






一、什么是Redis?
redis是一个开源,高级的键值存储和一个使用的
Redis的优点:
异常快:Redis是一个缓存数据库,数据存放在缓存中。
支持丰富的数据类型:支持开发人员常用的大多数数据类型,这使得Redis很容易被用来解决问题,因为我们知道哪些问题可以用哪些数据类型来很好的解决。
操作具有原子性:所有Redis操作都是一个原子操作,这确保如果两个客户端并发访问,Redis服务器能接收到更新的值
多实用工具:可以用于多种实例。
二、Redis和其他数据库的区别
1、Redis和MySQL的区别:
MySQL:关系型数据库,主要用于存放持久化数据,数据存放于磁盘中,读取速度较慢。
Redis:非关系型数据库,也是缓存数据库,也就是将数据存放于缓存中,缓存的读取速度快,能够大大的提高运行速率,但是保存时间是有限的。
2、Redis和Memchache的区别:
前者出现的较晚,弥补了后者很多的不足,但是两者目前都有自己的优势:
| Redis | Memchache | |
|---|---|---|
| 数据存储介质 | 数据存放在内存和磁盘中,能够达到持久化存储(RDB和AOF) | 都存放在内存中,一旦失效数据就丢失,无法恢复 |
| 数据存储方式 | 键值对,但支持set,hash,list,zet等数据结构的存储 | 键值对,只支持字符 |
| 架构层次 | Master-Slave(主从)模式 | 分布式 |
| 存储数据大小 | 单个Value存储的数据最大为1G | 存储的最大为1MB |
| 支持 | 只支持单核 | 支持多核 |
三、Redis的5种数据结构和底层实现
string(字符串)、list(列表)、hash(字典)、set(集合) 和 zset(有序集合)
1、string 字符串
是一种动态字符串,使用者可以修改。Redis为了对内存做到极致的优化,不同长度的字符串使用不同的结构体来表示。
为什么不采用C语言的字符串呢?获取字符串长度为O(N)级别的操作;不能很好的杜绝缓冲区溢出/内容泄露;只能保存文本数据(ASCII)。
2、List 列表
插入和删除速度快,时间复杂度为O(1),但是索引定位很慢,时间复杂度为O(n)。

本图和部分内容来源:Redis——5种数据结构底层实现原理_Slayer_Zhao的博客-优快云博客_redis数据底层结构
3.hash 字典
“数组+链表”的连地址法来解决部分哈希冲突。hashmap
4.Set 集合
键值对是无序的,唯一的。它的内部实现相当于一个特殊的字典,字典中所有的value都是一个值NULL。hashset
5、Zset 有序列表
一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以为每个 value 赋予一个 score 值,用来代表排序的权重。
ziplist(当数据数量小于128,每个数据的大小都小于64字节),skiplist

图片来源:redis zset底层实现原理 - YF-海纳百川 - 博客园
skiplist: 跳跃表(skipList)是一种随机化的数据结构,基于并联的链表,实现简单,插入、删除、查找的复杂度均为O(logN)。
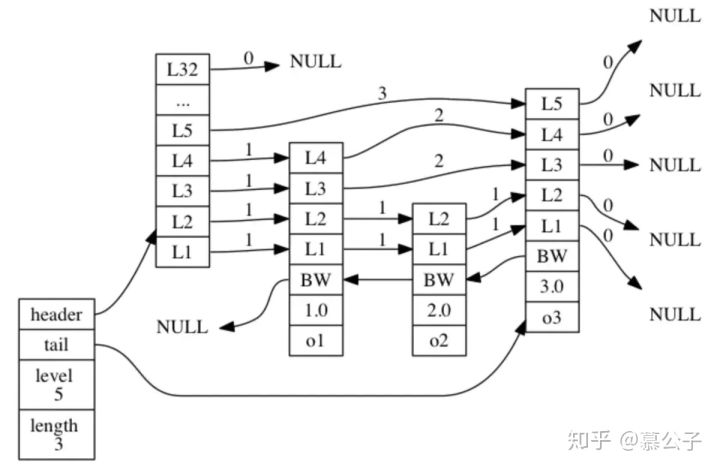
- 每个节点上都保存了一个用于指向其后节点的指针数组(即前文所述);
- 设置一个指向前一个节点的指针(方便逆向获取数据,如
zrevrank、zrevrange); - 创建了一个length和一个level属性用于快速查询跳表的节点数目和指针数组的最大长度;
- 节点中还会保存前向指针跳过的节点数span,可以用于分页。
- 最大32层指针,是因为生成指针的期望是1/4,所以2^32个节点中,才会有一个32层指针的节点,32层完全够用。

















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









