







摘要:
python相关内容,介绍了UnitTest包
Python + requests 接口自动化
Python + selenium web 自动化
Python + appium 移动端自动化(手机app)
一、介绍
python 是解释型语言,在执行的时候, 需要解释器⼀边解释(翻译)⼀边执行.
从上到下执行,下方代码出现的错误, 不会影响上方代码的执行.
format/f/F与字符串


运算符
/除
//取商
%取余
随机数
# 导入工具包
import random
# 产生随机数
random.randint(a,b) # 产生[a,b]之间随机数range
for i in range(n) # 此时范围[0,n)
for i in range(2,n) # 此时范围[2,n)下标
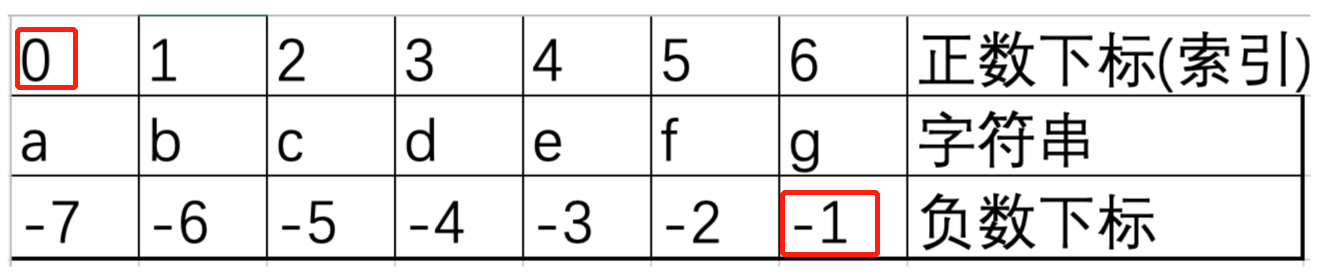
切片
# 语法 容器[start:end:step]
# start开始下标
# end结束位置的下标,其对应的值取不到
# step步长
my_str = 'abcdefg'
# 需求1 : 打印字符串中 abc 字符 start 0, end 3, step
print(my_str[0:3:1]) # abc
# 1.1 如果步长是 1, 可以省略不写
print(my_str[0:3]) # abc
# 1.2 如果 start 开始位置的下标为 0, 可以不写,但是冒号不能少
print(my_str[:3]) # abc
# 需求 2: 打印字符串中的 efg , start 4, end 7, step 1
print(my_str[4: 7]) # efg
# 2.1 如果取到最后一个字符, end 可以不写,但是冒号不能少
print(my_str[4:]) # efg
# 需求 3: 打印字符串中的 aceg , start 0, end 7(最后), 步长 2
print(my_str[::2]) # aceg
# 练习: cf
print(my_str[2:6:3])
# 特殊情况, 步长为 -1, 反转(逆序) 字符串
print(my_str[::-1]) # gfedcba字符串查找find()
字符串.find(sub_str) # 在字符串中 查找是否存在 sub_str 这样的字符串
返回值(这行代码执行的结果):
如果存在sub_str, 返回 第一次出现 sub_str 位置的下标
如果不存在sub_str, 返回 -1字符串替换replace()
字符串.replace(old, new, count) # 将字符串中的 old 字符串 替换为 new 字符串
- old 原字符串,被替换的字符串
- new 新字符串,要替换为的字符串
- count 一般不写,表示全部替换, 可以指定替换的次数
- 返回: 会返回一个替换后的完整的字符串
- 注意: 原字符串不会改变的
字符串拆分split()
字符串.split(sep) # 将字符串按照指定的字符串 sep 进行分隔
- sep , 按照 sep 分隔, 可以不写, 默认按照空白字符(空格 \t \n)分隔
返回: 列表,列表中的每个数据就是分隔后的字符串
字符串连接join()
字符串.join(容器) # 容器一般是列表 , 将字符串插入到列表相邻的两个数据之间,组成新的字符串
