






一、什么功能需要做性能测试?
1、高并发场景功能需求
1.瞬时流量洪峰
-
典型功能:
-
电商秒杀(如限量商品抢购)
-
票务系统开票(演唱会、车票)
-
-
性能指标:
-
TPS(每秒事务数) ≥5000
-
请求成功率 ≥99.99%
-
网络带宽峰值 ≤80%(避免丢包)
-
-
测试策略:
# 使用JMeter模拟100万用户瞬时涌入 jmeter -n -t spike_test.jmx -Jusers=1000000 -Jrampup=1 -
常见瓶颈:
-
Redis缓存击穿 → 解决方案:布隆过滤器 + 热点Key本地缓存
-
数据库连接池耗尽 → 解决方案:HikariCP动态扩容
-
2、业务逻辑/复杂计算型功能需求
此处列举复杂的业务逻辑的功能接口
3、系统核心模块/系统
此处列举系统核心模块
4、新系统/新项目
5、线上性能问题验证和优化
1. 瓶颈定位流程
-
步骤:
-
监控分析:通过APM工具(如SkyWalking)定位慢请求
-
日志排查:分析GC日志、慢查询日志
-
压测复现:测试环境使用Jmeter压测复现
-
6、新技术选型
-
测试场景:
-
数据库升级(MySQL 5 vs MySQL 8的读写入性能对比)
-
消息队列对比(Kafka vs RocketMQ的吞吐量测试)
-
底层技术架构变化大
-
7、日常系统性能回归
自动化流水线集成
-
CI/CD集成:搭建Jmeter+IndexDB+grafana自动化压测
二、性能测试指标
1、业务层性能指标
1.1 事务处理能力
| 指标 | 定义 | 示例场景 | 优化方向 |
|---|---|---|---|
| TPS | 每秒完成的事务数(Transactions Per Second) | 支付系统处理交易能力 | 优化代码逻辑、减少数据库锁竞争 |
| RPS | 每秒请求数(Requests Per Second) | API网关吞吐量测试 | 增加服务器节点、启用HTTP/2 |
| 成功率 | 成功请求数 / 总请求数 ×100% | 验证接口容错能力 | 完善重试机制、熔断策略 |
1.2 响应时间
| 指标 | 定义 | 业务意义 |
|---|---|---|
| 平均响应时间 | 所有请求的平均处理时间 | 用户体验基线参考 |
| P90/P99 | 90%/99%请求的响应时间 ≤X ms | SLA达标依据(如金融交易系统要求P99≤50ms) |
| 最大响应时间 | 最慢请求的耗时 | 发现极端异常场景 |

2、系统资源指标
2.1 CPU
| 指标 | 正常范围 | 异常表现 | 排查命令 |
|---|---|---|---|
| 用户态CPU(us%) | <80% | 代码计算密集型任务过多 | top -H -p <PID> |
| 系统态CPU(sy%) | <20% | 频繁系统调用(如IO等待) | pidstat -t 1 |
| IO等待(wa%) | <5% | 磁盘或网络IO瓶颈 | iostat -x 1 |
2. 2内存
| 指标 | 关注点 | 工具示例 |
|---|---|---|
| 内存使用率 | 避免OOM(Out Of Memory) | free -m |
| 堆内存(JVM) | Young GC频率、Old区增长趋势 | jstat -gcutil <PID> 1000 |
| 内存泄漏 | 长时间运行后内存未释放 | jmap -histo:live <PID> |
2.3 磁盘
| 指标 | 定义 | 临界值 | 测试工具 |
|---|---|---|---|
| IOPS | 每秒输入输出操作数 | SSD:≥5000 | fio --rw=randwrite --bs=4k |
| 吞吐量 | 每秒读写数据量(MB/s) | 千兆网:≥100 | dd if=/dev/zero of=testfile bs=1G count=1 |
| 磁盘利用率 | %util(iostat输出) | >70%为瓶颈 | iostat -x 1 |
2.4 网络
| 指标 | 定义 | 排查命令 |
|---|---|---|
| 带宽使用率 | 当前流量占理论最大带宽的百分比 | nload eth0 |
| TCP重传率 | 网络质量指标(正常<1%) | sar -n ETCP 1 |
| 连接数 | ESTABLISHED状态连接数 | ss -s 或 netstat -ant |
3、中间件性能指标
3.1 数据库(MySQL为例)
| 指标 | 定义 | 优化建议 |
|---|---|---|
| QPS | 每秒查询次数 | 添加缓存、优化慢SQL |
| 活跃连接数 | Threads_connected | 调整连接池大小 |
| 锁等待时间 | Innodb_row_lock_time_avg | 减少事务粒度、使用乐观锁 |
3.2 缓存(Redis为例)
| 指标 | 定义 | 告警阈值 |
|---|---|---|
