







一、用例执行方案
在构建测试平台的底层用例执行方案时,有几种常见的方案可以选择,包括接入现有的测试工具(如 JMeter、MeterSphere)、利用第三方自动化框架(如 HttpRunner)以及自定义封装引擎(使用 Python 封装的 FlexApi)。下面详细分析这三种方案的优缺点和适用场景。
1. 接入测试工具(如 JMeter、MeterSphere)
概述:
- JMeter 是一个广泛使用的性能测试工具,但它也能很好地用于 API 自动化测试。通过 JMeter,用户可以设计和执行 HTTP 请求,监控响应,验证 API 的行为。
- MeterSphere 是一个开源的持续测试平台,它集成了 JMeter 等工具,能够提供界面化的测试执行、报告生成以及与 CI/CD 集成等功能。
优点:
- 功能全面:JMeter 和 MeterSphere 提供了强大的图形界面,方便用户创建和管理复杂的测试计划、配置参数以及测试报告。
- 支持分布式执行:JMeter 支持分布式负载测试,适合进行大规模的性能测试。
- 开箱即用:这些工具本身就提供了丰富的功能,用户可以在没有开发的情况下快速开始使用。
- 可扩展性:通过插件或脚本,可以扩展 JMeter 的功能,支持更复杂的测试需求。
缺点:
- 学习曲线:虽然 JMeter 提供图形化界面,但对于复杂的测试逻辑,还是需要编写大量的配置和脚本,学习成本较高。
- 性能开销:JMeter 在处理大量请求时,可能会面临性能瓶颈。尤其在大型测试项目中,可能会导致机器资源消耗较高。
- 对开发者不友好:如果是开发人员,JMeter 的图形化界面可能不如直接通过代码控制来得灵活。
适用场景:
- 需要快速搭建测试环境,并且测试用例的管理和执行以图形化界面为主。
- 适合进行负载、压力测试,或是已有 JMeter/MeterSphere 环境的团队。
2. 利用第三方自动化框架(如 HttpRunner)
概述:
- HttpRunner 是一个开源的接口自动化测试框架,支持 HTTP 请求的自动化执行。它基于 Python 开发,允许使用 Python 编写测试用例,并支持数据驱动、断言、报告生成等常见功能。
优点:
- 易于集成:HttpRunner 可以与 CI/CD 工具(如 Jenkins、GitLab CI)集成,实现自动化执行。
- 代码编写灵活:通过编写 Python 脚本,可以灵活地控制测试逻辑,支持复用性高的函数和模块。
- 数据驱动支持:支持通过外部数据源(如 CSV、Excel)驱动测试用例执行。
- 社区支持:作为开源工具,HttpRunner 拥有较活跃的社区,可以在遇到问题时获得支持。
- 集成测试报告:自动生成可视化的测试报告,便于分析接口的运行结果。
缺点:
- 需要一定的开发能力:虽然 HttpRunner 封装了很多常用功能,但仍然需要一定的 Python 开发能力,尤其是在复杂测试场景下。
- 扩展性受限:对于非常复杂的需求或极高的并发负载测试,HttpRunner 可能需要一些二次开发。
适用场景:
- 对 Python 开发有一定了解的团队,适合进行接口自动化测试。
- 需要较高的灵活性和可定制性,并且希望在测试中执行复杂的逻辑处理。
3. 自定义封装引擎
概述:
- FlexApi 是自己封装的接口测试执行引擎,使用 Python 编写,能够为测试人员提供灵活且高效的接口自动化执行框架。通过自定义的引擎,您可以在测试过程中更好地控制用例执行、并发调度、数据管理等细节。
优点:
