







- 前缀树
- 名称:Trie、字典树、查找树
- 特点:查找效率高,消耗内存大
- 应用:字符串检索、词频统计、字符串排序等
- 敏感词过滤器
- 定义前缀树
- 根据敏感词,初始化前缀树
- 编写过滤敏感词的方法
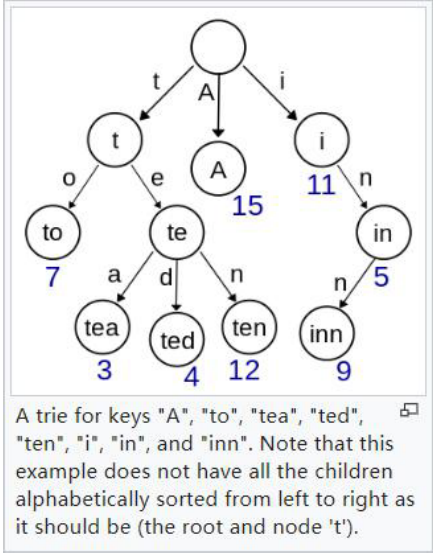
前缀树示例
-
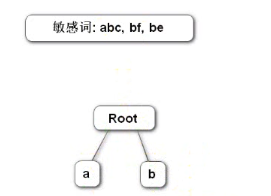
假设3个敏感词,abc、bf、be,画出根节点,从敏感词中分析出第一层
2.继续分析后续字母,每一层对应敏感词第几个字母
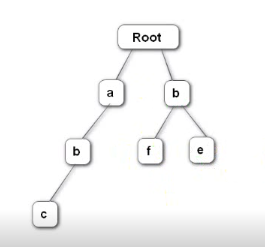
3.遍历到中途的时候不是敏感词,到最底层才是,比如ab不是,abc才是,在最底层做一个标记
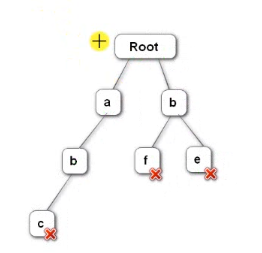
4.双指针检测,第一个指针判断是否是敏感词开头,如果是,移动第二个指针往下查。
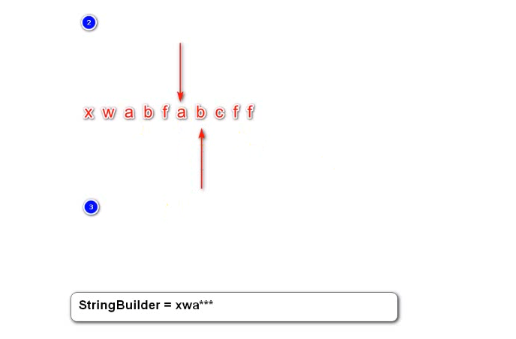
敏感词实现
敏感词我们存在文件里,在resource目录下新建sensitive-words.txt,随意写几个敏感词
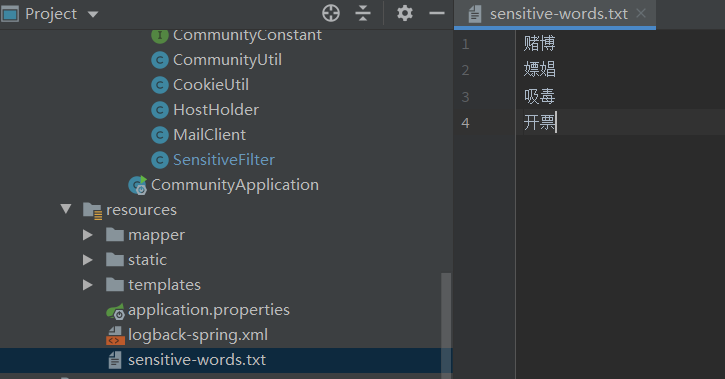
敏感词过滤作为一个工具类,在util包下新建SensitiveFilter。使用@Component注解交给容器管理。定义好日志记录和敏感词替换的内容。
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
//替换符
private static String REPLACEMENT = "***";
}
前缀树,树结构通常定义成节点,在SensitiveFilter里定义一个内部类TrieNode。
//前缀树
private class TrieNode {
//关键词结束标识
private boolean isKeywordEnd = false;
//子节点(key是下级字符,value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
//添加子节点方法
public void addSubNode(Character key, TrieNode value) {
subNodes.put(key, value);
}
//获取子节点方法
public TrieNode getSubNode(Character key) {
return subNodes.get(key);
}
}
敏感词前缀树我们需要且只需要初始化一次,定义一个init方法,使用classLoader获取输入流,然后使用缓存字符流。一行一行的读取敏感词,将其添加到前缀树,添加到前缀树的方法定义为addKeyWord。
//根节点
private TrieNode root = new TrieNode();
@PostConstruct
public void init() {
try (InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader=new BufferedReader(new InputStreamReader(is));
) {
String keyword;
while ((keyword=reader.readLine())!=null){
//添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败:"+e.getMessage());
}
}
将读取到的敏感词传入方法中,新建一个tempNode作为指针,然后一个字符一个字符的添加。
首先在root的子结点中找敏感词中的第一个字符,如果找到,就用subNode指向它,没有就新建subNode,并添加到子节点中。然后将指针下移到subNode,如果遍历到最后一个字符就设置结束标识。
//将敏感词添加到前缀树当中
private void addKeyword(String keyword){
TrieNode tempNode=root;
for (int i=0;i<keyword.length();i++){
char c=keyword.charAt(i);
TrieNode subNode=tempNode.getSubNode(c);
if (subNode==null){
//初始化子节点
subNode=new TrieNode();