注意点: 列表中的数据 必须都是字符串才可以
list1 = ['hello', 'Python', 'and', 'itcast', 'and', 'itheima']
# 将 列表中数据使用 空格 组成新的字符串
str1 = ' '.join(list1)
print(str1) # hello Python and itcast and itheima
# 使用 逗号 连接
str2 = ','.join(list1)
print(str2) # hello,Python,and,itcast,and,itheima
# 使用 _*_ 连接
str3 = '_*_'.join(list1)
print(str3) # hello_*_Python_*_and_*_itcast_*_and_*_itheima列表
'''
index() 这个方法的作用和 字符串中的 find() 的作用是一样
列表中是没有 find() 方法的, 只有 index() 方法
字符串中 同时存在 find() 和 index() 方法
'''
列表.index(数据) #找到 返回下标 ;没有找到, 直接报错
列表.count(数据) # 统计 指定数据在列表中出现的次数
列表.append(数据) # 想列表的尾部添加数据
# 返回: None, 所以不用使用 变量 = 列表.append()
列表.pop(index) # 根据下标删除列表中的数据;
# index 下标可以不写, 默认删除在最后一个
# 返回, 删除的数据
# 列表 反转
列表 = 列表[::-1] 得到一个新的列表, 原列表不会改动
列表.reverse() 直接修改原列表的数据
# 排序
列表.sort() # 升序, 从小到大, 直接在原列表中进行排序
列表.sort(reverse=True) # 降序, 从大到下, 直接在原列表中进行排序元组
元组中的数据不能修改,列表中可以修改
因为元组中的数据不能修改,所以只能查询方法, 如 index, count ,支持下标和切片
定义只有一个数据的元组, 数据后必须有一个逗号
a = 10
b = 20
# c = b, a # 组包
# print(c) # (20, 10)
# a, b = c # 拆包 a(20) b(10)
# print(a, b)
a, b = b, a
print(a, b)
x, y, z = 'abc'
print(y) # b字典
# 删除
字典.pop('键')
# 查询 根据字典的 键, 获取对应的 值.
# 方法一:
字典['键'] # 键 不存在,会报错
# 方法 二
字典.get(键) # 键不存在,返回 None
# 遍历
# 遍历键
# 方式一
for 变量 in 字典:
print(变量)
# 方式二
for 变量 in 字典.keys(): # 字典.keys() 可以获取字典所有的键
print(变量)
# 遍历值
for 变量 in 字典.values(): # 字典.values() 可以获取字典中是所有的值
print(变量)
# 遍历键和值
# 变量1 就是 键, 变量2 就是值
for 变量1, 变量2 in 字典.items(): # 字典.items() 获取的是字典的键值对
print(变量1, 变量2)变量