| 缓存命中率 | keyspace_hits / (keyspace_hits + keyspace_misses) | <90%需优化缓存策略 |
| 内存碎片率 | used_memory_rss / used_memory | >1.5 需执行MEMORY PURGE |
| 网络延迟 | 客户端到Redis的往返延迟 | P99 >10ms |
3.3 消息队列(Kafka为例)
| 指标 | 定义 | 测试工具 |
|---|---|---|
| 生产吞吐量 | 消息写入速率(MB/s) | kafka-producer-perf-test |
| 消费延迟 | 消息生产到消费的时间差 | 客户端埋点 + Prometheus |
| 积压消息数 | 未消费的消息数量 | kafka-consumer-groups |
4、云原生环境指标
4.1 Kubernetes集群
| 指标 | 定义 | 监控工具 |
|---|---|---|
| Pod重启次数 | 容器异常重启频率 | kubectl top pod |
| HPA弹性效率 | 扩容到目标副本数所需时间 | 自定义Prometheus指标 |
| 节点资源分配率 | 已分配CPU/内存占集群总量的比例 | Grafana + Node Exporter |
4.2 服务网格(Istio)
| 指标 | 定义 | 意义 |
|---|---|---|
| Sidecar注入延迟 | 请求经过Envoy代理增加的延迟 | 评估Service Mesh性能损耗 |
| 熔断触发次数 | 单位时间内断路器的打开次数 | 验证服务容错能力 |
5、TPS、响应时间和并发数的关系
一、TPS、响应时间与并发数的关系
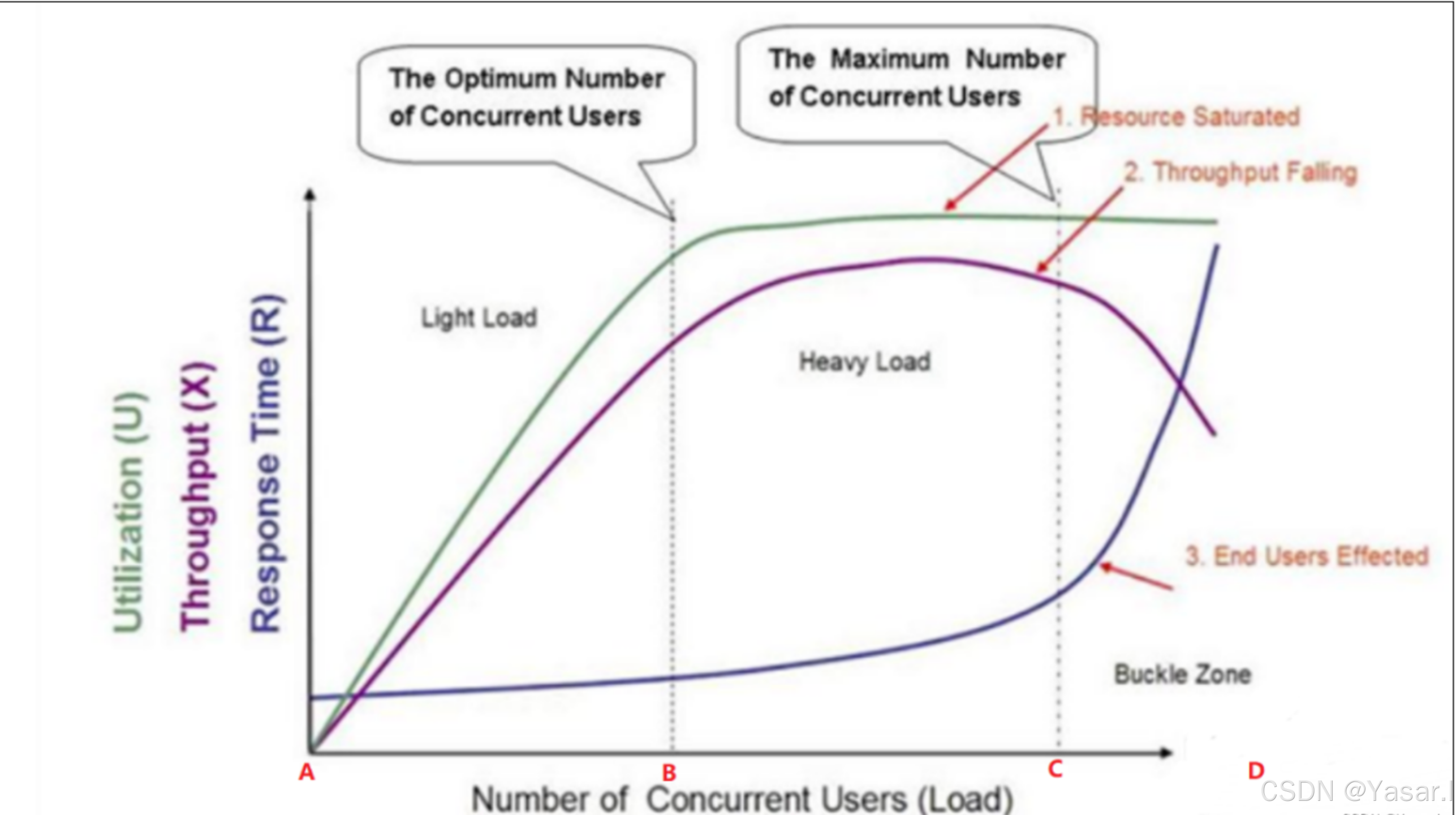
1. 三条核心曲线
| 曲线 | 特征 | 关联关系 |
|---|---|---|
| 吞吐量(TPS) | 紫色曲线,随并发数增加先上升后下降 | - 轻负载区:TPS随并发数线性增长 - 重负载区:TPS增速放缓 - 塌陷区:TPS骤降 |
| 资源利用率 | 绿色曲线,随并发数增加持续上升 | - 资源利用率与系统负载正相关 - 接近100%时系统进入瓶颈 |
| 响应时间 | 深蓝色曲线,初期稳定,重负载区后陡升 | - 轻负载区:响应时间平稳 - 重负载区:响应时间指数级增长 |
2. 三个关键区域
| 区域 | 特征 | 系统状态 |
|---|---|---|
| 轻负载区 | 并发数 < 最优并发用户数(A-B段) | - 资源利用率低(<70%) - 响应时间稳定 - TPS线性增长 |
| 重负载区 | 最优并发用户数 < 并发数 < 最大并发用户数(B-C段) | - 资源饱和(CPU/内存/IO ≥80%) - 响应时间开始上升 - TPS增速趋缓 |
| 塌陷区 | 并发数 > 最大并发用户数(C-D段) | - 资源耗尽(连接池满、线程阻塞) - TPS断崖式下跌 - 响应时间超时或失败 |
3. 两个核心临界点
| 临界点 | 定义 | 业务意义 |
|---|---|---|
| 最优并发用户数 | TPS达到峰值时的并发数(B点) | 系统最佳性能状态,建议生产环境运行在此点前 |
| 最大并发用户数 | TPS开始下降的临界点(C点) | 系统崩溃前的极限值,需通过压测确定并设置保护阈值 |
4. 三个状态描述
| 状态 | 对应阶段 | 表现与影响 |
|---|---|---|
| 资源饱和 | 重负载区中段 | CPU/内存/IO接近100%,响应时间波动,需扩容或优化 |
| 吞吐下降 | 塌陷区起始段 | TPS下降,错误率上升,系统部分功能不可用 |
| 用户受影响 | 塌陷区中后段 | 大量请求超时,用户体验急剧恶化 |
二、压力测试策略
1. 压力测试核心目标
| 测试类型 | 测试场景 | 验证目标 |
|---|---|---|
| 稳定性压力测试 | 接近最大并发用户数(C点),持续运行24小时 | 验证系统在高负载下的长期稳定性,检测内存泄漏、线程池泄露等问题 |
| 破坏性压力测试 | 超过最大并发用户数(C-D段),模拟极端负载 | 验证熔断降级、限流策略的有效性,测试故障恢复能力(如自动重启、数据一致性恢复) |
2. 测试执行策略
| 阶段 | 操作要点 | 关键指标监控 |
|---|---|---|
| 稳定性测试 | - 梯度增压至90%最大负载 - 长时间稳定运行 | - TPS波动 ≤±5% - 内存泄漏 ≤1MB/小时 - 错误率 <0.1% |
| 破坏性测试 | - 瞬时冲击至120%最大负载 - 模拟部分节点宕机 | - 熔断触发延迟 ≤1秒 - 故障恢复时间 ≤5分钟 - 数据不一致率 <0.01% |
三、性能测试流程
1. 性能测试需求分析
-
熟悉被测系统
-
业务功能:梳理核心业务流程(如订单创建、支付)与数据流向(用户→服务→数据库)。
-
技术架构:明确系统架构(单体/微服务)、中间件(Redis/Kafka)、数据库分片策略。
-
-
明确测试范围
-
