







DeblurGAN:Blind Motion Deblurring Using Conditional Adversarial Networks
Paper:http://openaccess.thecvf.com/content_cvpr_2018/papers/Kupyn_DeblurGAN_Blind_Motion_CVPR_2018_paper.pdf
Code:https://github.com/KupynOrest/DeblurGAN
Tips:CVPR2018的一篇paper。
(阅读笔记)
1.Main idea
- 提出了端到端解决运动模糊的一个方法。
- 真实图像的去模糊效果也很好。
- 提出了一个数据集增强的方法。
2.Intro
- 提出的方法速度快,效果好。we propose a loss and architecture which obtain state-of-the art results in motion deblurring.
- 提出了数据增强的方法。we present a method based on random trajectories for generating a dataset for motion deblurring training in an automated fashion from the set of sharp image.
- 提出了通过目标检测的方法来评估去模糊的方法。we present a novel dataset and method for evaluation of deblurring algorithms based on how they improve object detection results.
- 模糊的数学模型,其中
I
B
I_B
IB是模糊图像,
k
(
M
)
k(M)
k(M)是未知的模糊核,
I
S
I_S
IS是清晰的图像,
N
N
N是加性噪声:
I B = k ( M ) × I S + N (1) \begin{aligned} I_B=k(M)\times I_S+N \tag{1} \end{aligned} IB=k(M)×IS+N(1) - 早期都是非盲去模糊,假设 k ( M ) k(M) k(M)已知的。但是实际中却是未知的,需要同时估计模糊核和清晰图像。同时有考虑模糊是均与的,不够充分;有迭代的方式的,但是迭代次数未知,也浪费时间。近年来也有很多深度学习的方法。
- GAN给予一定约束,就变成了条件GAN。
3.Details
-
损失函数由两部分组成;对抗损失(采用WGAN-GP)和内容损失(Perceptual loss,并没有用常规的均方差或绝对值);Perceptual loss就是提前预训练了一个网络以便更好的提取特征,损失就是真实图像 I S I_S IS和生成器生成的图像 G θ G ( I B ) ) G_{\theta_{G}}(I_B)) GθG(IB))送入网络 ϕ \phi ϕ和进行差距比较的,论文用的是VGG。based on the difference of the generated and target image CNN feature maps.
生成器的损失函数如下所示:
L = L G A N + λ L X (2) \mathcal{L} = \mathcal{L}_{GAN}+ \lambda \mathcal{L}_{X} \tag{2} L=LGAN+λLX(2)
L G A N = ∑ n = 1 N − D θ D ( G θ G ( I B ) ) (3) \mathcal{L}_{GAN} =\sum_{n=1}^N -D_{\theta_{D}} (G_{\theta_{G}}(I_B)) \tag{3} LGAN=n=1∑N−DθD(GθG(IB))(3)
L X = 1 W i , j H i , j ∑ x = 1 W i , j ∑ y = 1 H i , j ( ϕ i , j ( I S ) x , y − ϕ i , j ( G θ G ( I B ) ) x , y ) 2 (4) \mathcal{L}_{X} = \frac{1}{W_{i,j}H_{i,j}} \sum_{x=1}^{W_{i,j}} \sum_{y=1}^{H_{i,j}} (\phi_{i,j}(I_S)_{x,y}- \phi_{i,j}(G_{\theta_{G}}(I_B))_{x,y})^2 \tag{4} LX=Wi,jHi,j1x=1∑Wi,jy=1∑Hi,j(ϕi,j(IS)x,y−ϕi,j(GθG(IB))x,y)2(4)
很容易理解,条件GAN都类似的,并不是和原始的分布去比较,而是找到一个对应的分布(去噪,图像转换等等),如上述即很简单地用到了均方差来作损失。而判别器的训练和WGAN-GP一样。
其中The architecture of critic network is identical to PatchGAN. -
训练过程如下所示。很明显地,生成器输入模糊图像,要求输出恢复图像;判别器用来评价好坏,条件GAN的充分体现。在测试的时候,仅需要生成器即可。
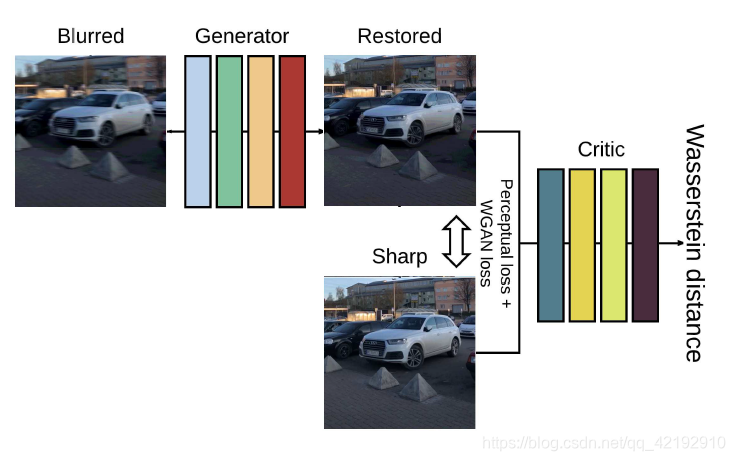
-
运动模糊生成。先随机轨迹生成,然后模糊核就根据该轨迹向量对像素处理。

















 3193
3193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