定义变量的时候, 变量和数据 都会在内存开辟空间
变量所对应的内存空间中存储的是 数据所在内存的地址 (平时理解为 将数据存储到变量中即可)
变量中保存数据的地址,就称为是引用
Python 中所有数据的传递,传递的都是引用(即地址)
赋值运算符(=), 会改变变量的引用, 即只有 = 可以修改变量的引用
可以使用 id(变量) 函数,查看变量的引用
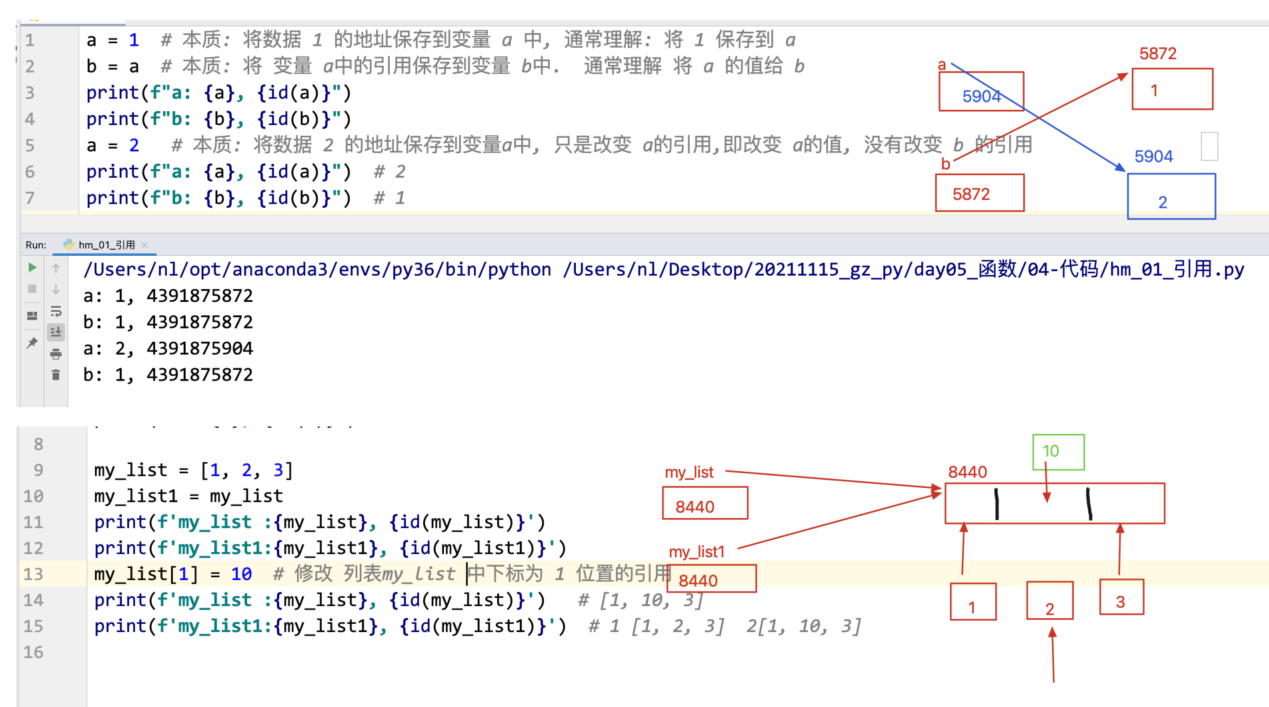

可变类型与不可变类型
根据内存中的数据是否允许修改,将数据类型分为可变类型与不可变类型
简单理解: 不使用等号,能不能修改数据值
可变类型: 可以修改
- 列表(list) list.append()
- 字典(dict ) dict.pop()
- 集合(set)
不可变类型: 不允许修改
- 数字类型(int , float , bool)
- 字符串(str)
- 元组(tuple)
多值参数
在普通的参数前边加上一个 *, 这个参数就变为 多值参数
这个形参一般写作 args(arguments), 即 *args
def func(*args):
print(args)
func() # ()
func(1, 2, 3) # (1, 2, 3)匿名函数
匿名函数: 使用 lambda 关键字 定义的表达式,称为匿名函数
lambda 参数, 参数: 一行代码 # 只能实现简单的功能,只能写一行代码
# 匿名函数 一般不直接调用, 作为函数的参数使用的
# 1, 定义匿名函数, 参数为两个整数数字, 求两个数字的乘积
lambda a, b: a * b
# 2, 定义匿名函数, 参数为一个字典, 返回字典中 键为 age 的值
lambda x: x.get('age')
lambda x: x['age']
user_list = [
{'name': '张三', 'age': 22, 'title': '测试工程师'},
{'name': '李四', 'age': 24, 'title': '开发工程师'},
{'name': '王五', 'age': 21, 'title': '测试工程师'}
]
#user_list.sort() # 只能对数字,字符串排序
# 根据字典的 age 键 排序
# 想要对列表中的字典排序,需要 key 形参来指定根据字典中的什么键排序
# key 这个参数需要传递一个函数,使用匿名函数
# 列表.sort(key=lambda x: x['键'])
def func(x):
return x['age']
user_list.sort(key=lambda x: x['age'])
# user_list.sort(key=func)
print(user_list)bool与数字
# bool 类型: True 就是 1, False 0
# 数字作为 bool 类型: 0 是 False, ⾮ 0 是 True
a = [1, True, 2]
a.count(1) # 2
if a[-1]: # True
print(True)
else:
print(False)二、面向对象
面向对象(oop) 是⼀种编程方法, 编程思想(即指导如何写代码), 适用于 中大型项目
面向过程也是⼀种编程思想, 适用于小型项目
面向过程 和 面向对象 都可以实现某个编程的目的.