业务角度:高频业务(如登录、查询)、生产环境高访问量功能。
-
技术角度:复杂逻辑模块(如风控计算)、大数据量场景(如报表生成)。
-
-
配置信息确认
-
测试环境硬件:CPU核数、内存容量、磁盘类型(SSD/HDD)。
-
生产与测试差异:如测试环境资源为生产的50%,需在报告中说明影响。
-
-
测试策略选择
-
基准测试(单接口性能摸底)。
-
单交易负载测试(纯下单场景)。
-
混合场景测试(模拟真实用户行为比例)。
-
高可用性测试(节点宕机、网络分区)。
-
异常场景测试(第三方服务超时)。
-
稳定性测试(7×24小时运行)。
-
-
性能测试指标
-
有需求时:按需求定义(如并发20用户,响应时间≤3秒,成功率100%)。
-
无需求时:参考行业数据或历史运营数据估算(如日活用户×10%作为并发基准)。
-
-
明确上线时间
-
制定排期表,确保测试与开发、上线计划衔接。
-
2. 性能测试计划及方案
方案内容模板
-
项目背景:简述系统业务目标。
-
测试目的:验证高并发下的处理能力、稳定性。
-
测试范围:明确测试接口(如支付接口)与排除项。
-
测试策略:基准测试+混合场景测试+异常测试。
-
风险控制:数据隔离方案(影子库)。
-
环境信息:压测环境与生产环境的资源配置对比(表格或文字描述)。
-
进度分工:按角色(测试/DBA/运维)分配任务与时间节点。
3. 性能测试用例
| 项目 | 内容 |
|---|---|
| 用例编号 | Perf_Login_001 |
| 用例名称 | 模拟高并发用户登录 |
| 测试类型 | 负载测试 |
| 场景描述 | 模拟1000个用户并发登录系统,验证登录接口性能 |
| 输入数据 | - 用户池:10万个测试用户(用户名+密码) - 验证码:固定值(1234) |
| 预期结果 | - TPS ≥500 - 响应时间P99 ≤1秒 - 登录成功率 ≥99.9% |
| 测试步骤 | 1. 准备测试数据 2. 编写JMeter脚本 3. 梯度增压执行(100→1000并发) |
| 监控指标 | - CPU ≤80% - 内存 ≤70% - 数据库连接数 ≤80% |
4. 搭建测试环境
-
核心要求
-
硬件对齐:CPU型号、内存、磁盘类型与生产一致。
-
版本一致:操作系统、中间件(Nginx/Redis)、数据库版本匹配。
-
5. 测试数据准备
-
数据生成方法
-
接口调用:JMeter模拟用户操作生成数据。
-
数据库脚本:存储过程快速插入百万级数据。
-
Python脚本:使用脚本造数,可以使用python/java等语言,编写造数脚本。
-
import pymysql
class MysqlUtil:
# 初始化
__conn = None
__cursor = None
# 创建连接
@classmethod
def __get_conn(cls):
if cls.__conn is None:
cls.__conn = pymysql.connect(host="数据库",
port=端口,
user="用户名",
password="密码",
database="数据库")
return cls.__conn
# 获取游标
@classmethod
def __get_cursor(cls):
if cls.__cursor is None:
cls.__cursor = cls.__get_conn().cursor()
return cls.__cursor
# 执行sql
@classmethod
def exe_sql(cls, sql):
try:
# 获取游标对象
cursor = cls.__get_cursor()
# 调用游标对象的execute方法,执行sql
cursor.execute(sql)
# 如果是查询
if sql.split()[0].lower() == "select":
# 返回所有数据
return cursor.fetchall()
# 否则:
else:
# 提交事务
cls.__conn.commit()
# 返回受影响的行数
return cursor.rowcount
except Exception as e:
# 事务回滚
cls.__conn.rollback()
# 打印异常信息
print(e)
finally:
# 关闭游标
cls.__close_cursor()
# 关闭连接
cls.__close_conn()
# 关闭游标
@classmethod
def __close_cursor(cls):
if cls.__cursor:
cls.__cursor.close()
cls.__cursor = None
# 关闭连接
@classmethod
def __close_conn(cls):
if cls.__conn:
cls.__conn.close()
cls.__conn = None封装后,只需要引用上封装好的包,编辑SQL即可;
from tools.mysql_util import MysqlUtil
