描述符结构:
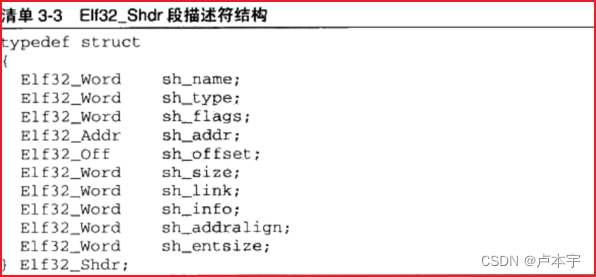
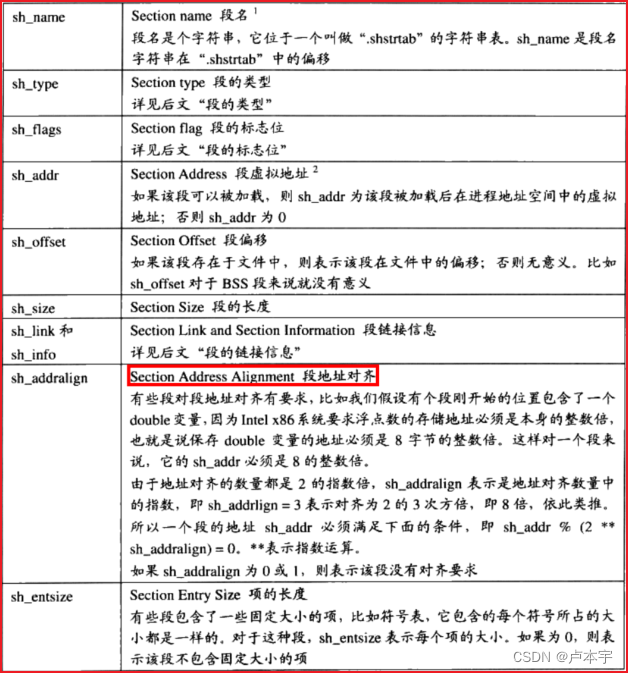
以下是各个段的结构:
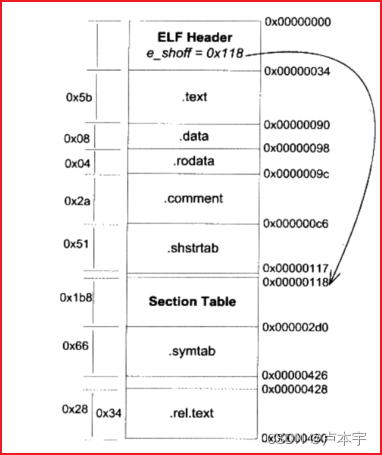
段的类型:决定段的属性的是段的类型与段的标志位
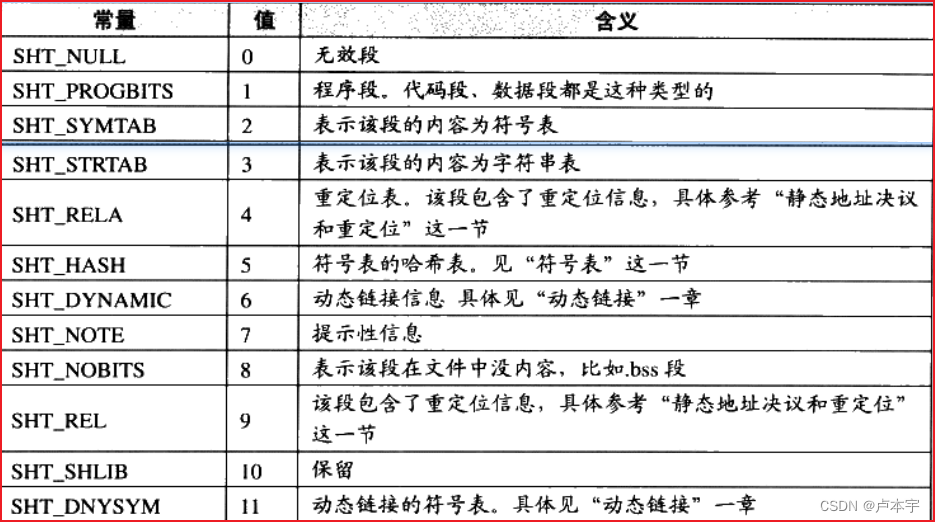
段的标志位:表示该段在进程虚拟地址空间中的属性,比如是否可写、可执行

系统保留段的属性:
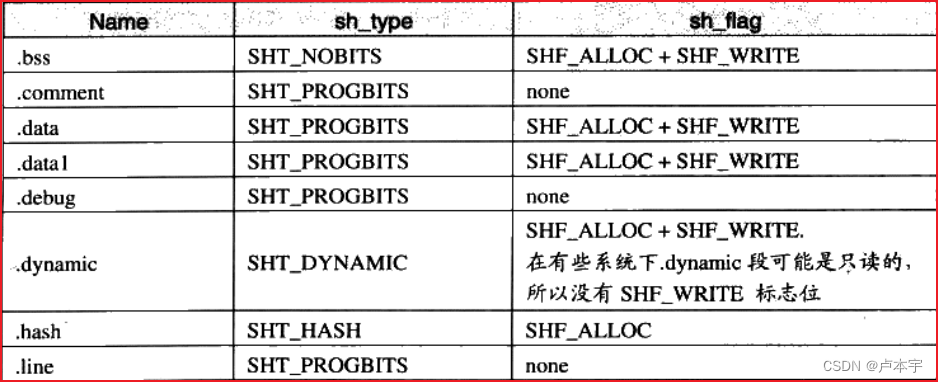
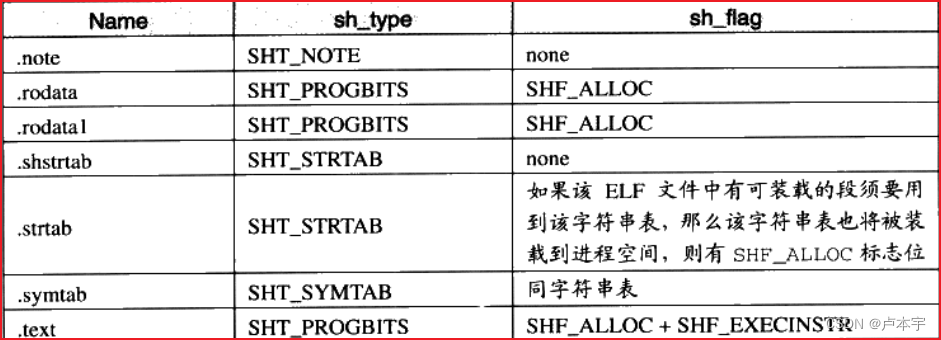
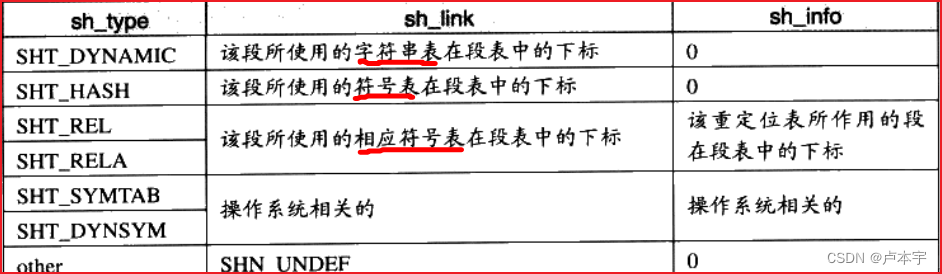
段的链接信息:段的类型如果与链接相关(不管是动态链接还是静态链接),比如重定位表,符号表等。么sh_link和sh_info这两个成员所包含的意义如下表所示:
4.3 重定位表
作用:记录需要进行重定位的符号在文件中的位置,以及其类型和重定位后的值
.rela.text的段,其段类型为REL,即重定位表。
作用:
链接器在处理目标文件时,需要对目标文件中某些部位进行重定位,即代码段和数据段中对绝对地址进行引用的位置。这些重定位信息就记录在重定位表里面。
对于每个需要进行重定位的代码段或者数据段都有一个对应的重定位表。比如".rela.text"就是针对".text"段的重定位表,因为".text"段有一个printf函数的调用。
".data"段没有对绝对地址的引用,只包含几个常量,所以,该目标文件中没有".data"段的重定位表。
一个重定位表同时是ELF文件的一个段,这个段的类型(sh_type)就是REL(重定位表类型),其”sh_link“表示符号表的下标,它的”sh_info“表示其作用于哪一段。即为那个段的在符号表中的下标。
4.4 字符串表
作用:ELF文件中用到很多字符串,比如段名,变量名等。其长度往往不定。于是常见做法就是将字符串集中起来存放到一个表中,然后根据字符串在表中偏移来引用字符串。