面向过程 考虑的是 实现的细节
面向对象 考虑的是 结果(谁能做这件事)
类的构成
类名、属性、方法
代码步骤
设计类、定义类、创建对象(实例化对象)、由对象调用类中的方法
self参数
参函数的语法上来看, self 是形参, 名字可以任意的变量名, 只是我们习惯性叫 self
特殊点: self 是⼀个普通的参数, 按照函数的语法,在调用的时候,必须传递实参值, 原因, 是 Python 解释器自动的将调用这个方法的对象作为参数传递给 self。所以 self 就是调用这个方法对象。
class Cat:
def eat(self): # self 是调⽤这个⽅法的对象
"""吃⻥的⽅法"""
print(f'self:{id(self)}')
print('⼩猫爱吃⻥...')
# 创建对象
tom = Cat()
# 通过对象 调⽤类中的⽅法
print(f"tom :{id(tom)}")
tom.eat() # tom 调⽤ ,self 就是 tom
blue_cat = Cat()
print(f'blue:{id(blue_cat)}')
blue_cat.eat() # blue_cat 调⽤, self 就是 blue_cat自动调用方法
__init__方法:
调用时机
在创建对象之后,会自动调用.
应用场景
初始化对象, 给对象添加属性
注意事项
- 不要写错
- 如果属性是会变化的, 则可以将这个属性的值作为参数传递, 在创建对象的时候,必须传递实参值
class Cat:
def __init__(self, name):
self.name = name
def eat(self):
print(f"{self.name} 爱吃⻥")
blue_cat = Cat('蓝猫') # 初始化函数被调用
blue_cat.eat() # 蓝猫爱吃鱼
black_cat = Cat('⿊猫') # 初始化函数被调用
black_cat.eat() # 黑猫爱吃鱼__str__方法:
调用时机
使用print(对象) 打印对象的时候, 会自动调用
1, 如果没有定义 __str__ 方法, 默认打印的是 对象的引用地址
2, 如果定义 __str__ ,方法打印的是 方法的返回值
应用场景
使用 print(对象) 打印输出对象的属性信息
注意事项
必须返回一个 字符串
class Cat:
def __init__(self, name, age):
self.name = name # 添加 name 属性
self.age = age # 添加 age 属性
def __str__(self): # ⼀般不使⽤ print,直接返回
return f"姓名: {self.name}, 年龄: {self.age}"
# 创建对象
tom = Cat('汤姆', 3)
print(tom) # 姓名: 汤姆, 年龄: 3
# ------------
class Cat:
def __init__(self, name, age):
self.name = name # 添加 name 属性
self.age = age # 添加 age 属性
# 创建对象
tom = Cat('汤姆', 3)
print(tom) # <__main__.Cat object at 0x000001E836894280>继承
# class 类A(object):
# class 类A():
class 类A: # 默认继承 object 类, object 类 Python 中最原始的类
pass
class 类B(类A): # 就是继承, 类 B 继承 类 A
pass
# 类 A: 父类 或 基类
# 类 B: 子类 或 派生类
#子类继承父类之后, 子类对象可以直接使用父类中的属性和方法继承具有传递性: C 继承 B, B 继承 A, C 可以使用 A 类中的属性和方法
对象调用方法的顺序: 对象.方法名()
会先在自己的类中查找, 找到直接使用
没有找到去父类中查找, 找到直接使用
没有找到, 在父类的父类中查找, 找到直接使用
没有找到, ...
直到 object 类, 找到直接使用, 没有找到,报错
重写
重写是在子类中定义了和父类中名字一样的方法.
为什么重写:父类中的代码不能满足子类对象的需要
重写的方式:
覆盖式重写
扩展式重写
覆盖式重写
父类中的功能全部不要.