a=MysqlUtil.exe_sql("select * from tb_board")
print(a)6. 测试脚本编写
-
关键步骤
-
工具选择:JMeter(HTTP)、Locust(自定义逻辑)。
-
协议选择:HTTP/WebSocket/TCP。
-
参数化:CSV文件动态替换用户ID、Token。
-
关联处理:正则提取器获取动态SessionID。
-
检查点:断言响应状态码(200)和业务数据(如订单号非空)。
-
7. 执行测试脚本
-
执行流程
-
调试脚本:单用户验证逻辑正确性。
-
场景配置:梯度增压(10→1000并发),混合场景(70%查询+30%下单)。
-
正式执行:分布式压测,记录日志与监控数据。
-
8. 性能测试监控
-
监控指标
-
系统资源:CPU、内存、磁盘IO(工具:Node Exporter + Grafana)。
-
中间件:Redis连接数、MySQL慢查询(工具:Redis CLI、SHOW PROCESSLIST)。
-
应用层:JVM GC频率、HTTP延迟(工具:SkyWalking、Arthas)。
-
9. 性能分析与调优
-
调优优先级
-
硬件/网络:扩容服务器、升级带宽。
-
配置优化:调整数据库连接池、JVM参数(-Xmx)。
-
代码/SQL优化:消除慢查询、添加索引。
-
架构改造:引入缓存、分库分表、异步化(消息队列)。
-
10. 性能测试回归
-
回归策略
-
自动化验证:集成到CI/CD流水线,对比历史数据。
-
指标对比:TPS波动≤5%,平均响应时间波动≤10%。
-
11. 性能测试报告总结
-
报告内容
-
概述:测试目标、时间范围。
-
测试环境:生产与测试资源配置对比。
-
结果与分析:TPS、响应时间、瓶颈问题(如数据库锁竞争)。
-
调优说明:优化措施(如添加索引)与效果对比(TPS提升85%)。
-
结论与建议:系统能力评估(如支持1500 TPS),长期改进建议(如分库分表)。
-
四、Jmeter压测工具介绍
1、安装
2、线程组
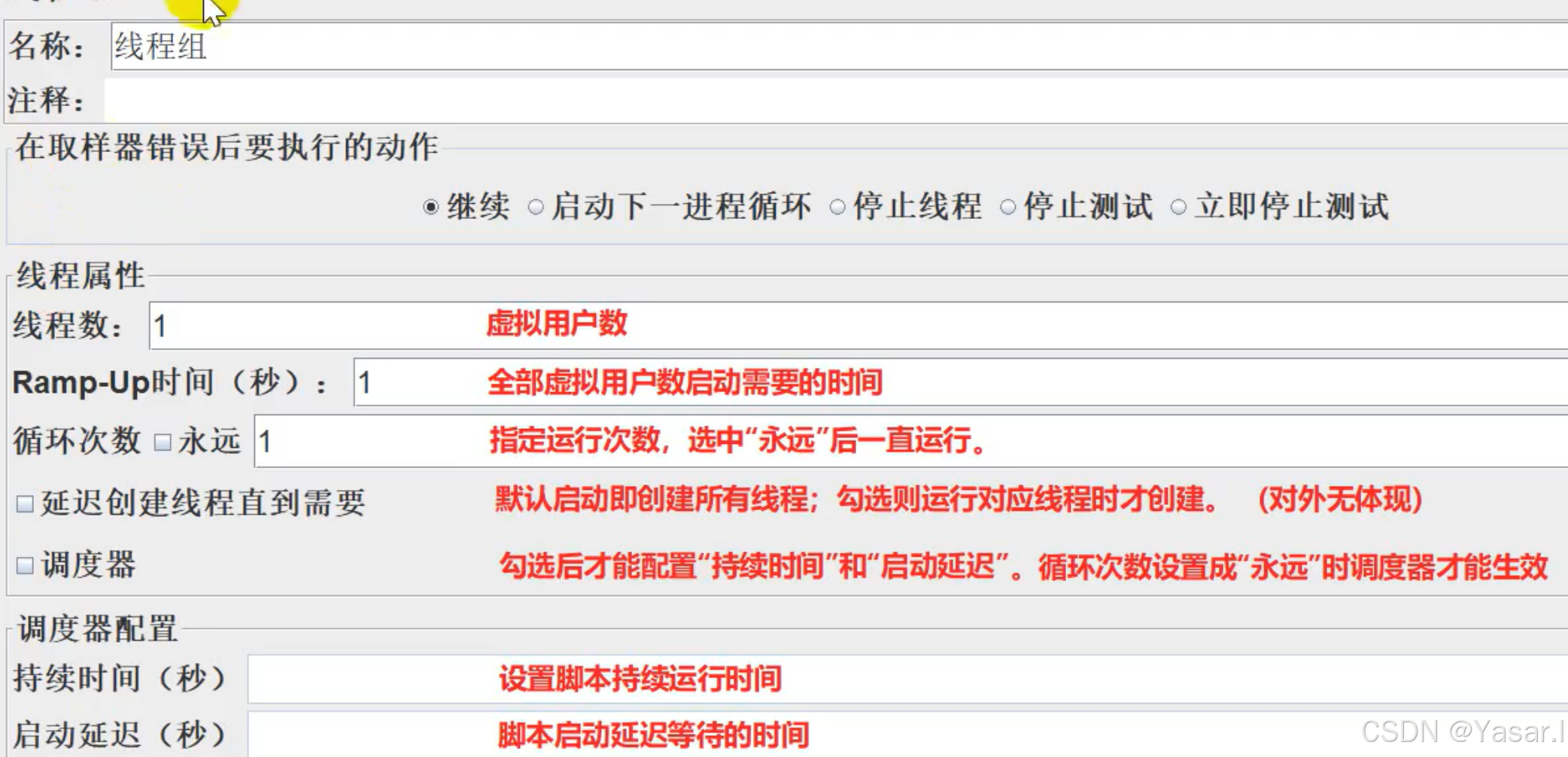
2.1 线程组类型与作用
| 线程组类型 | 执行阶段 | 用途 |
|---|---|---|
| setUp 线程组 | 测试前执行 | - 预测试操作(如数据初始化、启动服务器监控<EasyNMon监控>) - 示例:调用接口生成测试数据 |
| 线程组 | 测试中执行 | - 核心测试逻辑(模拟用户并发操作) - 示例:模拟用户登录、下单 |
| tearDown 线程组 | 测试后执行 | - 后置清理(如删除测试数据、停止监控) - 示例:清理数据库临时数据 |
执行顺序
setUp线程组 → 线程组 → tearDown线程组
2.2 线程组核心属性
2.1 基础配置
| 参数 | 说明 | 示例值 |
|---|---|---|
| 线程数(Number of Threads) | 并发用户数(虚拟用户数) | 100 |
| Ramp-Up时间(Ramp-Up Period) | 启动所有线程的时间(秒) (如100用户设置10秒 → 每秒启动10用户) | 10 |
| 循环次数(Loop Count) | 循环次数(每个用户的请求次数)永远(Forever) 表示无限循环 | 1 |

2.2 调度器配置(勾选 Scheduler 后生效)
| 参数 | 说明 |
|---|---|
| 持续时间(Duration) | 测试持续时间(秒) |
| 启动延迟(Startup Delay) | 延迟启动时间(秒) |

2.3 取样器错误处理策略
| 选项 | 行为说明 |
|---|---|
| 继续(Continue) | 忽略错误,继续执行后续请求(默认选项) |
| 启动下一进程循环(Start Next Loop) | 跳过当前循环剩余步骤,直接开始下一次循环 |
| 停止线程(Stop Thread) | 停止当前线程(其他线程继续运行) |
| 停止测试(Stop Test) | 等待当前所有线程执行完毕后,停止整个测试 |
| 立即停止测试(Stop Test Now) | 立即终止整个测试(强制停止所有线程) |

2.4 高级配置
| 参数 | 说明 |
|---|---|
| 延迟创建线程直到需要(Delay Thread Creation) | 延迟创建线程(按需分配资源,适合大并发场景) |
| Same User on Each Iteration | 每次迭代使用同一用户(适用于需要保持会话的场景) |

3、HTTP请求元件
3.1 添加 HTTP 请求
路径:

右键线程组 → 添加(Add)→ 取样器(Sampler)→ HTTP 请求
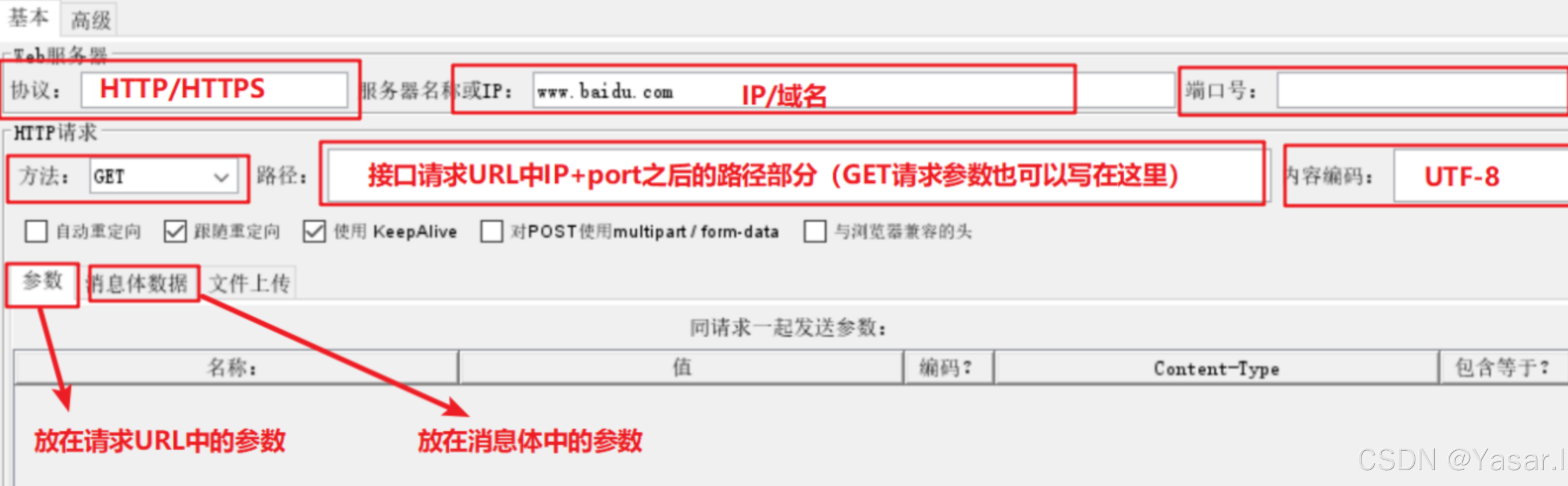
3.2 GET 请求配置
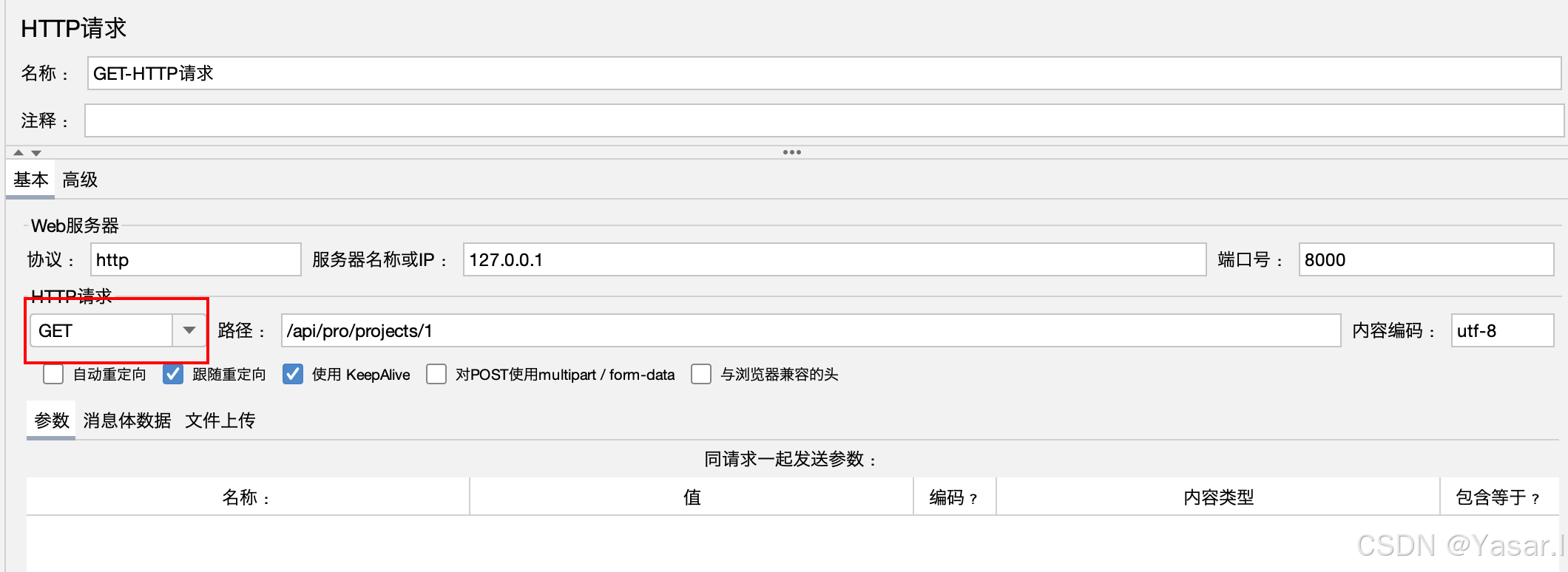
-
基础参数:
-
协议:
http或https -
服务器名称/IP:目标地址(如