如下图是一个字符串表:

那么其对应的字符串如下所示:

常见的段名为".strtab"或".shstrtab",这两个字符串表分别为 字符串表和 段表字符串表,字符串表示保存普通的字符串,而段表字符串表则是用来保存段表中用到的字符串。
5 链接的接口-符号
链接的本质:把多个不同的文件之间相互粘到一起。为了使不同目标文件之间能够相互粘合,这些目标文件之间必须有固定的规则才行。
目标文件之间相互拼合实际上是目标文件之间对地址的引用,即对函数和变量的地址的引用。
举个例子:目标文件B要用到目标文件A中的函数“foo”,那么我们就称目标文件A定义了函数“foo”,称目标文件B引用了目标文件A中的函数“foo”。这两个概念也同样适用于变量,每个函数或变量都有自己独特的名字,才能避免连接过程中的混淆。我们将函数与变量统称为符号。函数名或者变量名被称为符号名。
因此,链接需要一个非常重要的段,那就是 符号表。
符号表:
符号表中记录了目标文件中所用到的所有符号,每个定义的符号都有一个对应的值,叫做“符号值”,对于函数与变量来说,这个符号值就是它们的地址。除了函数与变量之外,还有其他不常用的符号:
- 定义在本目标文件中的全局符号,可以被其他目标文件引用。比如SimpleSection.o里面的"func1"、"main"、"global_init_var"等;
- 本目标文件中引用的全局符号,却没有定义在本目标文件,这一般叫做外部符号,也就是我们前面所讲的符号引用。
- 段名,这种符号一般由编译器产生,它的值就是该段的起始地址
- 局部符号,这类符号只在编译单元内部可见。这些局部符号对连接过程没有作用
- 行号信息,即目标文件指令与源代码代码行的对应关系。
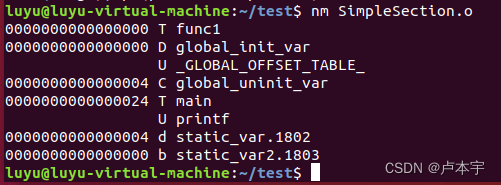
使用nm命令来查看目标文件的符号结果:
nm SimpleSection.o
5.1 ELF符号表结构
ELF文件中符号表为文件中的一个段,即“.symtab”。是一个Elf_Sym的数据结构。如下定义:


- 符号类型和绑定信息(st_info):
- 该成员的低四位表示符号的类型,高28位表示符号的绑定信息。如下表所示:
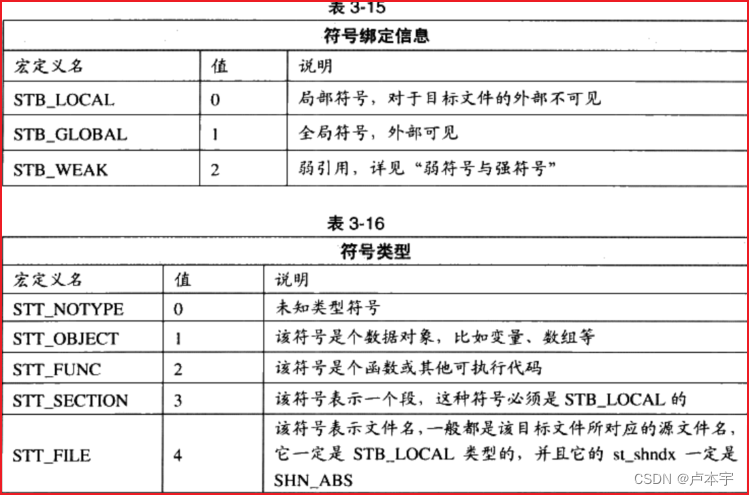
- 该成员的低四位表示符号的类型,高28位表示符号的绑定信息。如下表所示:
- 符号所在段(st_shndx):
- 如果符号定义在本目标文件中,那么这个成员表示符号所在的段在段表中的下标。如果不在本目标文件中,如下表所示:
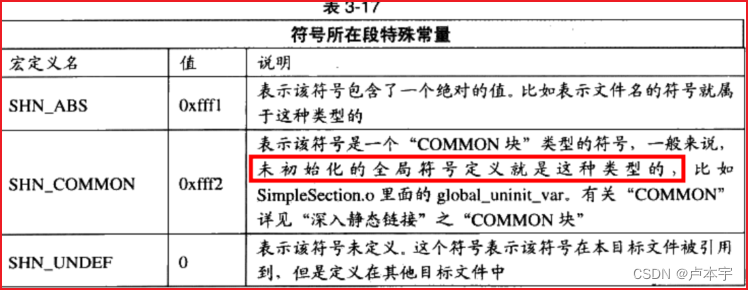
- 如果符号定义在本目标文件中,那么这个成员表示符号所在的段在段表中的下标。如果不在本目标文件中,如下表所示:
- 符号值(st_value):
- 如果符号是一个函数或者是一个变量,这个值就是函数或者变量的地址。
5.2 特殊符号
特殊符号:是我们使用链接器来生产可执行文件时,需要额外用到的特殊符号,其并没有在程序中定义。但是我们可以直接声明并且引用它,符号如下所示:
注意:仅有在使用ld链接生产最终可执行文件的时候这些符号才会存在
- __executable_start:该符号位程序的起始地址,注意不是入口地址,而是程序最开始的地址。
- __etext或 _etext或 etext:该符号位代码段结束地址,即代码段最末尾的地址。
- __edata或 edata:该符号位数据段结束地址,即数据段最末尾的地址。
- _end 或 end:该符号为程序结束地址。
- 以上地址都为程序被装载时的虚拟地址。
#include <stdio.h>extern char __executable_start[];extern char etext[];extern char edata[];extern char end[];int main(){ printf("executable_start : %X\n",__executable_start); printf("text end : %X\n", etext); printf("data end : %X\n", edata); printf("exectabel end : %X\n", end); return 0;}
经过编译链接后,执行,可以输出相关地址:

5.3 符号修饰与函数签名
问题:因为在源代码中,函数或者变量的名容易与库中的名产生冲突。
为了防止类似的符号名冲突,unix下的C语言规定,C语言源代码文件中的所有全局的变量和函数经过编译之后,相对应的符号名前面加上下划线“_”
C++则采用了 命名空间的技术 解决该问题
C++符号修饰
因为C++有类、继承、重载等机制使得其符号管理更为复杂。
因此,研究者发明了 符号修饰 或 符号改编 的机制。
举例:
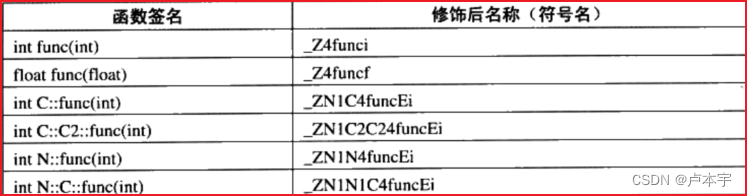
int func(int);float func(float);class C{ int func(int); class C2{ int func(int); };};namespace N{ int func(int); class C{ int func(int); };}
这段代码中有6个同名函数叫 func,只不过其 返回类型、参数、命名空间 不同。因此,C++引入了 函数签名:
- 函数签名 包含了一个函数的信息:包括函数名、参数类型、它所在的类和命名空间及其他信息。
- 函数签名 用于识别不同的函数,就像签名识别不同的人一样。
相应修饰后名称如下:
5.4 extern "C"
问题:因为C++与C语言的符号管理上,有着一定的区别。C++为了和C兼容,需要一定的手段,这个就是extern “C”
作用:C++编译器将在extern “C”的大括号内部的代码当做C语言的代码惊喜处理
用来处理C++与C语言不同符号修饰手段
#ifdef __cplusplusextern "C"{#endifvoid *memset(void *,int ,size_t);#ifdef __cplusplus}#endif
如果当前编译的是c++语句,那么memset会在extern “C”里面声明,如果是C语言就直接声明。
5.5 弱符号与强符号
问题:编程的时候,多个目标文件中含有相同名字全局符号定义,那么目标文件链接的时候会出现符号重复定义的错误。
如下,如果目标文件A与目标文件B都定义一个全局整型变量global,并将其都初始化,那么链接器将A与B连接时会报错