- 高度灵活:自定义的引擎完全根据自己的需求设计,可以精确控制测试的每个环节,执行流程、参数化、断言等都可以完全自定义。
- 更好的性能:根据需求调整执行引擎的性能,能够在高并发环境下优化执行效率。
- 细粒度控制:可以控制用例执行的顺序、依赖关系、错误处理、日志记录等方面,适合复杂测试场景。
- 扩展性强:可以根据需求扩展新的功能,如分布式执行、云端测试、第三方集成等。
缺点:
- 开发成本高:需要投入大量的时间和精力开发和维护测试框架,尤其是在涉及到复杂的用例执行、错误处理、数据管理等方面。
- 维护工作量大:随着平台的使用和业务的变化,框架的维护和升级也是一项长期的工作。
- 对非开发人员不友好:虽然框架高度定制化,但对于没有开发背景的人员,使用时可能不如现成的工具直观易用。
适用场景:
- 需要灵活定制测试平台,具备较强的开发能力,且测试需求复杂的团队。
- 适合对测试流程、性能和报告有高度要求的组织。
- 希望减少对第三方工具的依赖,同时具备可控性和扩展性的团队。
4、比较与选择
| 特性 | JMeter/MeterSphere | HttpRunner | FlexApi(自定义) |
|---|---|---|---|
| 开发要求 | 较低,图形化界面,易上手 | 中等,基于 Python 编写脚本 | 高,需要完整的框架开发与维护 |
| 灵活性 | 低,主要依赖图形化配置 | 高,可编写自定义 Python 脚本 | 非常高,完全根据需求定制 |
| 易用性 | 高,图形化界面友好 | 中等,需要编写 Python 脚本 | 较低,需要开发团队编写和维护框架 |
| 性能与并发能力 | 较高,支持分布式负载测试 | 较高,但不适合极高并发 | 可定制,适合高并发、定制化需求 |
| 社区支持与生态 | 强,JMeter 和 MeterSphere 的生态丰富 | 中等,开源且有活跃社区 | 较弱,需要团队自行维护和扩展 |
| 适用场景 | 负载测试、快速部署、已有工具使用 | 接口自动化测试、Python 环境、定制化需求 | 高度定制化、大型企业、复杂业务需求 |
总结:
-
JMeter / MeterSphere 适合需要快速集成并且主要进行负载测试和常规接口测试的场景。
-
HttpRunner 更适合对接口自动化测试有较高要求的团队,且具备一定的 Python 开发能力,能够灵活进行功能扩展和定制。
-
自定义封装引擎(FlexApi) 适合对测试框架有特殊需求的团队,尤其是在需要高性能、高可定制性和复杂测试逻辑的场景中。
二、测试引擎架构设计
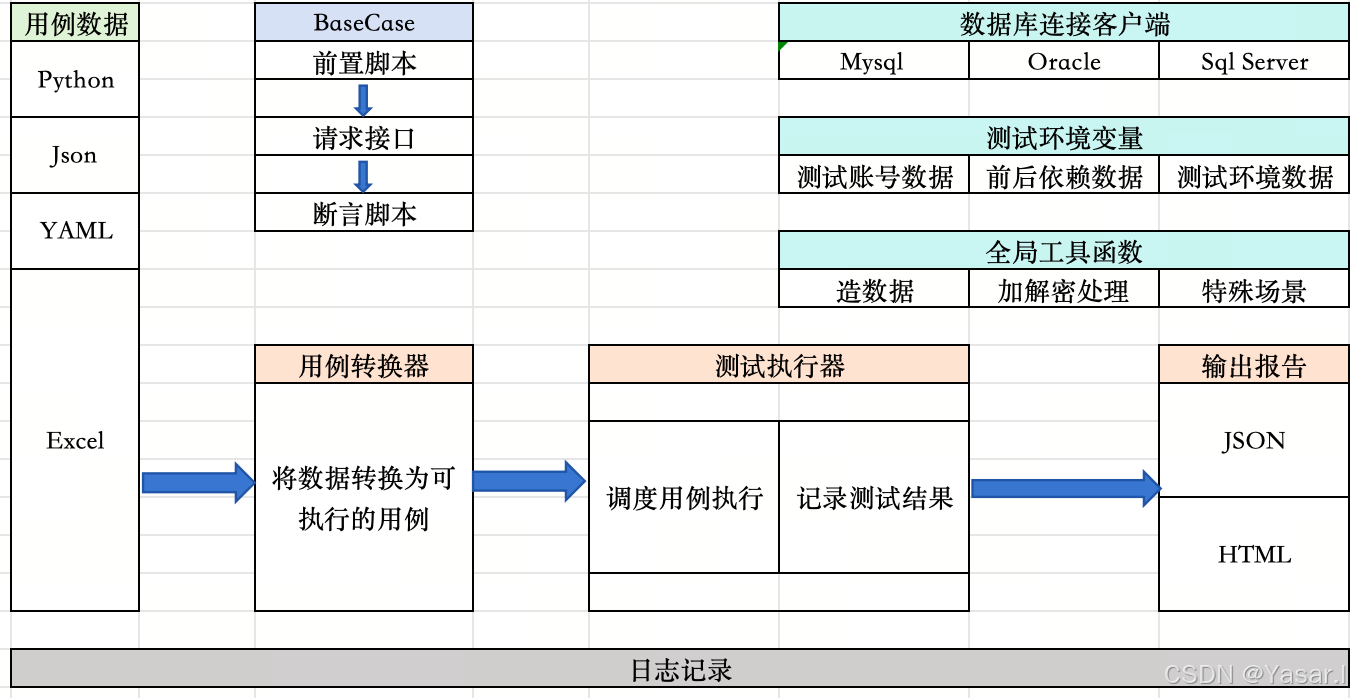 三、FlexApi框架实现
三、FlexApi框架实现
1、BaseCase封装
1.1、用例数据的设计格式
case = {
"title": "用例名称",
"interface": {
"url": "/api/users/login/",
"method": "post"
},
"headers": {
"Content-Type": "application/json"
},
"request": {
"params": {},
"data": {},
"json": {}
},
"setup_script": "print('前置脚本')",
"teardown_script": "print('后置断言脚本')"
}1.2、BaseCase的设计
import requests
# 测试环境
ENV = {
"base_url": "http://127.0.0.1:8000",
"headers": {