127.0.0.1) -
路径:接口路径(如
/api/pro/projects) -
请求方法:
GET
-
-
参数传递:
-
参数(Parameters):
可以直接放路径上
-
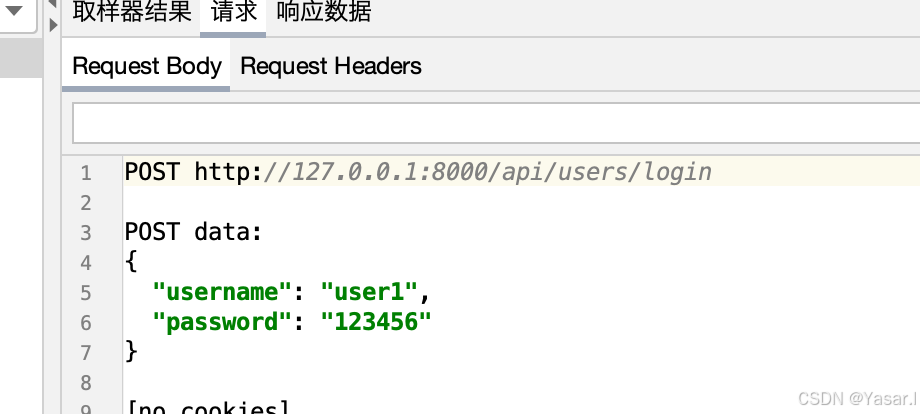
3.3 POST 请求(JSON 格式)
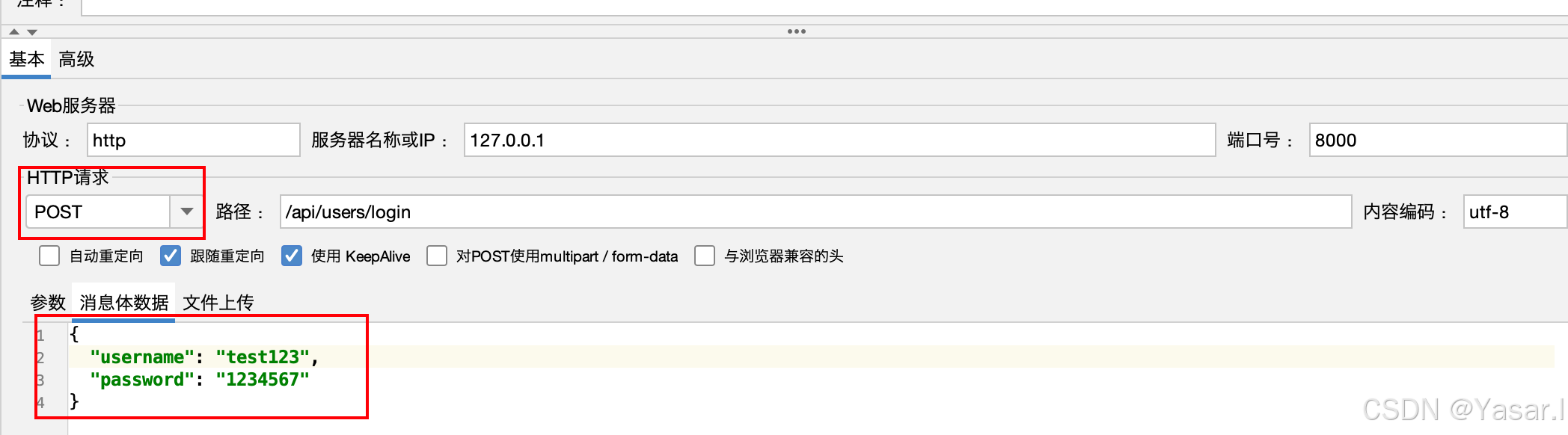
-
基础参数:
-
请求方法:
POST -
路径:如
/login
-
-
请求头设置:
右键 HTTP 请求 → 添加 → 配置元件 → HTTP 信息头管理器
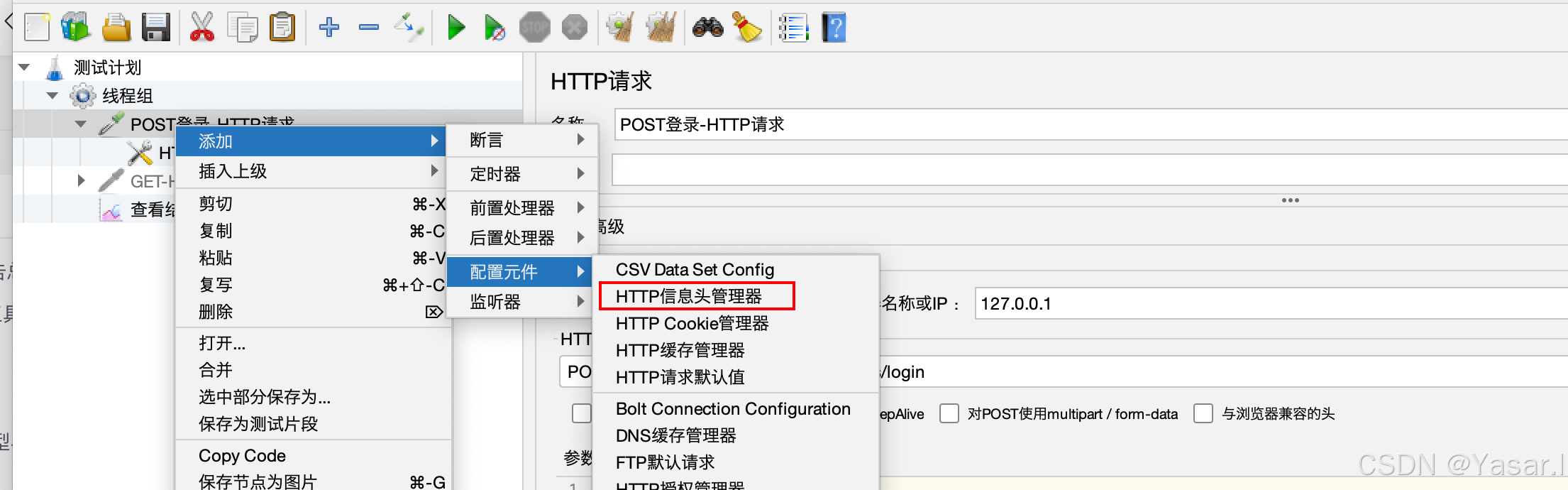

| 名称 | 值 |
|---|---|
Content-Type | application/json |
-
请求体(Body Data):
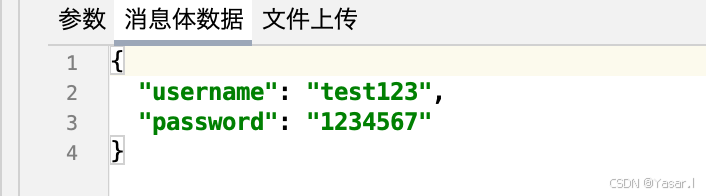
{ "username": "admin", "password": "123456" }
3.4 POST 请求(表单格式)
3.4.1 multipart/form-data(文件上传)
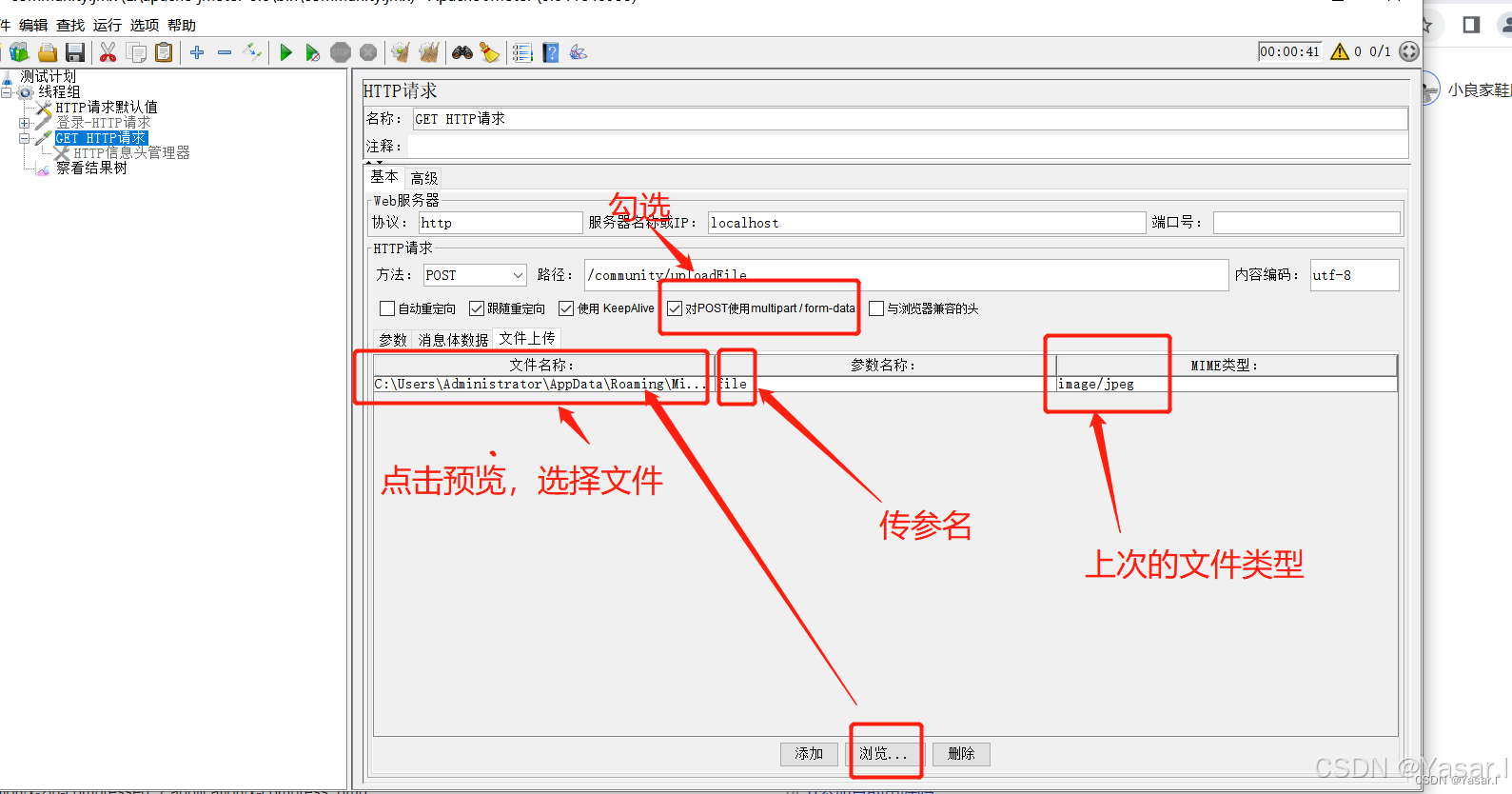
-
请求方法:
POST -
参数传递:
-
参数(Parameters):
名称 值 MIME 类型 file文件路径 application/octet-stream
-
3.5 查看结果
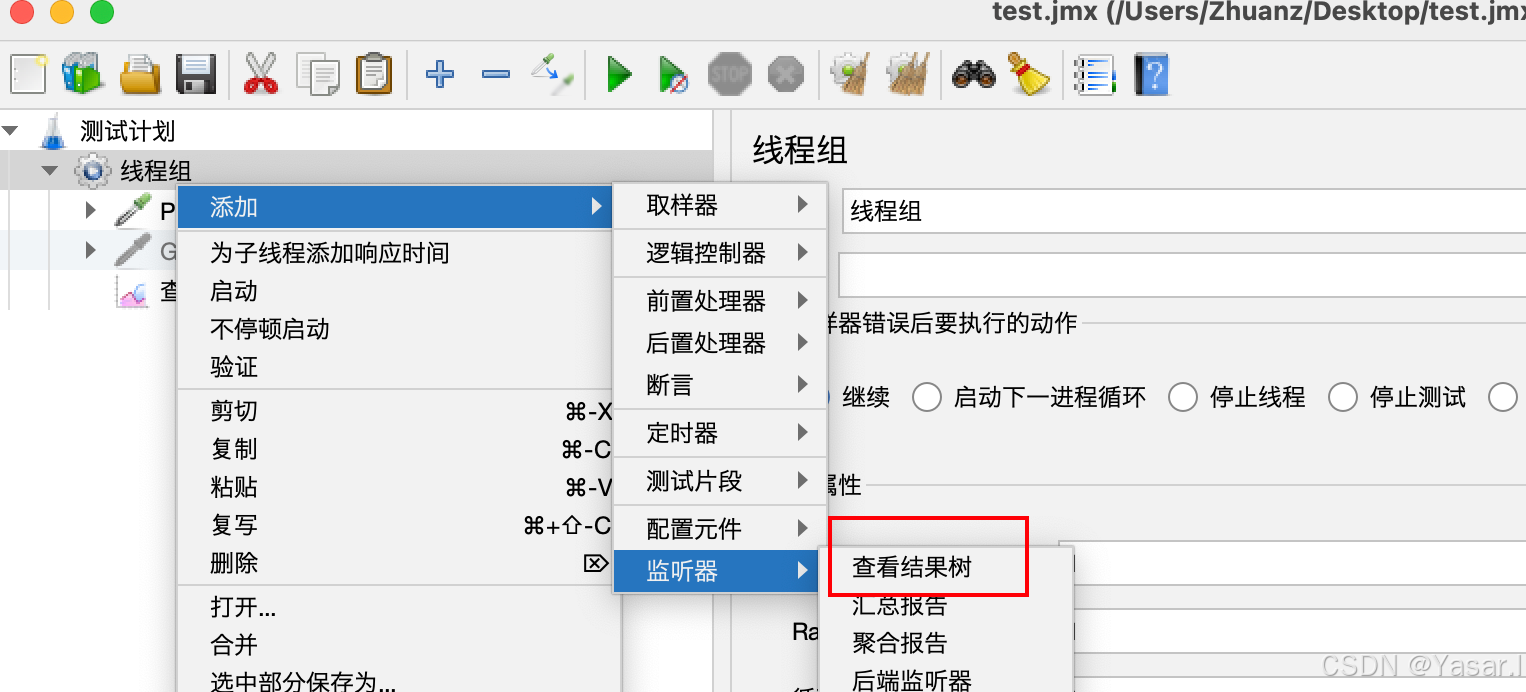
-
添加监听器:
右键线程组 → 添加 → 监听器 → 察看结果树 -
验证内容:
-
响应状态码:200(成功)
-
响应数据:JSON/HTML 内容是否符合预期
-
3.6 常见问题与技巧
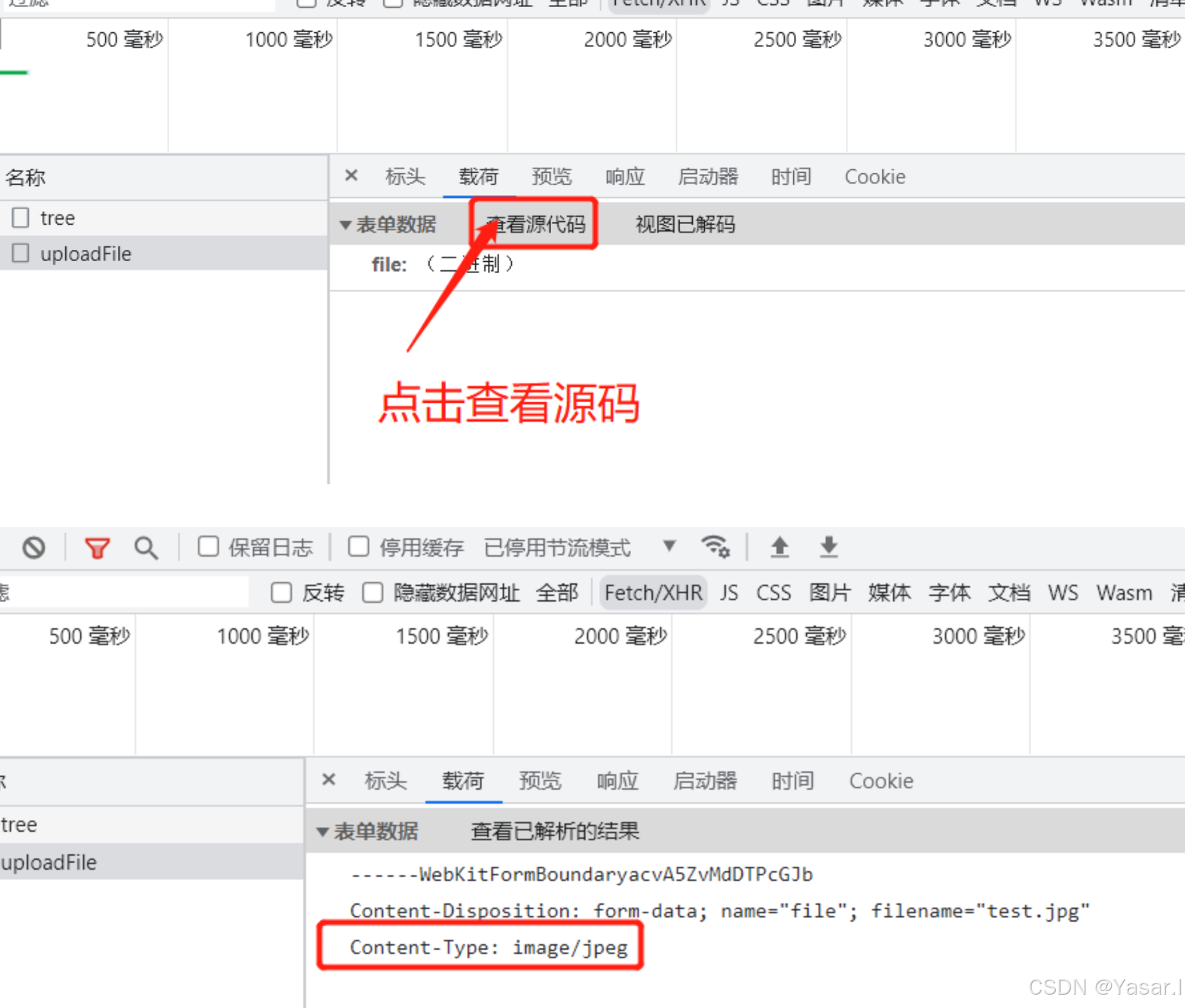
3.6.1 MIME 类型获取
-
抓包工具:使用 Fiddler、Charles 或浏览器开发者工具(F12),查看请求头中的
Content-Type。
4、断言
4.1 断言概念
-
作用:验证请求的实际结果是否符合预期,确保测试准确性(即使请求成功,结果可能错误)。
4.2 常用断言类型
(1) 响应断言
-
添加路径:
HTTP请求 → 右键添加 → 断言 → 响应断言 -
核心参数:
参数 说明 Apply to - Main sample and sub-samples(父子取样器)
- Main sample only(仅父取样器)
- Sub-samples only(仅子取样器)
- JMeter Variable(变量)测试字段 - 响应文本(Body)
- 响应代码(如200)
- 响应信息(如OK)
- URL样本模式匹配规则 - 包括(正则包含)
- 匹配(正则完全匹配)
- Equals(全等,区分大小写)
- Substring(子串,区分大小写)逻辑关系 - 勾选“或”:任一模式匹配即成功
- 不勾选“与”:所有模式必须匹配 -
示例:
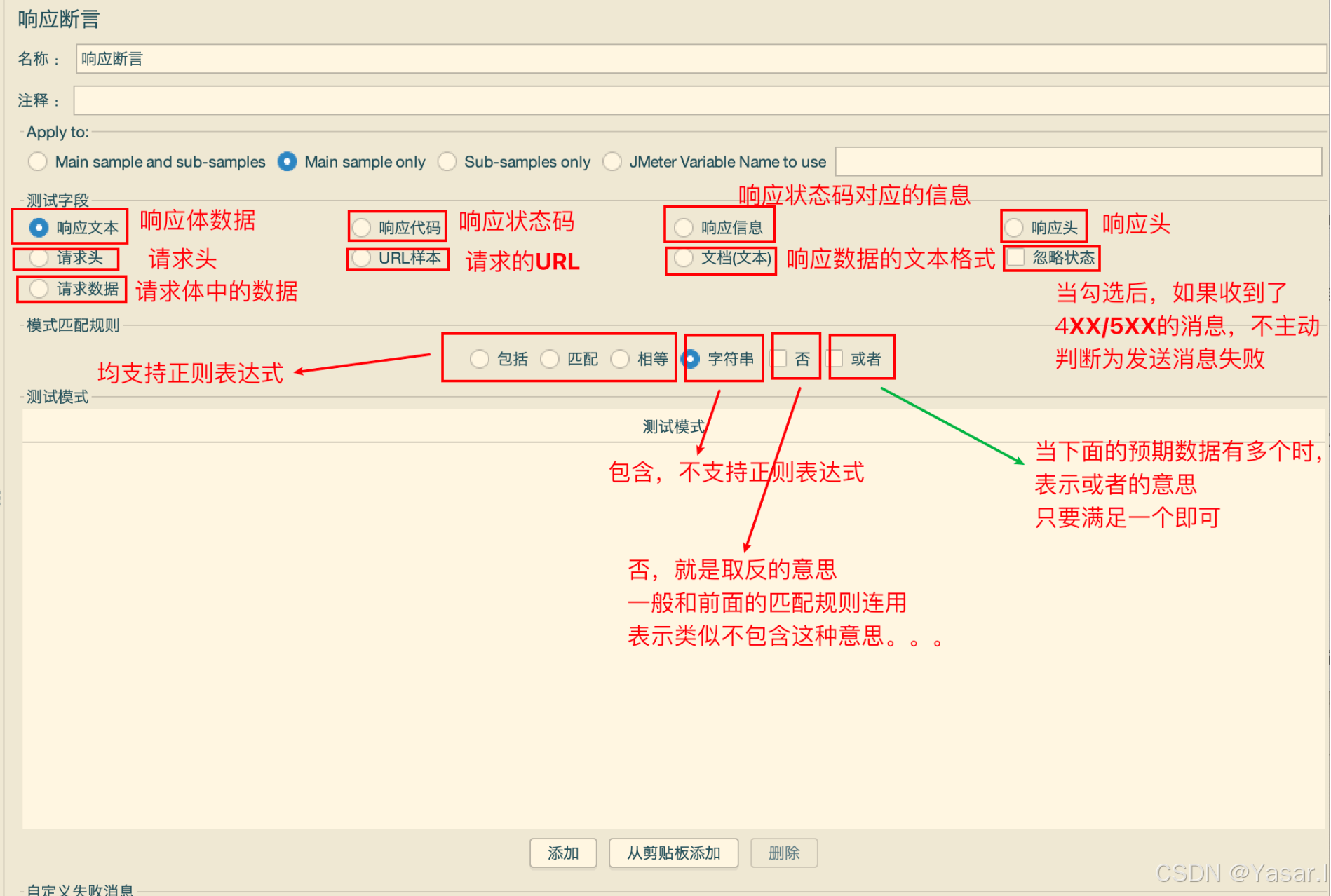
预期结果:响应文本包含 "success": true
配置:
- 测试字段:响应文本
- 模式匹配规则:包括
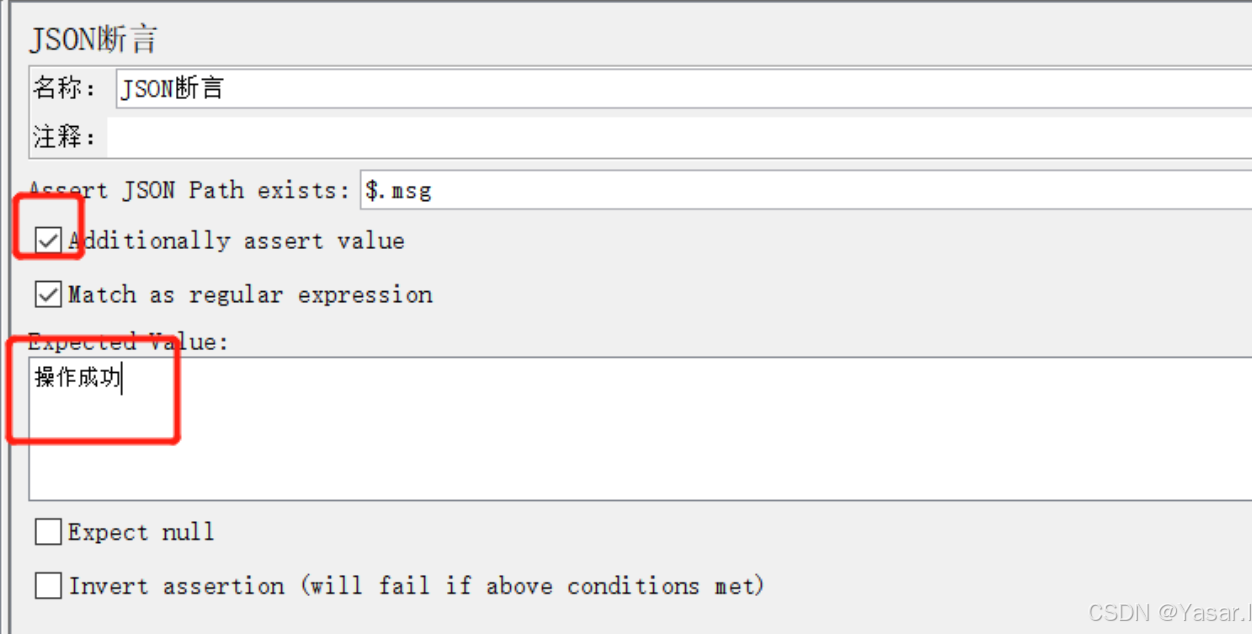
- 模式:".*"success": true.*" (2) JSON断言
-
添加路径:
HTTP请求 → 右键添加 → 断言 → JSON断言 -
核心参数:
参数 说明 JSON Path 使用JSONPath表达式提取值(如 $.code提取根节点下的code字段)预期值 期望匹配的值(如 200) -
示例:
预期结果:返回的JSON中code字段为200 配置: - JSON Path表达式:$.code - 预期值:200详细用法参见:https://github.com/json-path/JsonPath
5、参数化
5.1、参数化的作用
-
动态替换请求中的固定值(如用户名、密码、ID等),模拟真实用户行为。
-
避免重复数据导致的问题(如数据库主键冲突)。
-
实现多用户并发测试,增强测试场景的真实性。
5.2、JMeter参数化的常见方法
5.2.1 使用CSV文件(最常用)
适用场景:大量测试数据需要动态读取(如批量用户登录)。
步骤:
-
准备CSV文件
创建文本文件(如users.csv),格式示例:username,password user1,123456 user2,654321
-
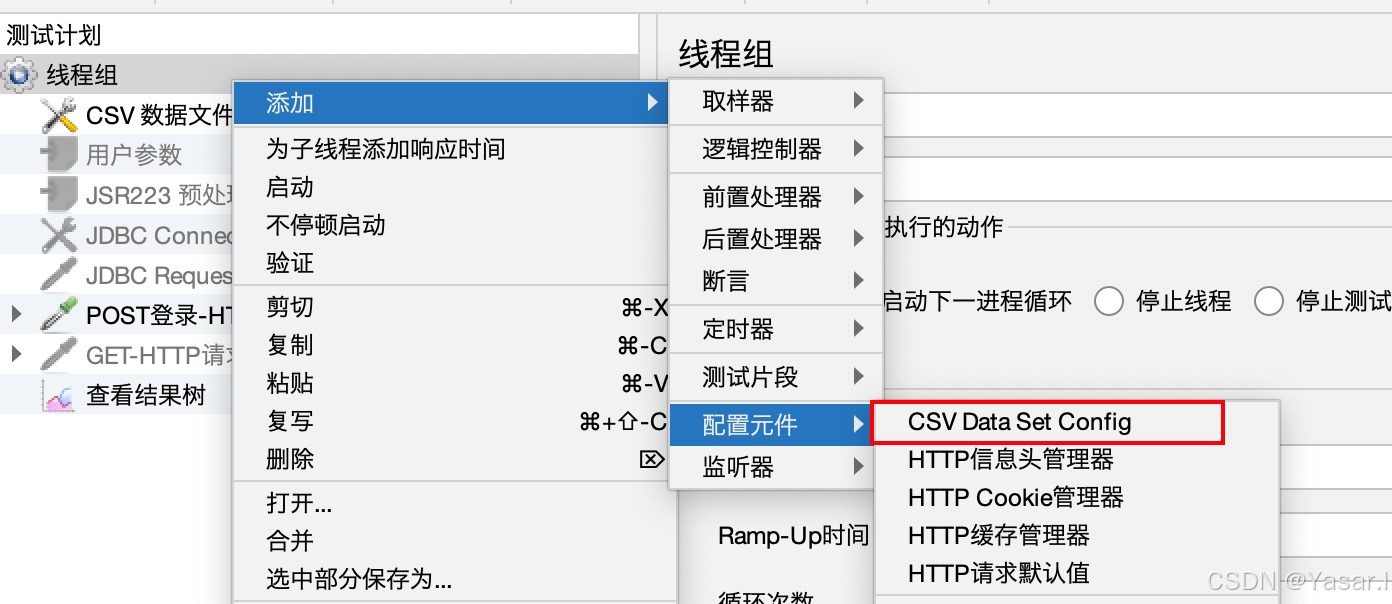
添加CSV Data Set Config
-
右键线程组 → 添加 → 配置元件 → CSV Data Set Config。
-
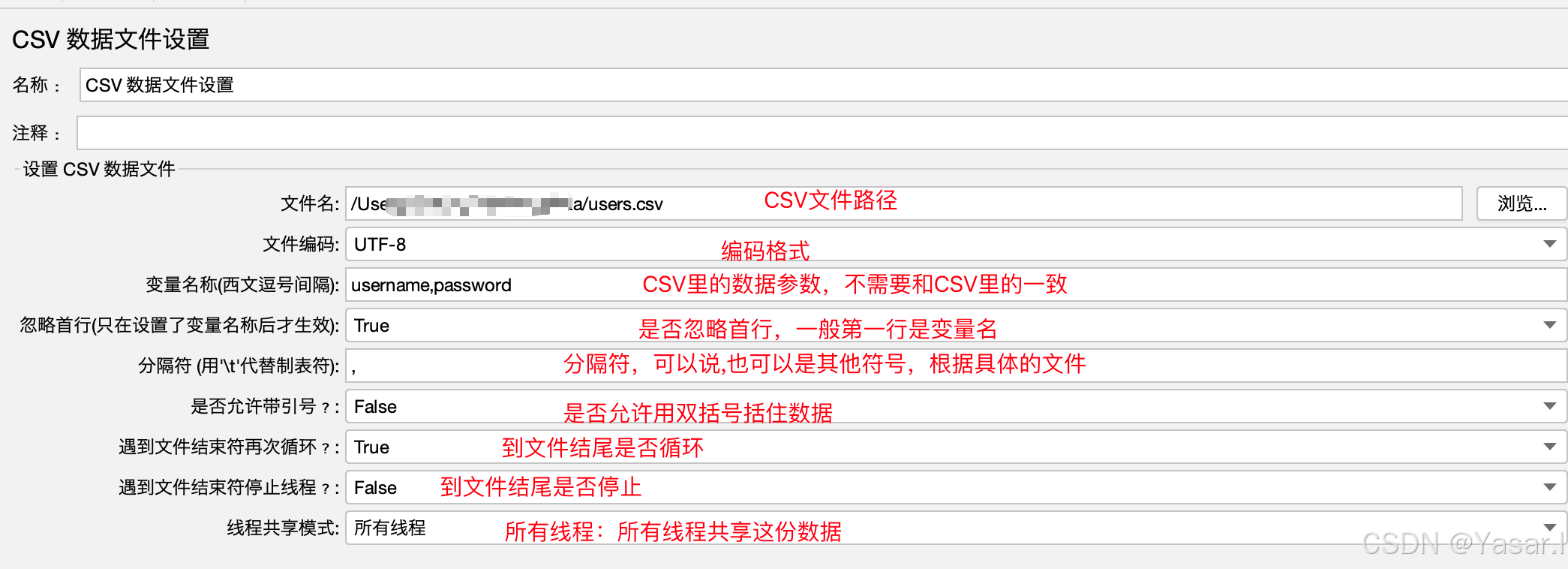
配置参数:
-
Filename: CSV文件路径(建议使用绝对路径)。
-
