







使用Scrapy 提取器
设置好规则
rules = (
Rule(LinkExtractor(allow=r'type=4&page=\d+'), callback="parse_pages", follow=True)
)
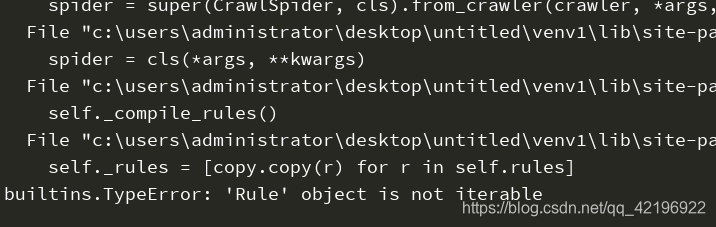
报了一个的错误,源码来看是要求为可迭代对象,加个逗号就行,
Rule(LinkExtractor(allow='page='),callback='parse_item',follow=False),
******************************************************************************************************
修改一下, 看了下源码,该rules需要可迭代对象, 故此处可以为元组或者列表也行

















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