tempNode.addSubNode(c,subNode);
}
//指向子节点,进入下一轮循环
tempNode=subNode;
//设置结束标识
if (i==keyword.length()-1){
tempNode.setKeywordEnd(true);
}
}
}
然后写过滤敏感词的方法,这里有一个问题,有些用户会在敏感词中插入特殊字符来逃避检查。如果特殊字符是在检查的开头,我们不做处理,如果特殊字符在疑似敏感词中间,我们就要忽略掉这个特殊字符。
//判断是否为符号
private boolean isSymbol(Character c){
// 0x2E80-0x9FFF是东亚文字范围
return !CharUtils.isAsciiAlphanumeric(c) && (c<0x2E80||c>0x9FFF);
}
按照前面前缀树的逻辑,实现。三个指针,指针1指向前缀树,指针2、3指向需要过滤的字符串。
例如:“我要&开*票”
指针1指向前缀树的根节点,指针2、3指向“我”,判断不是特殊字符,也不是敏感词开头,指针2、3指向要,同理,然后指向“&”,这时指针1指向root节点,说明这个特殊字符不在敏感词中间,将它拼接到结果中。然后指针2、3指向“开”,发现是敏感词开头,指针3后移指向“*”,判断是特殊字符,且此时指针1不是指向root,所以忽略掉这个特殊字符,指针3指向“票”,发现这个节点有end标记,说明从开到票是一个敏感词。
/**
* 过滤敏感词
* @param text 待过滤文本
* @return 过滤后的文本
*/
public String filter(String text){
if (StringUtils.isBlank(text)){
return null;
}
//指针1
TrieNode tempNode=root;
//指针2
int begin=0;
//指针3
int position=0;
//结果
StringBuilder sb=new StringBuilder();
while (position<text.length()){
char c=text.charAt(position);
//跳过符号
if (isSymbol(c)){
//若指针1处于根节点,将此符号计入结果,让指针2向下走一步
if (tempNode==root){
sb.append(c);
begin++;
}
//无论符号在开头或中间,指针3都向下走一步
position++;
continue;
}
//检查下级节点
tempNode=tempNode.getSubNode(c);
if (tempNode==null){
//以begin开头的字符不是敏感词
sb.append(text.charAt(begin));
//进入下一个位置
position=++begin;
//重新指向根节点
tempNode=root;
}else if (tempNode.isKeywordEnd()){
//发现敏感词,将begin-position字符串替换掉
sb.append(REPLACEMENT);
begin=++position;
//重新指向根节点
tempNode=root;
}else {
//检查下一个字符
position++;
}
}
//将最后一批字符计入结果
sb.append(text.substring(begin));
return sb.toString();
}
package com.neu.langsam.community.util;
import org.apache.commons.lang3.CharUtils;
import org.apache.commons.lang3.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
//替换符
private static String REPLACEMENT = "***";
//根节点
private TrieNode root = new TrieNode();
@PostConstruct
public void init() {
try (InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader=new BufferedReader(new InputStreamReader(is));
) {
String keyword;