Variable Names: 变量名(如
username,password)。 -
Delimiter: 分隔符(如逗号
,)。 -
Recycle on EOF?: 数据循环方式(
True表示循环读取)。 -
Stop thread on EOF?: 数据用尽后是否停止线程。
-
-
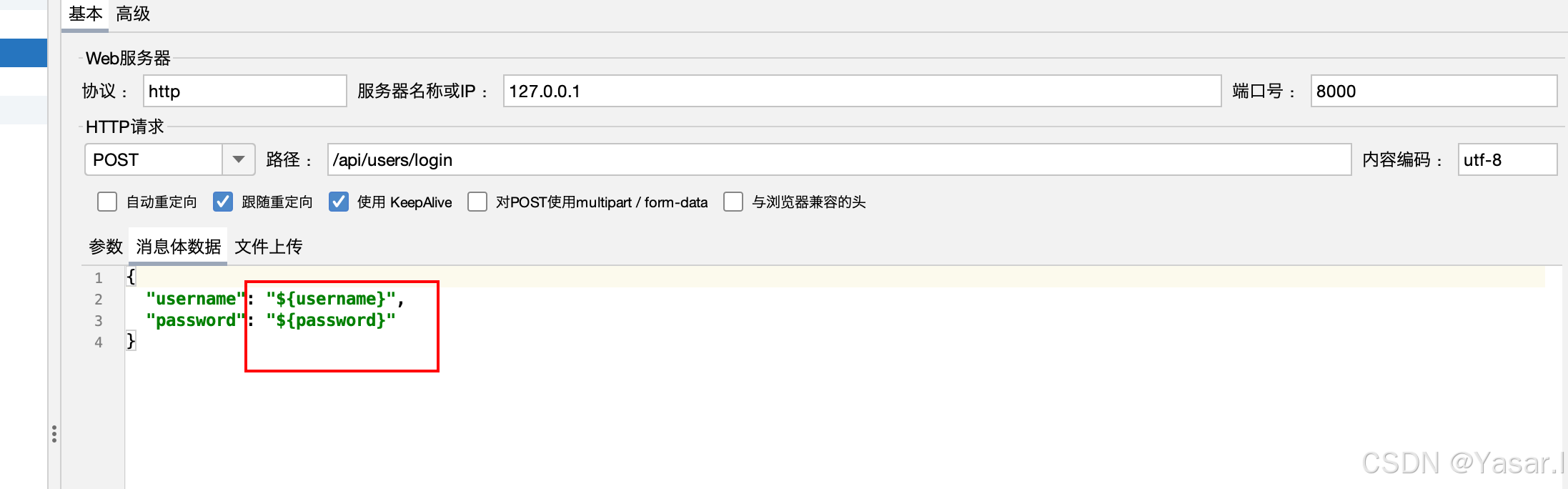
在请求中引用变量
使用${变量名}格式,如${username}、${password}。
-
结果:
5.2.2 使用用户参数(User Parameters)
适用场景:少量静态参数,且参数需要按线程组或用户独立设置。
步骤:
-
添加用户参数
-
右键线程组 → 添加 → 前置处理器 → 用户参数。
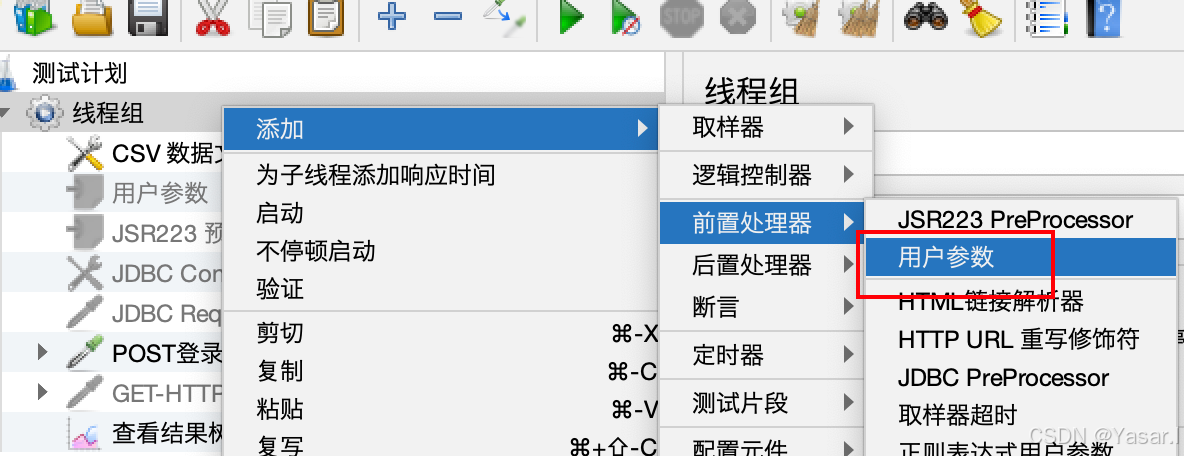
-
点击“添加变量”定义变量名(如
username)。 -
为每个变量设置不同值(每列对应一个用户/线程)。
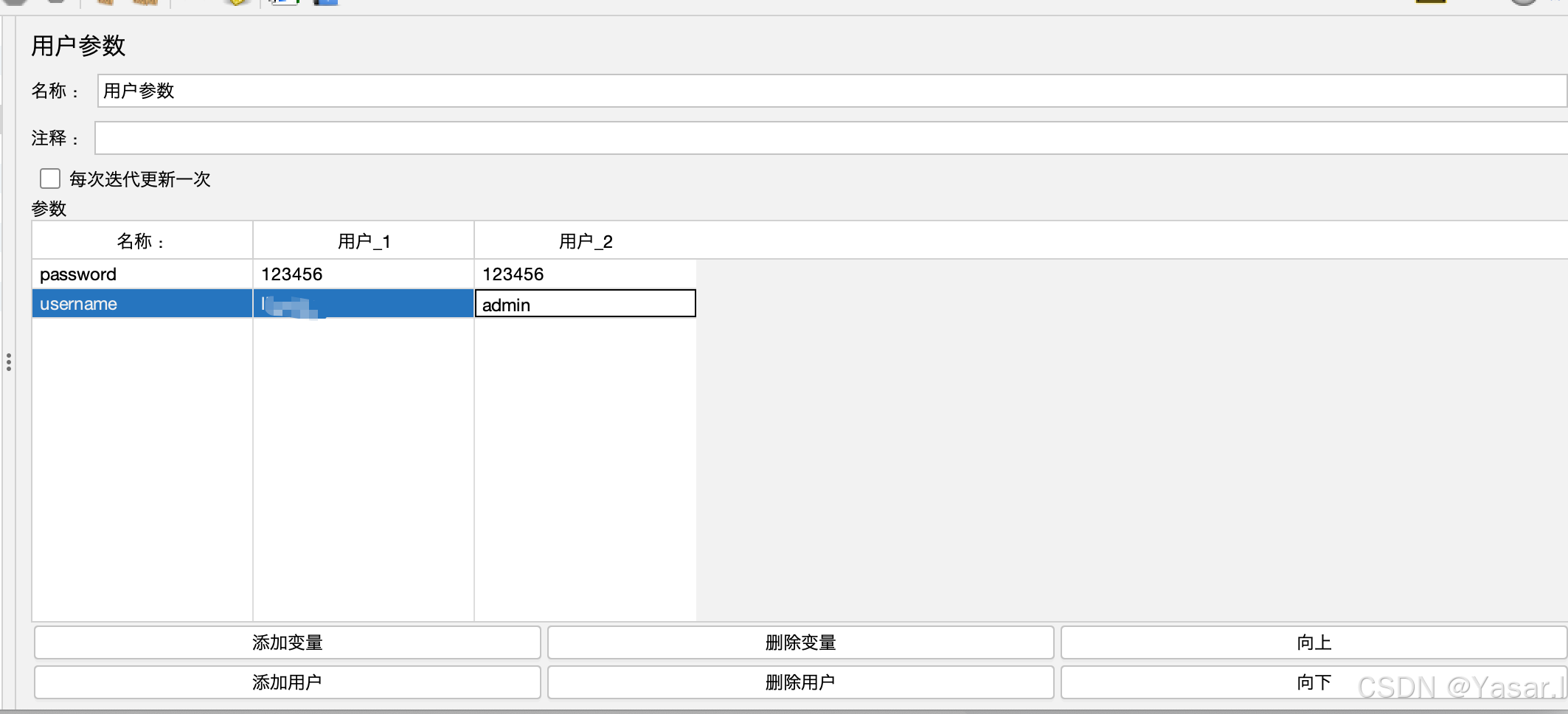
-
-
引用变量
在请求中使用${username}引用变量。
结果

5.2.3 使用随机函数(__Random, __RandomString等)
适用场景:生成随机数、字符串或日期。
常用函数:
-
${__Random(min,max,var)}: 生成区间随机数。
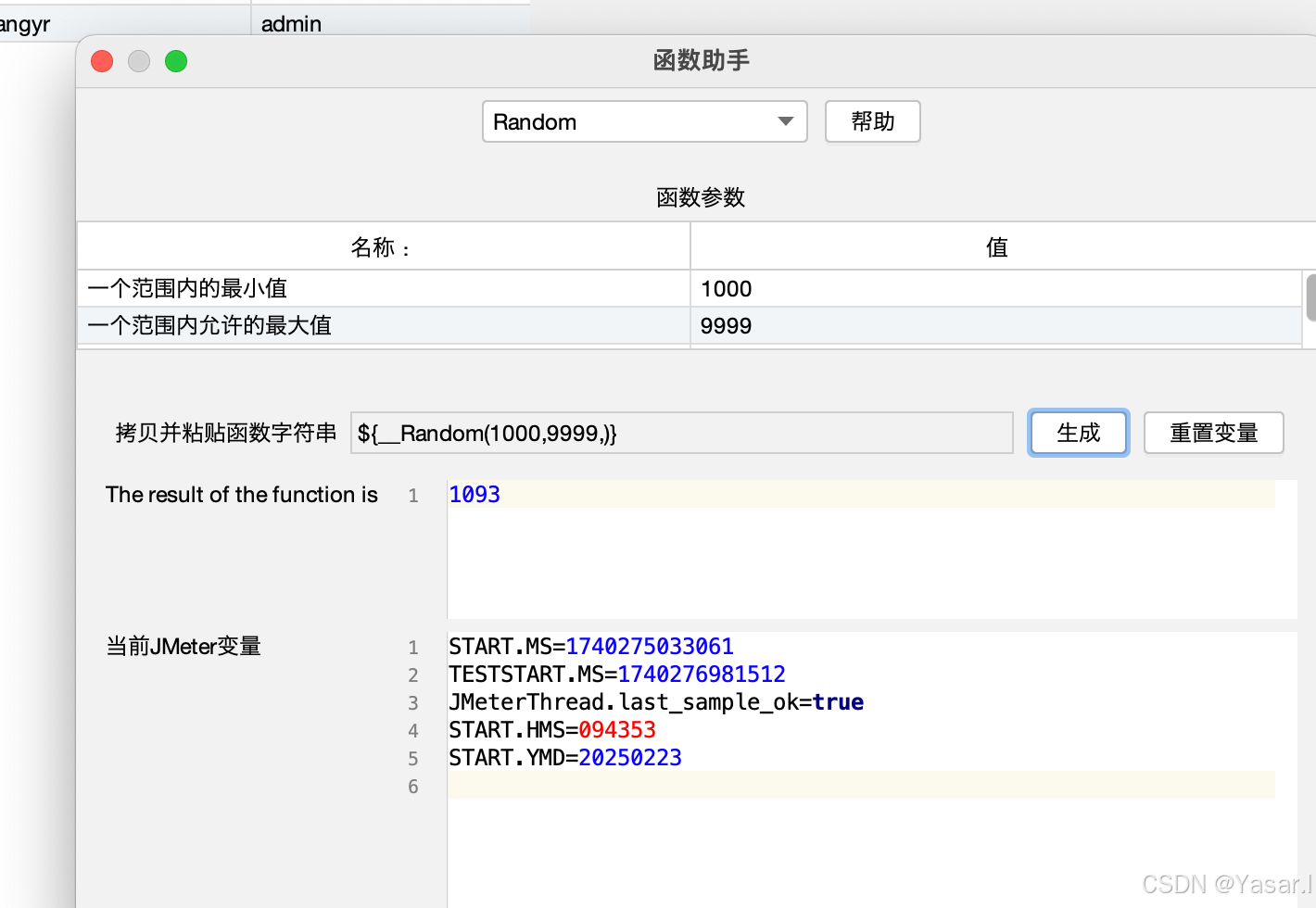
示例:${__Random(1000,9999,orderId)} → 生成4位随机数存入变量orderId。 -
${__RandomString(length,chars,var)}: 生成随机字符串。
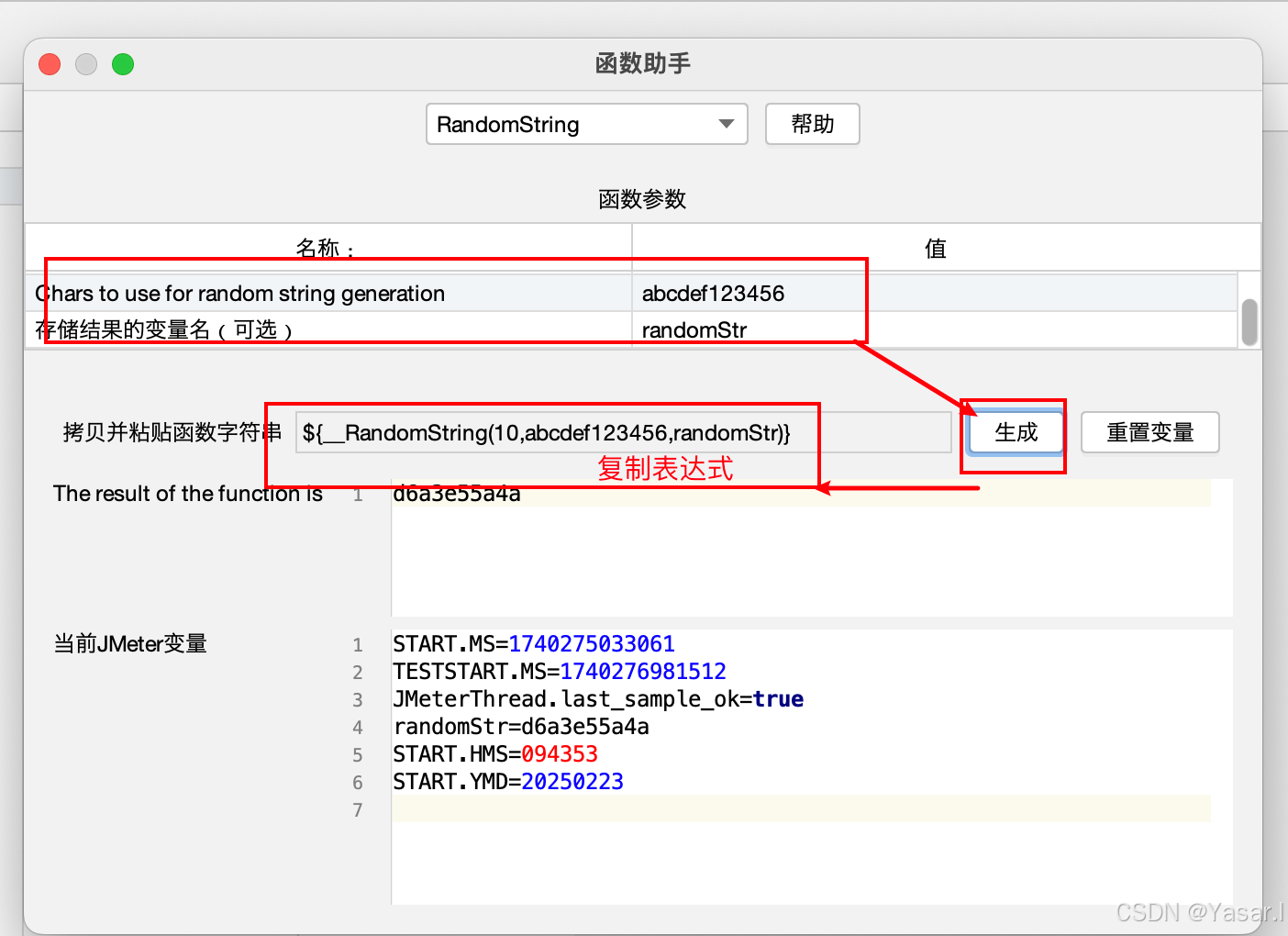
示例:${__RandomString(10,abcdef123456,randomStr)} → 生成10位包含字母和数字的字符串。
操作:
-
通过函数助手生成函数(工具 → 函数助手对话框)。

-
直接手动输入函数表达式。
-
函数助手有很多函数自行查看
5.2.4 从数据库读取参数
一、准备工作
-
下载MySQL JDBC驱动
-
访问MySQL官网下载Connector/J驱动:
https://dev.mysql.com/downloads/connector/j/ -
选择与你的MySQL版本兼容的驱动(如
mysql-connector-java-8.0.x.jar)。
-
-
将驱动文件放入JMeter的
lib目录-
将下载的JDBC驱动JAR文件复制到JMeter安装目录的
lib/文件夹中。
-
重启JMeter,确保驱动生效。
-
二、配置JDBC连接
1. 添加JDBC连接池配置
-
右键测试计划 → 添加 → 配置元件 → JDBC Connection Configuration。
-
配置以下参数:
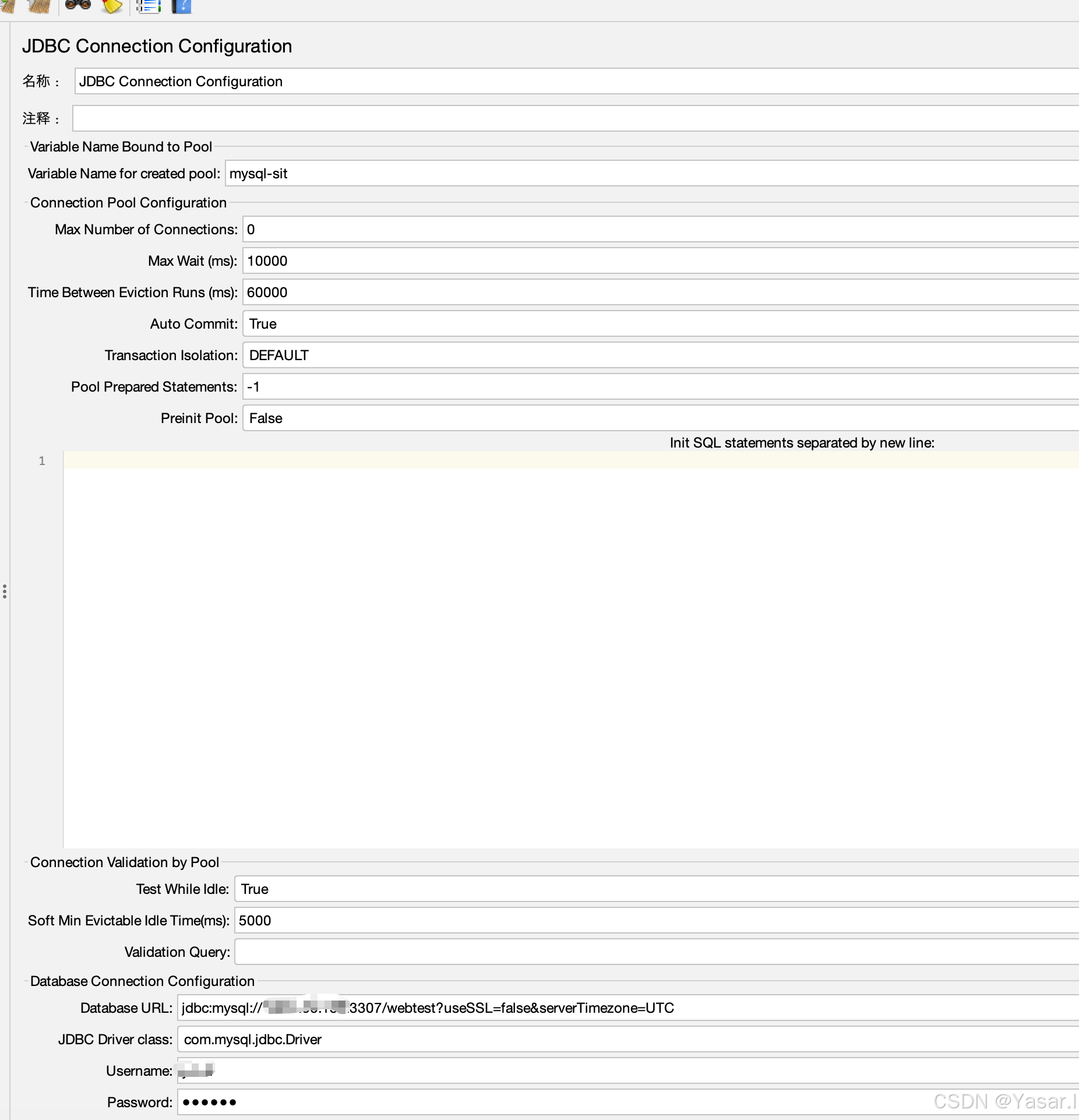
参数名 值示例 说明 Variable Name mysql_db连接池名称,后续JDBC请求需引用此名称。 Database URL jdbc:mysql://localhost:3306/test_db?useSSL=false&serverTimezone=UTCMySQL连接URL, test_db为数据库名,根据实际情况修改。JDBC Driver Class com.mysql.cj.jdbc.DriverMySQL 8.x驱动类名;若用MySQL 5.x,则填 com.mysql.jdbc.Driver。Username root数据库用户名。 Password 123456数据库密码。 注意:
-
若出现时区错误,在URL中添加
&serverTimezone=UTC。 -
若无需SSL,添加
useSSL=false。 -
MySQL 8.x默认使用
com.mysql.cj.jdbc.Driver,旧版本驱动类名可能不同。
-
2. 连接池高级配置(可选)
-
Max Number of Connections: 连接池最大连接数(默认10)。
-
Test While Idle: 定期验证空闲连接是否有效。
-
Validation Query:
SELECT 1(用于验证连接有效性)。
三、添加JDBC请求执行SQL
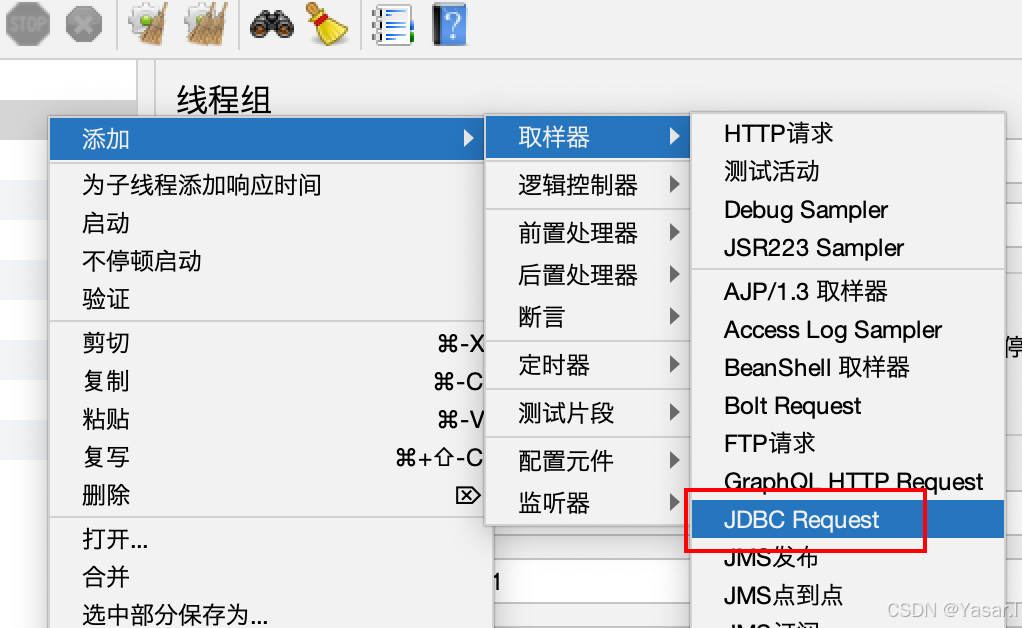
1. 添加JDBC请求
-
右键线程组 → 添加 → 取样器 → JDBC Request。
-
配置参数:
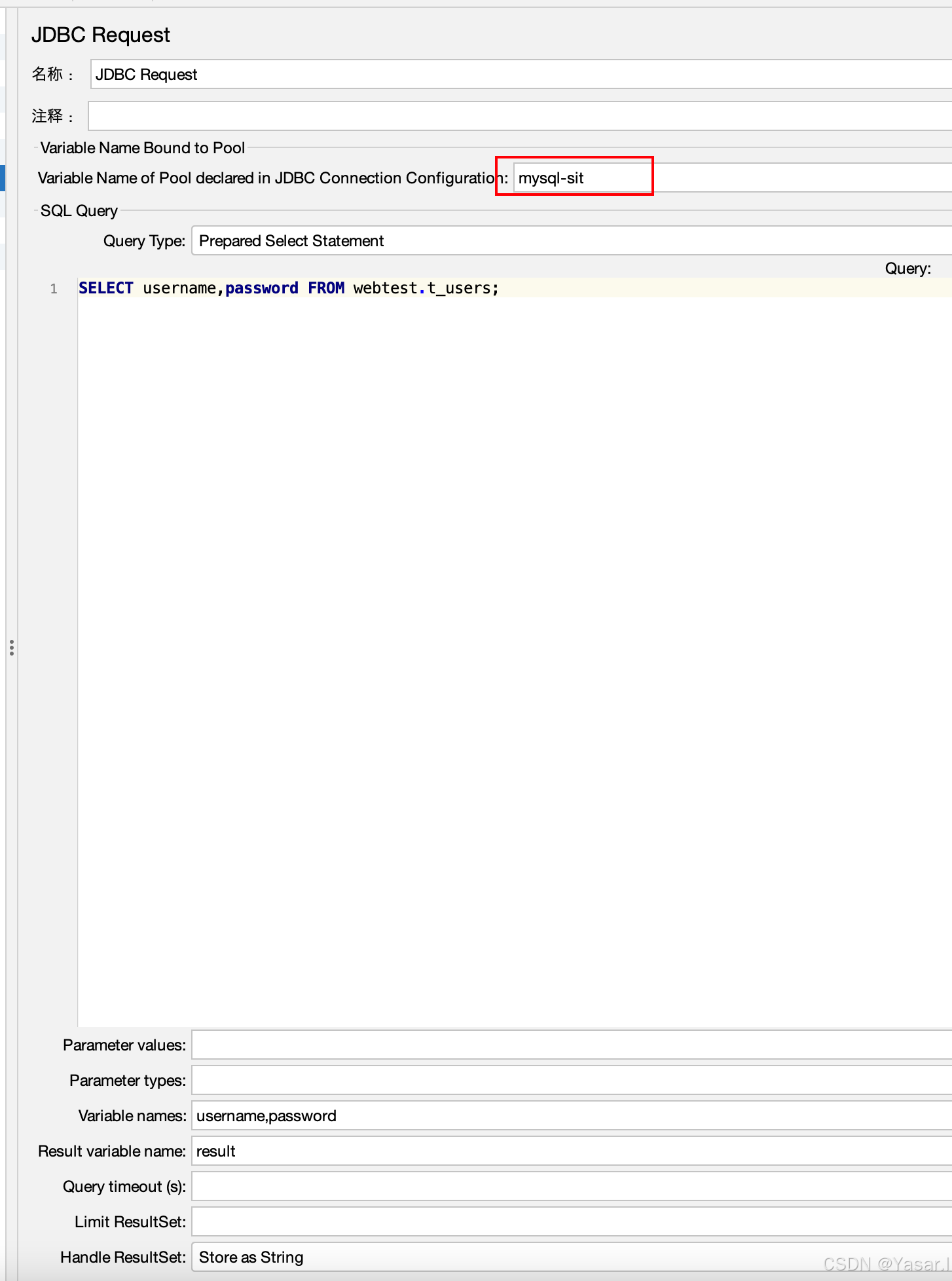