"Content-Type": "application/json"
},
"Envs": {
"token": "123123123",
"uid": "1",
"username":"2112121qq",
"email":"123a45qwe@qq.com"
},
}
class BaseCase:
"""用例执行的基本父类"""
def __setup_script(self, data):
"""
脚本执行前
:param data:
:return:
"""
print("前置脚本执行")
def __teardown_script(self, data):
"""
脚本执行后
:param data:
:return:
"""
print("后置脚本执行")
def __send_request(self, data):
"""
发送请求的方法
:param data:
:return:
"""
print('调用接口')
def perform(self, data):
"""
执行单条用例的入口方法
:param data:
:return:
"""
# 执行前置脚本
self.__setup_script(data)
# 发送请求
self.__send_request(data)
# 执行后置脚本
self.__teardown_script(data)
if __name__ == '__main__':
# baseUrl :测试环境的域名+端口
case = {
"title": "用例名称",
"interface": {
"url": "/api/users/register/",
# 如果是项目外的第三方接口,url应该是一个完整的地址:https://www.baidu.com/api/users/register/
"method": "post"
},
"headers": {
"Content-Type": "application/json"
},
"request": {
"params": {},
"data": {
"username": 1234
},
"json": {
"username": "2112121qq",
"email": "123a45qwe@qq.com",
"password": "123456qwer",
"password_confirmation": "123456qwer"
},
"files": {}
},
"setup_script": "print('前置脚本')",
"teardown_script": "print('后置断言脚本')"
}
BaseCase().perform(case)1.3、用例请求数据的处理
将自己编写的用例数据格式,处理为requests发送请求时所需的数据格式
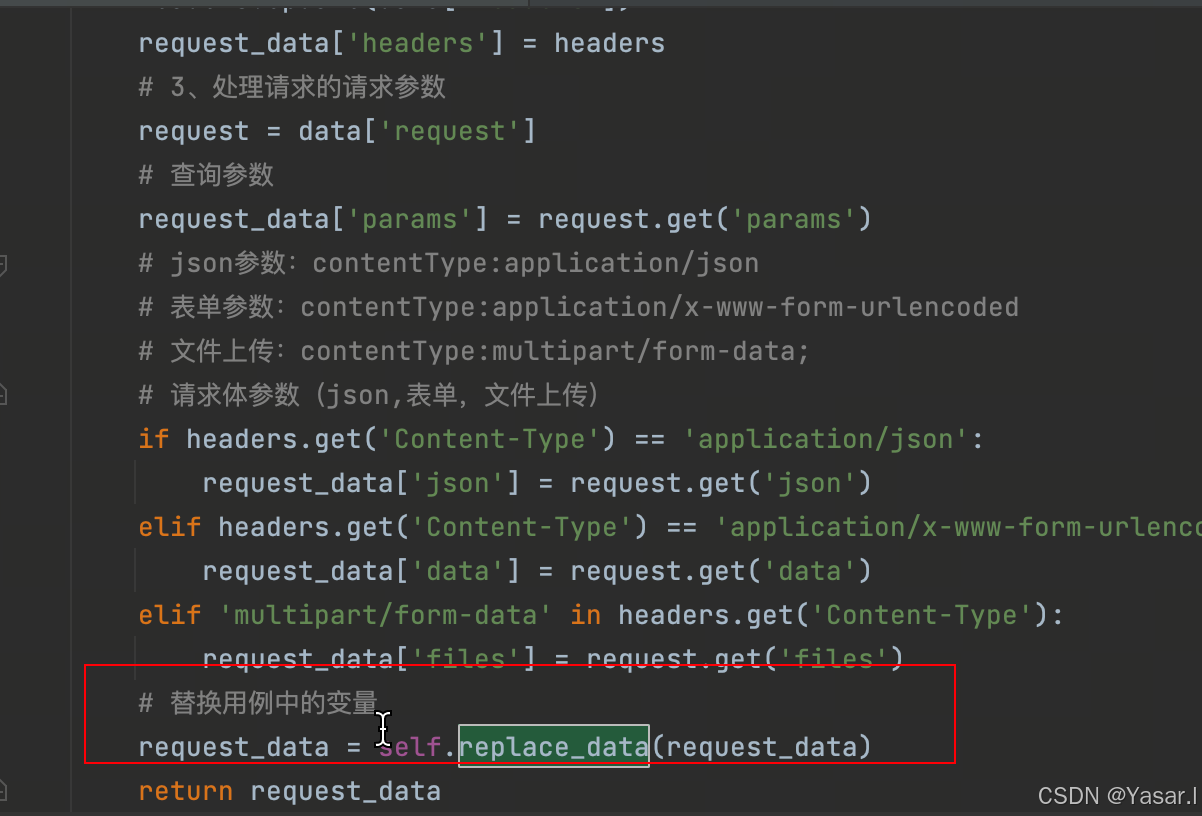
def __handler_requests_data(self, data):
"""处理请求数据的方法"""
request_data = {}
# 1、处理请求的url
request_data["method"] = data['interface']['method']
url = data['interface']['url']
# 如果不是http开头的url,则为内部接口,则拼装环境的地址
request_data["url"] = ENV.get('base_url') + url if not url.startswith('http') else url