直接在子类中定义和父类中方法名字一样的方法接口, 直接书写新的代码.
class Dog:
def bark(self):
print('汪汪汪叫......')
class XTQ(Dog):
# 需要哮天犬 嗷嗷嗷叫, 父类中的 bark 方法,不能满足子类对象的需要, 覆盖式重写
def bark(self):
print('嗷嗷嗷叫.....')
if __name__ == '__main__':
xtq = XTQ()
xtq.bark() # 嗷嗷嗷叫.....扩展式重写
父类中的功能还需要,只是添加了新的功能
方法:
先在子类中定义和父类中名字相同的方法
在子类的代码中 使用 super().方法名() 调用父类中的功能
书写新的功能
class Dog:
def bark(self):
print('汪汪汪叫......')
class XTQ(Dog):
# 需要哮天犬 嗷嗷嗷叫, 父类中的 bark 方法,不能满足子类对象的需要, 覆盖式重写
def bark(self):
# 调用父类中的功能
super().bark()
print('嗷嗷嗷叫.....')
if __name__ == '__main__':
xtq = XTQ()
xtq.bark()
'''
汪汪汪叫......
嗷嗷嗷叫.....
'''多态
不同的子类对象调用相同的方法,产生不同的执行结果
class Dog:
def game(self):
print('普通狗简单的玩耍...')
class XTQ(Dog):
def game(self):
print('哮天犬在天上玩耍...')
class Person:
def play_with_dog(self, dog):
"""dog 是狗类或者其子类的对象"""
print('人和狗在玩耍...', end='')
dog.game()
if __name__ == '__main__':
dog1 = Dog()
xtq = XTQ()
xw = Person()
xw.play_with_dog(dog1)
xw.play_with_dog(xtq)
'''
人和狗在玩耍...普通狗简单的玩耍...
人和狗在玩耍...哮天犬在天上玩耍...
'''私有和公有
公有:
直接定义的属性和方法就是公有的
可以在任何地方访问和使用, 只要有对象就可以访问和使用
私有:
只能在类内部定义(class 关键字的缩进中)
只需要在属性名或者方法名前边加上两个下划线, 这个方法或者属性就变为私有的
私有只能在当前类的内部使用. 不能在类外部和子类直接使用
应用场景
一般来说,定义的属性和方法 都为公有的.
某个属性 不想在外部直接使用, 定义为私有
某个方法,是内部的方法(不想在外部使用), 定义为私有
"""定义人类, name 属性 age 属性(私有)"""
class Person:
def __init__(self, name, age):
self.name = name # 公有
self.__age = age # 公有-->私有, 在属性名前加上两个下划线
def __str__(self): # 公有方法
return f"{self.name}, {self.__age}"
def set_age(self, age): # 定义公有方法,修改私有属性
if age < 0 or age > 120:
print('提供的年龄信息不对')
return
self.__age = age
if __name__ == '__main__':
xw = Person('小王', 18)
print(xw)
xw.__age = 10000 # 添加一个公有属性 __age
print(xw)
xw.set_age(10000)
print(xw)
'''
小王, 18
小王, 18
提供的年龄信息不对
小王, 18
'''属性
属性:类的属性、实例的属性
class Tool:
# 定义类属性 count,记录创建对象的个数
count = 0
def __init__(self, name):
self.name = name # 实例属性, 工具的名字
# 修改类属性的值
Tool.count += 1
if __name__ == '__main__':
# 查看 创建对象的个数
print(Tool.count) # 查看类属性 0
tool1 = Tool('锤子')
print(Tool.count) # 1
tool2 = Tool('扳手')
print(Tool.count) # 2
print(tool2.count) # 先找实例属性 count, 找不到, 找类属性 count, 找到,使用 2方法
实例方法、类方法
# 直接定义的方法就是实例方法
class 类名:
def 方法名(self):
pass
# 调用
实例对象.方法名()# 定义类方法,需要在方法名上方 书写 @classmethod , 即使用 @classmethod 装饰器装饰
class 类名:
@classmethod
def 方法名(cls): # cls, 表示类对象, 即 类名, 同样不需要手动传递
pass
# 调用
# 方法一
类名.方法名()
# 方法二
实例对象.方法名()静态方法
方法中即不需要使用 实例属性, 也不需要使用 类属性, 可以将这个方法定义为 静态方法
# 定义静态方法, 需要使用 装饰器 @staticmethod 装饰方法
class 类名:
@staticmethod
def 方法名():
pass
# 调用
# 方法一
类名.方法名()
# 方法二
实例对象.方法名()三、文件操作
分类:
文本文件
可以使用记事本软件打开
txt, py, md, json
二进制文件
不能使用 记事本软件打开
音频文件 mp3
视频文件 mp4 ....
