






 本文解决了在使用Python的requests库进行HTTP请求时,因Header信息复制粘贴导致的错误。详细介绍了如何正确地保存和使用完整的Header信息,避免了在代码中出现因Header格式错误而引发的问题。
本文解决了在使用Python的requests库进行HTTP请求时,因Header信息复制粘贴导致的错误。详细介绍了如何正确地保存和使用完整的Header信息,避免了在代码中出现因Header格式错误而引发的问题。
错误提示在有header的一行
html = session.get(login_url, headers=header)
直接百度…是header自动缩略之后复制不自动复原的问题…那几个点点就是罪魁祸首嘎
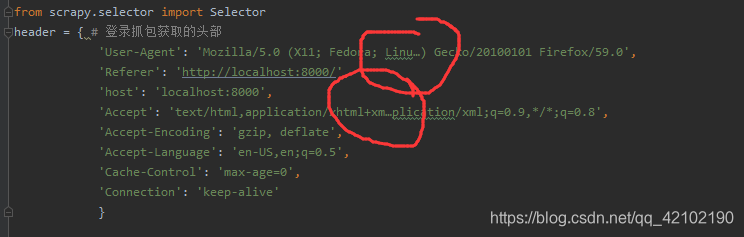
最后存一哈可以用的完整的header
header = { # 登录抓包获取的头部
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:60.0)Gecko/20100101 Firefox/60.0',
'Referer': 'http://localhost:8000/',
'host': 'localhost:8000',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'en-US,en;q=0.5',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive'
}

















 1117
1117

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