# 2、处理请求的headers
# 获取全局请求头
headers: dict = ENV.get('headers')
# 将全局请求头和当前用例中的请求头进行合并
headers.update(data['headers'])
request_data['headers'] = headers
# 3、处理请求的请求参数
request = data['request']
# 查询参数
request_data['params'] = request.get('params')
# json参数:contentType:application/json
# 表单参数:contentType:application/x-www-form-urlencoded
# 文件上传:contentType:multipart/form-data;
# 请求体参数(json,表单,文件上传)
if headers.get('Content-Type') == 'application/json':
request_data['json'] = request.get('json')
elif headers.get('Content-Type') == 'application/x-www-form-urlencoded':
request_data['data'] = request.get('data')
elif 'multipart/form-data' in headers.get('Content-Type'):
request_data['files'] = request.get('files')
return request_data
def __send_request(self, data):
"""
发送请求的方法
:param data:
:return:
"""
# 处理用例的请求数据(替换请求参数中的变量,将数据转换为requests发送请求所需要的格式)
request_data = self.__handler_requests_data(data)
print(request_data)
# 发送请求
response = requests.request(**request_data)
print(response.text)
return response
运行结果

1.4、用例数据替换
-
用例数据中的变量使用:
${{变量}}来表示 -
在处理用例数据时需要将变量替换成当前测试环境中的数据
case = {
"title": "用例名称",
"interface": {
"url": "/api/users/register/${{uid}}",
# 如果是项目外的第三方接口,url应该是一个完整的地址:https://www.baidu.com/api/users/register/
"method": "post"
},
"headers": {
"Content-Type": "application/json",
"token": "${{token}}"
},
"request": {
"params": {},
"data": {
"username": 1234
},
"json": {
"username": "${{username}}",
"email": "${{email}}",
"password": "123456qwer",
"password_confirmation": "123456qwer"
},
"files": {}
},