参数名 值示例 说明 Variable Name mysql_db必须与JDBC连接配置中的名称一致。 SQL Query SELECT * FROM users;输入要执行的SQL语句(支持增删改查)。 Parameter values ${user_id}SQL参数化(需配合变量使用,如 WHERE id = ?)。Parameter types INTEGER参数类型(如INTEGER、VARCHAR等)。 Variable Names id,name,age将查询结果列存入变量(格式:列名或别名)。 Result variable result将整个结果集存入变量(通过 ${result_1}获取第一行第一列的值)。
2. 示例:查询用户数据并参数化
SELECT id, username FROM users WHERE age > ?;-
参数化配置:
-
Parameter values:
18(直接输入值)或${min_age}(使用变量)。 -
Parameter types:
INTEGER。 -
Variable Names:
user_id,user_name。
-
-
引用结果变量:
-
第一行数据:
${user_id_1},${user_name_1}。 -
总行数:
${user_id_#}。
-
6、关联
6.1 关联的作用
-
处理动态值:如Session ID、Token、订单号等服务器生成的随机数据。
-
保证业务流程连贯性:例如登录后的操作需携带认证Token。
-
模拟真实用户行为:动态数据确保每次请求的独立性。
6.2 关联实现步骤
-
发送请求:获取包含动态数据的响应(如登录接口返回Token)。
-
提取数据:使用后置处理器(如正则表达式、JSON提取器)捕获目标值。
-
传递数据:在后续请求中引用提取的变量。
6.3 常用关联方法
6.3.1 正则表达式提取器(Regular Expression Extractor)
适用场景:HTML、XML或非结构化文本响应。
配置步骤:
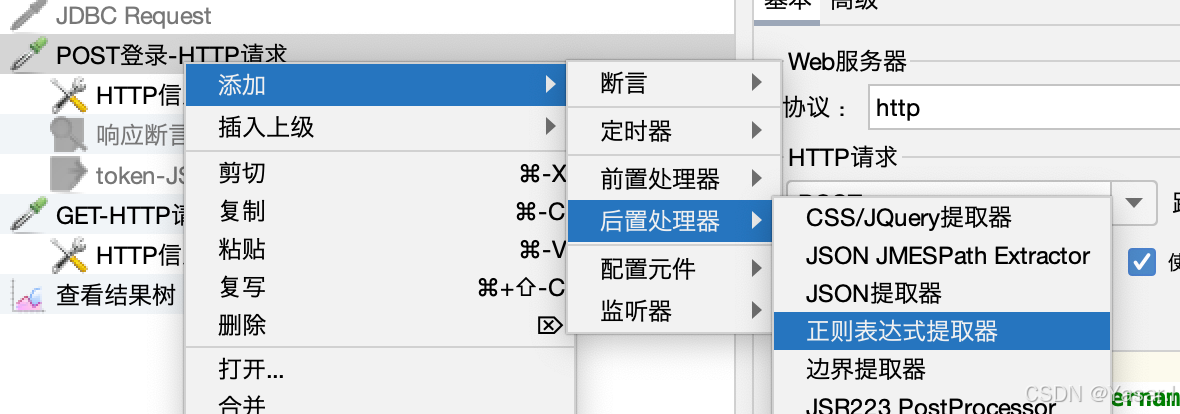
-
添加正则表达式提取器
-
右键目标请求 → 添加 → 后置处理器 → 正则表达式提取器。
-
-
配置参数:
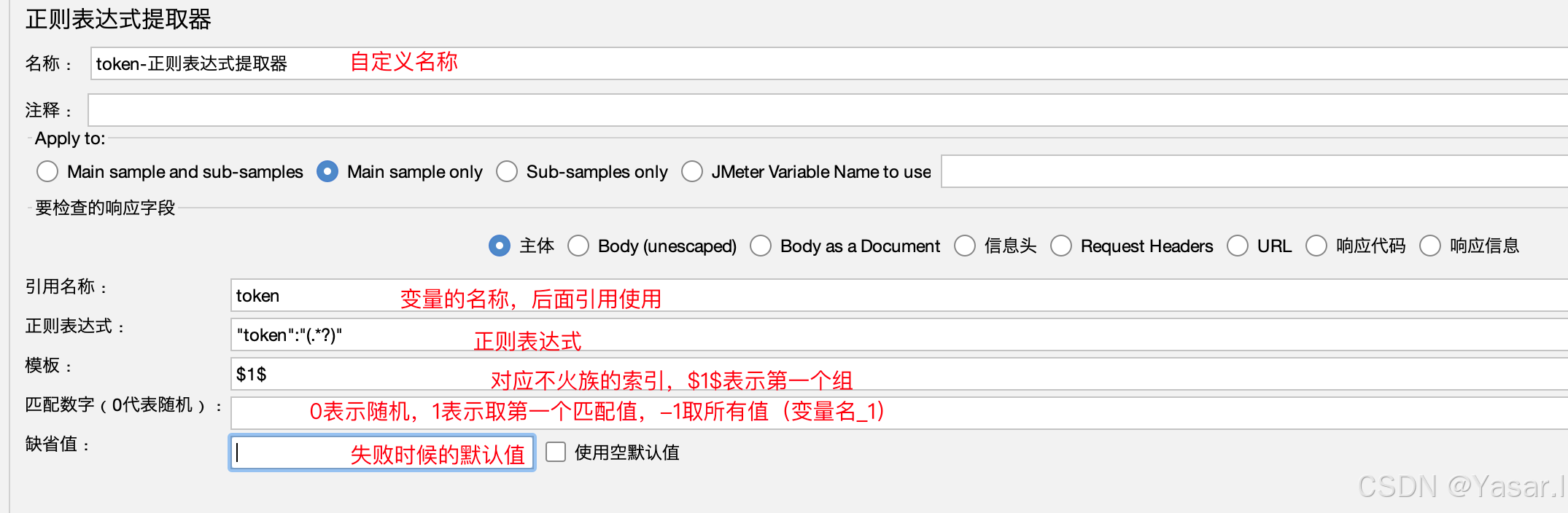
参数 示例值 说明 名称 提取Token 自定义名称(便于识别)。 应用于 Main sample only 默认处理主请求响应。 要检查的字段 响应主体 可选响应头、URL等。 正则表达式 "token":"(.*?)"使用捕获组 (.*?)匹配目标值(懒惰模式)。模板 $1$对应捕获组的索引(如 $1$表示第一个组)。匹配数字 10表示随机,1取第一个匹配值,-1取所有值(存为变量名_1, 变量名_2等)。缺省值 NOT_FOUND 匹配失败时的默认值(便于调试)。 -
引用变量:
-
后续请求中使用
${token}引用提取的值。
-
6.3.2 JSON提取器(JSON Extractor)
适用场景:响应为JSON格式时更高效准确。
配置步骤:
-
添加JSON提取器
-
右键目标请求 → 添加 → 后置处理器 → JSON提取器。
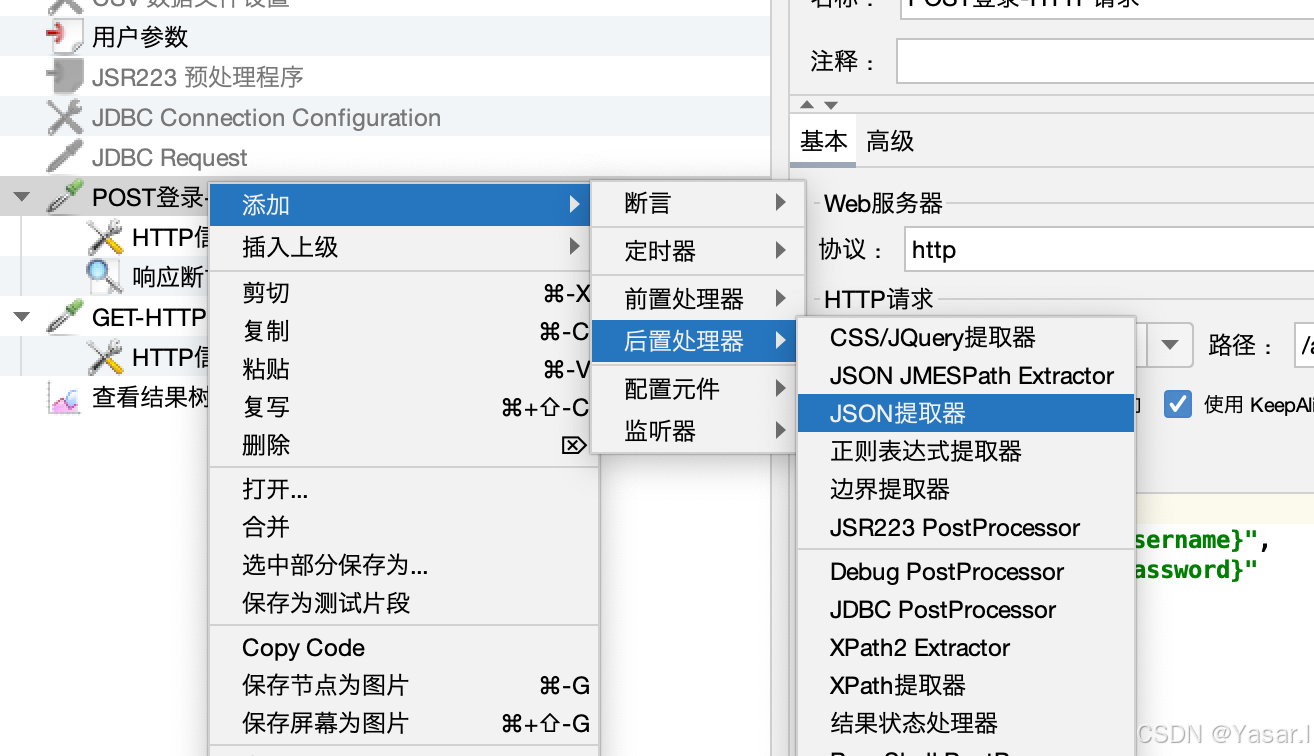
-
-
配置参数:
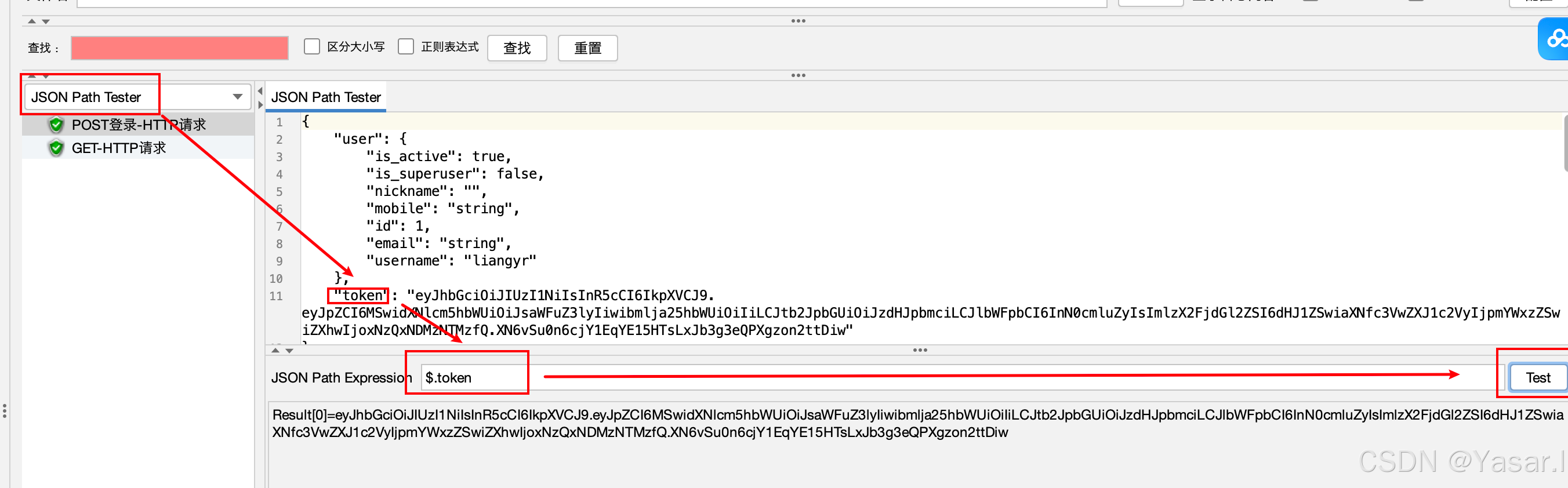
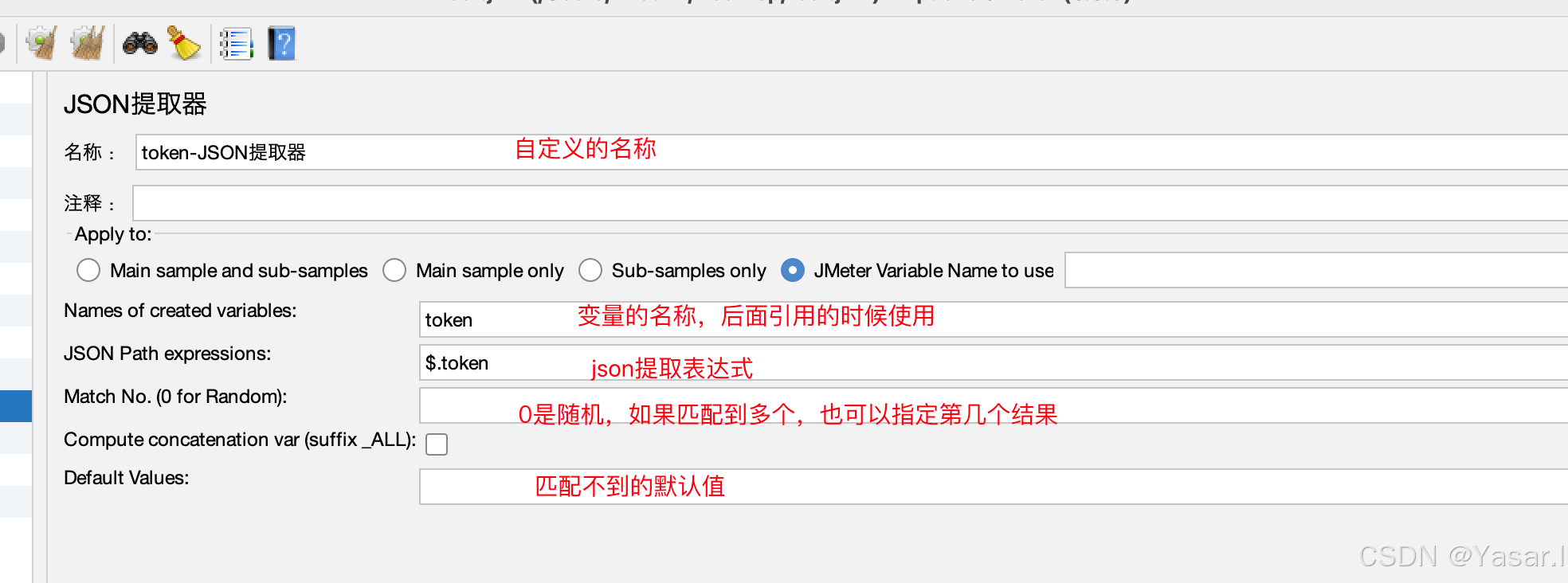
参数 示例值 说明 名称 提取用户token 自定义名称。 JSON Path表达式 $.token使用JSONPath语法定位目标值(JSONPath语法参考)。 变量名称 token存储提取结果的变量名。 缺省值 NOT_FOUND 匹配失败的默认值。 -
引用变量:
-
后续请求中使用
${token}。
-
6.3.3 XPath提取器(XPath Extractor)
适用场景:XML或HTML结构响应。
配置步骤:
-
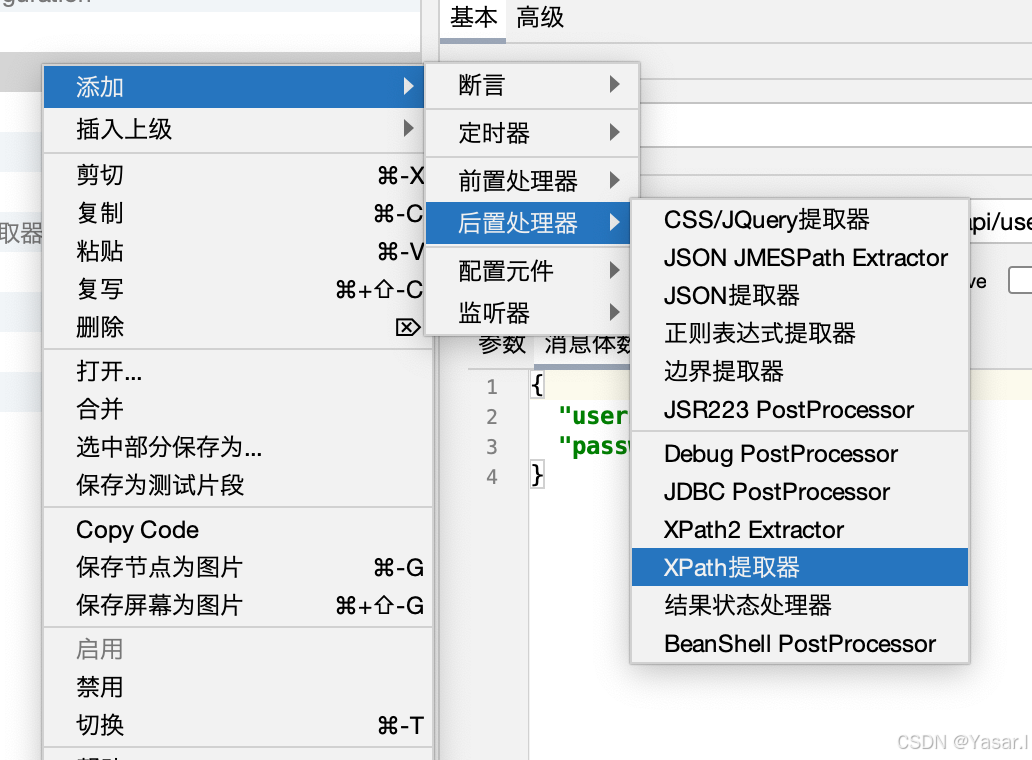
添加XPath提取器
-
右键目标请求 → 添加 → 后置处理器 → XPath提取器。
-
-
配置参数:
参数 示例值 说明 名称 提取订单号 自定义名称。 XPath查询 //order/id/text()使用XPath语法定位目标节点。 变量名称 order_id存储提取结果的变量名。 缺省值 NOT_FOUND 匹配失败的默认值。 -
引用变量:
-
后续请求中使用
${order_id}。
-
7、BeanShell
7.1 BeanShell 元件类型
-
前置处理器(PreProcessor):在请求 前 执行,用于参数生成、数据预处理。
-
后置处理器(PostProcessor):在请求 后 执行,用于响应解析、数据提取。
-
断言(Assertion):验证响应结果,动态判断测试是否通过。
-
定时器(Timer):动态调整等待时间(如根据变量计算延迟)。
-
监听器(Listener):自定义结果处理逻辑(如统计特定指标)。
7.2 核心内置对象
-
vars(JMeterVariables)vars.get("变量名"); // 获取变量值(String类型) vars.put("变量名", "值"); // 存储变量值(自动转String) vars.putObject("对象变量名", new Object()); // 存储非字符串对象 -
