




 本文介绍Python中使用urllib模块访问互联网的基本方法。通过导入urllib.request模块,可以轻松发送HTTP请求并获取响应。示例展示了如何读取网页内容,并将其从二进制格式解码为可读的文本。
本文介绍Python中使用urllib模块访问互联网的基本方法。通过导入urllib.request模块,可以轻松发送HTTP请求并获取响应。示例展示了如何读取网页内容,并将其从二进制格式解码为可读的文本。
Python 如何访问互联网?
Python把URL和lib组合成一个模块urllib在IDLE里面可以搜索:
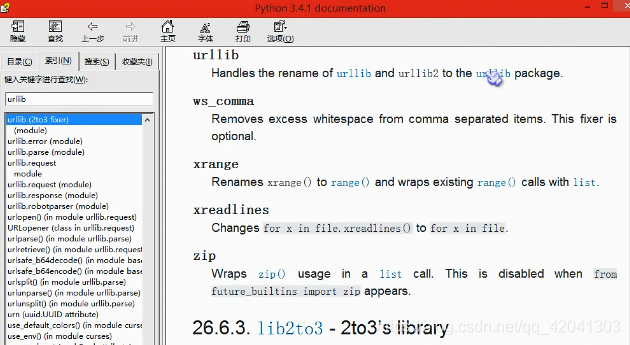
可以看到urllib有四个模块:
urllib.request,urllib.error,urllib.parse,urllib.robotparser
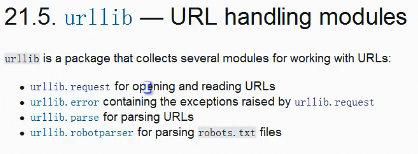
测试使用urllib.request模块:
>>> import urllib.request
>>> response = urllib.request.urlopen("http://www.fishC.com")
>>> html = response.read()
>>> print(html)
打印出来的网页内容是二进制代码,对其进行转码得到整齐的网页代码:
>>> html = html.decode("utf-8")
>>> print(html)

















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