"setup_script": "print('前置脚本')",
"teardown_script": "print('后置断言脚本')"
}-
变量替换的方法封装
def replace_data(self, data): """替换用例中的变量""" # 数据替换的规则 pattern = r'\${{(.+?)}}' # 将传入的参数转换为字符串 data = str(data) while re.search(pattern, data): # 获取匹配到的内容 match = re.search(pattern, data) # 获取匹配到的内容中的变量 key = match.group(1) # 获取全局变量中的值 value = ENV.get('Envs').get(key) # 将匹配到的内容中的变量替换为全局变量中的值 data = data.replace(match.group(), str(value)) # 转换成字典 return eval(data)在处理请求数据的__handle_request_data方法中,调用replace_data方法进行替换
-
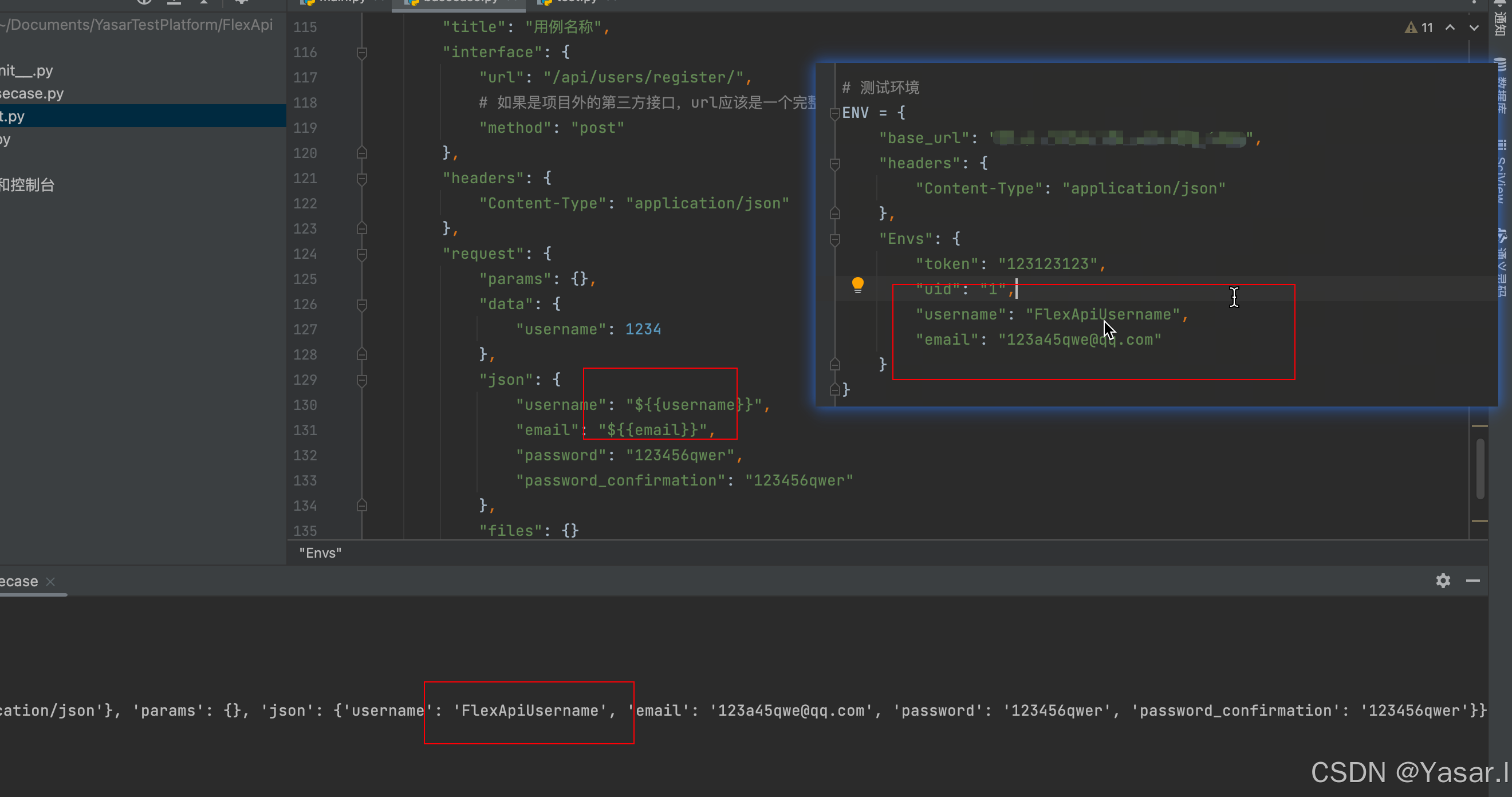
def __handler_requests_data(self, data): """处理请求数据的方法""" request_data = {} # 1、处理请求的url request_data["method"] = data['interface']['method'] url = data['interface']['url'] # 如果不是http开头的url,则为内部接口,则拼装环境的地址 request_data["url"] = ENV.get('base_url') + url if not url.startswith('http') else url # 2、处理请求的headers # 获取全局请求头 headers: dict = ENV.get('headers') # 将全局请求头和当前用例中的请求头进行合并 headers.update(data['headers']) request_data['headers'] = headers # 3、处理请求的请求参数 request = data['request'] # 查询参数 request_data['params'] = request.get('params') # json参数:contentType:application/json # 表单参数:contentType:application/x-www-form-urlencoded # 文件上传:contentType:multipart/form-data; # 请求体参数(json,表单,文件上传) if headers.get('Content-Type') == 'application/json': request_data['json'] = request.get('json') elif headers.get('Content-Type') == 'application/x-www-form-urlencoded': request_data['data'] = request.get('data') elif 'multipart/form-data' in headers.get('Content-Type'): request_data['files'] = request.get('files') # 替换用例中的变量 request_data = self.replace_data(request_data) return request_data