props(JMeterProperties)props.get("全局属性名"); // 获取全局属性(跨线程组共享) props.put("属性名", "值"); // 设置全局属性 -
log(Logger)log.info("信息"); // 输出INFO级别日志(JMeter界面可见) log.error("错误"); // 输出ERROR级别日志 -
ctx(JMeterContext)ctx.getPreviousResult(); // 获取前一个请求的响应结果(SampleResult) ctx.getThreadNum(); // 获取当前线程编号(0-based) ctx.getThread().getThreadName(); // 获取线程名称(如"Thread Group 1-1")
7.3 基础脚本结构
-
直接编写 Java 代码,无需完整类定义:
// 生成6位随机数字验证码 import java.util.Random; Random rand = new Random(); int code = 100000 + rand.nextInt(900000); vars.put("sms_code", String.valueOf(code));
8、命令行压测
8.1 JMeter命令行压测核心优势
-
无GUI模式(Non-GUI):节省系统资源,提升压测性能。
-
自动化集成:可与CI/CD工具(如Jenkins)结合,实现自动化测试。
-
分布式压测:通过多台机器协同执行,突破单机性能瓶颈。
8.2 基础命令行操作
8.2.1 基本命令格式
jmeter -n -t <测试脚本.jmx> -l <结果文件.jtl> -e -o <HTML报告目录>8.2.2 核心参数说明
| 参数 | 说明 |
|---|---|
-n | 非GUI模式运行。 |
-t <脚本> | 指定JMX测试脚本路径(必填)。 |
-l <结果> | 指定结果文件路径(.jtl或.csv格式)。 |
-e -o <目录> | 测试完成后生成HTML报告到指定目录(需先删除或清空目录)。 |
-J<参数> | 设置JMeter全局属性(如-Jthreads=100)。 |
-G<参数> | 分布式压测时设置全局属性(从控机继承)。 |
-R <IP列表> | 指定分布式压测的从机IP(逗号分隔,如-R 192.168.1.101,192.168.1.102)。 |
8.2.3 常用示例
示例1:基础压测
jmeter -n -t test_plan.jmx -l result.jtl示例2:生成HTML报告
jmeter -n -t test_plan.jmx -l result.jtl -e -o ./report示例3:动态覆盖线程数
jmeter -n -t test_plan.jmx -Jthreads=200 -Jrampup=60 -l result.jtl-
在脚本中使用
${__P(threads)}和${__P(rampup)}引用参数。
8.3 分布式压测(Remote Testing)
8.3.1 配置步骤
-
配置主控机(Controller)
-
修改JMeter安装目录下
bin/jmeter.properties:remote_hosts=127.0.0.1,slave1_ip:port,slave2_ip:port -
默认端口:
1099,确保防火墙开放此端口。
-
-
启动从机(Slave)
在每台从机上执行:jmeter-server -Djava.rmi.server.hostname=<从机IP> -
执行分布式压测
jmeter -n -t test_plan.jmx -R slave1_ip,slave2_ip -l result.jtl
8.3.2 注意事项
-
从机环境一致性:JMeter版本、依赖库、测试数据需与主控机一致。
-
网络延迟:确保主控机与从机之间的低延迟网络连接。
-
结果合并:各从机结果自动汇总到主控机的
.jtl文件中。
8.4 HTML报告生成与解析
1. 生成报告
jmeter -g result.jtl -o ./report-
-g:指定已有的结果文件生成报告。 -
-o:输出目录必须为空或不存在。
2. 报告核心指标
-
Dashboard:总请求数、吞吐量(Throughput)、响应时间分布(Median、90% Line)。
-
Charts:响应时间趋势、吞吐量趋势、活动线程数。
-
Statistics:各请求的详细统计(最小值、最大值、异常率)。
3. 自定义报告
修改 bin/reportgenerator.properties 调整图表样式和统计参数。
后续更新,点赞和收藏,更新更快

















 1707
1707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