while ((keyword=reader.readLine())!=null){
//添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败:"+e.getMessage());
}
}
//将敏感词添加到前缀树当中
private void addKeyword(String keyword){
TrieNode tempNode=root;
for (int i=0;i<keyword.length();i++){
char c=keyword.charAt(i);
TrieNode subNode=tempNode.getSubNode(c);
if (subNode==null){
//初始化子节点
subNode=new TrieNode();
tempNode.addSubNode(c,subNode);
}
//指向子节点,进入下一轮循环
tempNode=subNode;
//设置结束标识
if (i==keyword.length()-1){
tempNode.setKeywordEnd(true);
}
}
}
/**
* 过滤敏感词
* @param text 待过滤文本
* @return 过滤后的文本
*/
public String filter(String text){
if (StringUtils.isBlank(text)){
return null;
}
//指针1
TrieNode tempNode=root;
//指针2
int begin=0;
//指针3
int position=0;
//结果
StringBuilder sb=new StringBuilder();
while (position<text.length()){
char c=text.charAt(position);
//跳过符号
if (isSymbol(c)){
//若指针1处于根节点,将此符号计入结果,让指针2向下走一步
if (tempNode==root){
sb.append(c);
begin++;
}
//无论符号在开头或中间,指针3都向下走一步
position++;
continue;
}
//检查下级节点
tempNode=tempNode.getSubNode(c);
if (tempNode==null){
//以begin开头的字符不是敏感词
sb.append(text.charAt(begin));
//进入下一个位置
position=++begin;
//重新指向根节点
tempNode=root;
}else if (tempNode.isKeywordEnd()){
//发现敏感词,将begin-position字符串替换掉
sb.append(REPLACEMENT);
begin=++position;
//重新指向根节点
tempNode=root;
}else {
//检查下一个字符
position++;
}
}
//将最后一批字符计入结果
sb.append(text.substring(begin));
return sb.toString();
}
//判断是否为符号
private boolean isSymbol(Character c){
// 0x2E80-0x9FFF是东亚文字范围
return !CharUtils.isAsciiAlphanumeric(c) && (c<0x2E80||c>0x9FFF);
}
//前缀树
private class TrieNode {
//关键词结束标识
private boolean isKeywordEnd = false;
//子节点(key是下级字符,value是下级节点)
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
//添加子节点方法
public void addSubNode(Character key, TrieNode value) {
subNodes.put(key, value);
}
//获取子节点方法
public TrieNode getSubNode(Character key) {
return subNodes.get(key);
}
}
}
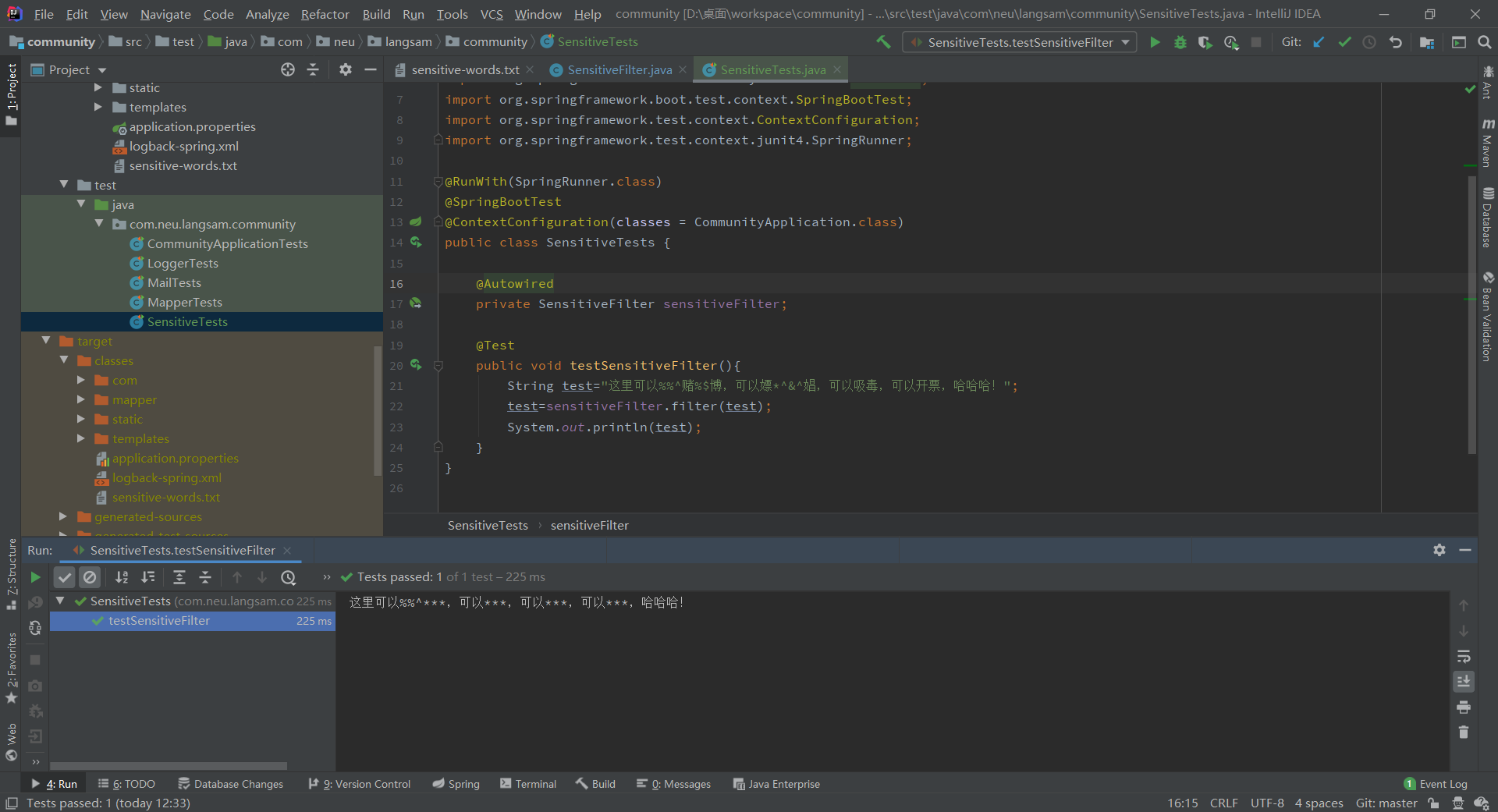
新建一个test看一下结果,发现结果正确。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