运行结果
eval() 是 Python 内置的一个函数,它能够将字符串当作 Python 表达式来执行,并返回执行结果。这个函数的语法如下:
eval(expression, globals=None, locals=None)
参数说明:
-
expression:这是一个字符串,包含合法的 Python 表达式。 -
globals(可选):提供一个字典,用作全局命名空间。默认是当前的全局命名空间。 -
locals(可选):提供一个字典,用作局部命名空间。默认是当前的局部命名空间。
返回值:
eval() 函数返回表达式执行的结果。如果表达式是有效的 Python 代码,eval() 就会执行它并返回结果;否则抛出异常。
基本用法:
# 示例 1: 简单的算术表达式
result = eval("3 + 5")
print(result) # 输出 8
# 示例 2: 使用变量
x = 10
result = eval("x * 2")
print(result) # 输出 20
1.5、前后置脚本的执行
def __run_script(self, data):
"""专门执行前后置脚本的函数"""
# 获取用例的前置脚本
setup_script = data.get('setup_script')
# 使用执行器函数执行python的脚步代码
exec(setup_script)
# 接受传进来的响应结果
response = yield
teardown_script = data.get('teardown_script')
exec(teardown_script)
yield前置脚本函数调整
def __setup_script(self, data):
"""
脚本执行前
:param data:
:return:
"""
# 使用脚本执行器函数创建一个生成器对象
self.script_hook = self.__run_script(data)
# 执行前置脚步(执行生成器中的代码)
next(self.script_hook)
后置脚本函数调整,由于后续,request请求的响应结果,需要通过后置脚本进行断言,因此需要通过send方法把request请求响应的内容传给后端脚本。
def __teardown_script(self, response):
"""
脚本执行后
:param data:
:return:
"""
# 执行后置脚本
self.script_hook.send(response)
# 删除生成器对象
delattr(self, 'script_hook')
perform方法调整,把__send_request方法的响应内容,当做参数传给后置脚本函数。
def perform(self, data):
"""
执行单条用例的入口方法
:param data:
:return:
"""
# 执行前置脚本
self.__setup_script(data)
# 发送请求
response = self.__send_request(data)
# 执行后置脚本
self.__teardown_script(response)输出效果:


















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