强符号:上面这符号就被称为 强符号。编译器默认函数和初始化了的全局变量为强符号。
弱符号:有些符号就可以成为 弱符号。未初始化的全局变量为弱符号。
自己定义强符号或者弱符号:
- GCC定义强符号为弱符号:
- extern int ext;int weak;int strong = 1;__attribute__((weak)) weak2 = 2;int main(){ return 0;}
- 上面 weak ,weak2 是弱符号,strong 和 main 是强符号,而 ext 既非强符号也非弱符号,因为它是一个外部变量的引用。
链接器会按照下面规则处理多次定义的全局符号:
- 不允许强符号被多次定义,重复定义会报错
- 如果一个符号在某个文件中是强符号,另外的文件中是弱符号,那么选择强符号
- 如果都是弱符号,选择占用空间最大的那个
5.6 弱引用与强引用
6. 调试信息
目标文件中还有可能保存调试信息。如果我们在gcc编译时加上-g参数,编译器会在生成的目标文件中加上调试信息。我们可以通过readelf工具看到,目标文件中多个很多debug的段。
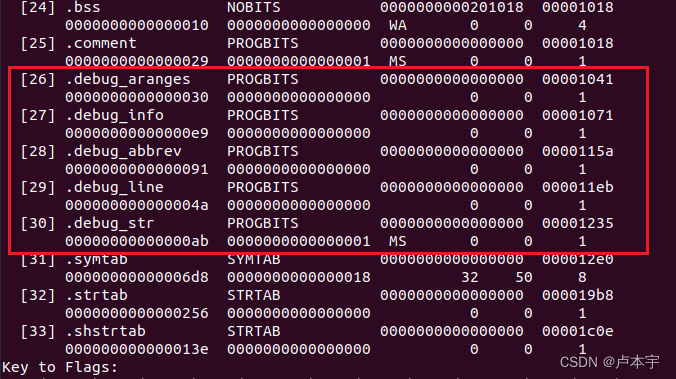
我们可以使用 strip 命令去掉文件中的调试信息
strip foo
附录1.objdump的使用
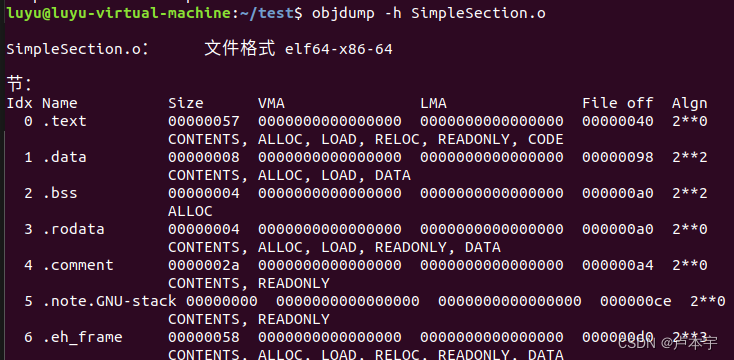
- 直接通过 -h 或者 -x查看目标文件内部的结构:
- objdump -h xxx.o
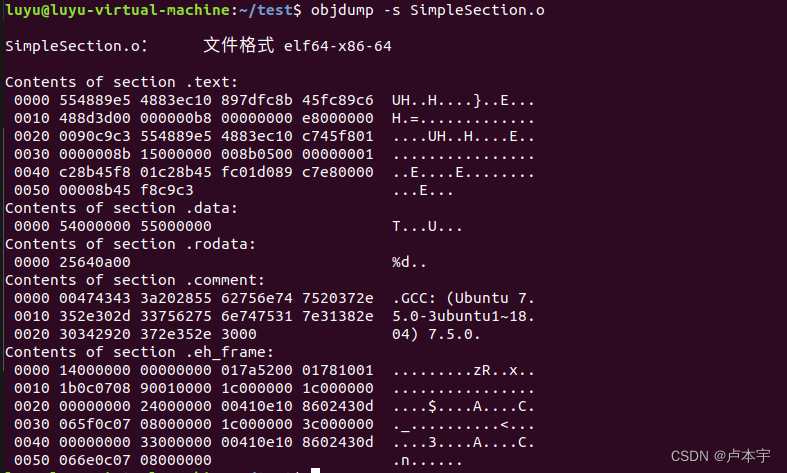
- 通过“-s”参数将所有段的内容以十六进制方式打印。
- objdump -s xxx.o
- 通过“-d”参数可以将包含指令的段反汇编。
- objdump -d SimpleSection.o
附录2.readelf的使用
- 通过“-h”参数查看ELF文件具体文件头信息
- readelf -h xxx.o

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