图片 png, jpg, gif, exe
打开文件open()
# 打开文件
open(file, mode='r', encoding=None) # 将硬盘中的文件 加载到内存中
'''
- file: 表示要操作的文件的名字,可以使用相对路径 和绝对路径
- 绝对路径, 从根目录开始书写的路径 C:/ D:/
- 相对路径, 从当前目录开始书写的路径 ./ ../
- mode: 打开文件的方式
- r , 只读打开 read, 如果文件不存在,会报错
- w , 只写打开, write, 如果文件存在, 会覆盖原文件
- a , 追加打开, append, 在文件的末尾写入新的内容
- encoding: 编码格式, 指 二进制数据 和 汉字 转换的规则的
- utf-8(常用) : 将一个汉字转换为 3 个字节的二进制
- gbk: 将一个汉字转换为 2 个字节的二进制
返回值: 文件对象, 后续对文件的操作, 都需要这个文件对象
'''关闭文件close()
如果是写文件, 会自动保存, 即将内存中的数据同步到硬盘中
读文件read()
变量 = 文件对象.read()
# 返回值: 返回读取到文件内容, 类型是字符串
# with open('a.txt', encoding='utf-8') as f:
# buf = f.read()
# print(buf)
f = open('a.txt', encoding='utf-8')
data = f.read()
print(data)
f.close()写文件write()
文件对象.write()
# 参数: 写入文件的内容, 类型 字符串
# 返回值: 写入文件中的字符数, 字符串的长度, 一般不关注
# 1, 打开文件
f = open('a.txt', 'w', encoding='utf-8')
# 2, 写文件
f.write('好好学习\n天天向上')
# 3, 关闭文件
f.close()文件打开的另一种方式(推荐)
with open(file, mode, encoding) as 变量: # 变量 就是文件对象
pass
# 使用这种写法打开文件, 会自动进行关闭,不用手动书写关闭的代码
# 出了 with 的缩进之后, 文件就会自动关闭
with open('a.txt', 'a', encoding='utf-8') as f:
f.write('good good study\n')按行读取文件readline()
文件对象.readline() # ⼀次读取一行的内容, 返回读取到的内容
read() 和 readline() 如果读到文件末尾, 返回的都是 空字符串
with open('a.txt', encoding='utf-8') as f:
buf = f.readline()
print(buf) # aaaaaa
buf1 = f.readline()
print(buf1) # bbbbbb
# 读大文件
with open('a.txt', encoding='utf-8') as f:
while True:
buf = f.readline() # ⽂件读完了,返回 空字符串
if buf: # 空字符串 是 False, ⾮空字符串是True
print(buf, end='')
else:
break打开文件方式
r w a 称为是文本方式打开, 适用于文本文件, 会对二进制进行编码转换
rb wb ab 称为是二进制方式打开, 可以打开文本文件和二进制文件, 但是二进制文件只能使用二进制方式打开,同时,不能传递 encoding 参数
四、json文件
本质也是文本文件,可以用read 和write进行操作
是一种基于文本,独立于语言的轻量级数据交换格式
读取json文件
import json
with open('info.json', encoding='utf-8') as f:
buf = json.load(f) # 列表/字典
print(type(buf))
print(buf)
# 姓名
print(buf.get('name'))
# 城市
print(buf.get('address').get('city'))写入
import json
info = {'name': '⼩明', 'age': 18}
with open('info3.json', 'w', encoding='utf-8') as f:
# json.dump(info, f)
# json.dump(info, f, ensure_ascii=False) # 直接显示中⽂
json.dump(info, f, ensure_ascii=False, indent=2) # 直接显示中⽂ indent缩进长度五、异常
捕获未知类型的异常
'''
try:
可能发⽣异常的代码
except Exception as 变量: # Exception 常⻅异常类的⽗类, 变量 异常对象
print()# 可以打印异常信息发⽣异常执⾏的代码
'''
try:
num = int(input('请输⼊⼀个整数数字:'))
num1 = 8 / num
print(num1)
except Exception as e:
print(f'发⽣了异常, {e}') 完整结构
try:
# 可能发⽣异常的代码
except 异常类型:
# 发⽣了指定类型的异常执⾏的代码
except Exception as e:
# 发⽣了其他类型的异常执⾏的代码
else:
# 没有发⽣异常,会执⾏的代码
finally:
# 不管有没有发⽣异常,都会执⾏的代码异常传递
在函数的嵌套调用过程中,如果发生了异常,没有进行捕获,会将这个异常传递到函数调用的地方, 直到被捕获为止, 如果一直没有捕获,才会报错,终止执行
抛出异常
在执行代码的过程中,之所以会发生异常,终止代码执行,是因为代码执行遇到了raise 关键字
六、Unittest框架
自动化测试中使用
使用原因:
能够组织多个用例去执行
提供丰富的断言方法
可以生成测试报告
核心要素
TestCase 测试用例, 这个测试用例是 unittest 的组成部分,作用是用来书写真正的用例代码(脚本)
Testsuite 测试套件, 作用是用来组装(打包)TestCase(测试用例) 的,即 可以将多个用例脚本文件组装到一起
TestRunner 测试执行(测试运行), 作用是用例执行TestSuite(测试套件)的
TestLoader 测试加载, 是对 TestSuite(测试套件) 功能的补充, 作用是用来组装(打包) TestCase(测试用例) 的
Fixture 测试夹具, 是一种代码结构, 书写前置方法(执行用例之前的方法)代码和后置方法(执行用例之后的方法) 代码 ,即用例执行顺序:前置 --->用例 ---> 后置
TestCase
书写用例代码
注意:代码文件名要满足标识符规则;不要使用中文
需要继承unittest.TestCase类
# 1. 导包 unittest
import unittest
# 2. 定义测试类, 只要继承 unittest.TestCase 类, 就是 测试类
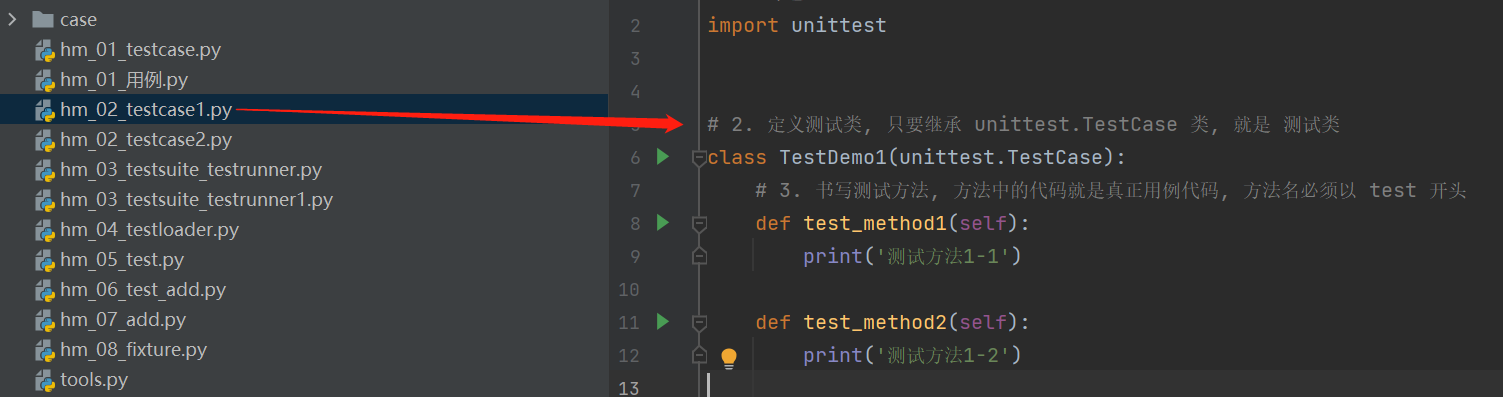
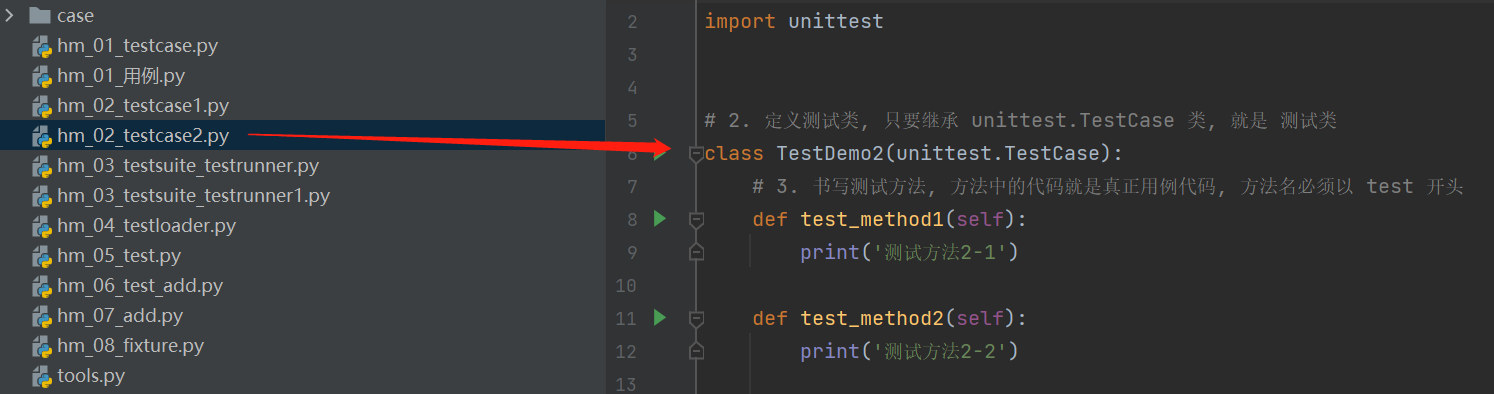
class TestDemo(unittest.TestCase):
# 3. 书写测试方法, 方法中的代码就是真正用例代码, 方法名必须以 test 开头
def test_method1(self):
print('测试方法一')
def test_method2(self):
print('测试方法二')
# 4. 执行
# 4.1 在类名或者方法名后边右键运行
# 4.1.1 在类名后边, 执行类中的所有的测试方法
# 4.1.2 在方法名后边, 只执行当前的测试方法
# 4.2 在主程序使用使用 unittest.main() 来执行,
if __name__ == '__main__':
unittest.main()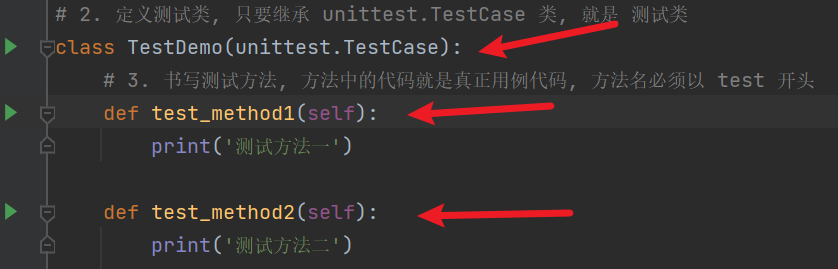
常见错误:
文件名包含中文,右键可能会无法执行
解决方案一:新建一个不含中文的文件
方法二:使用在主程序中运行 unittest.main()执行
方法三:
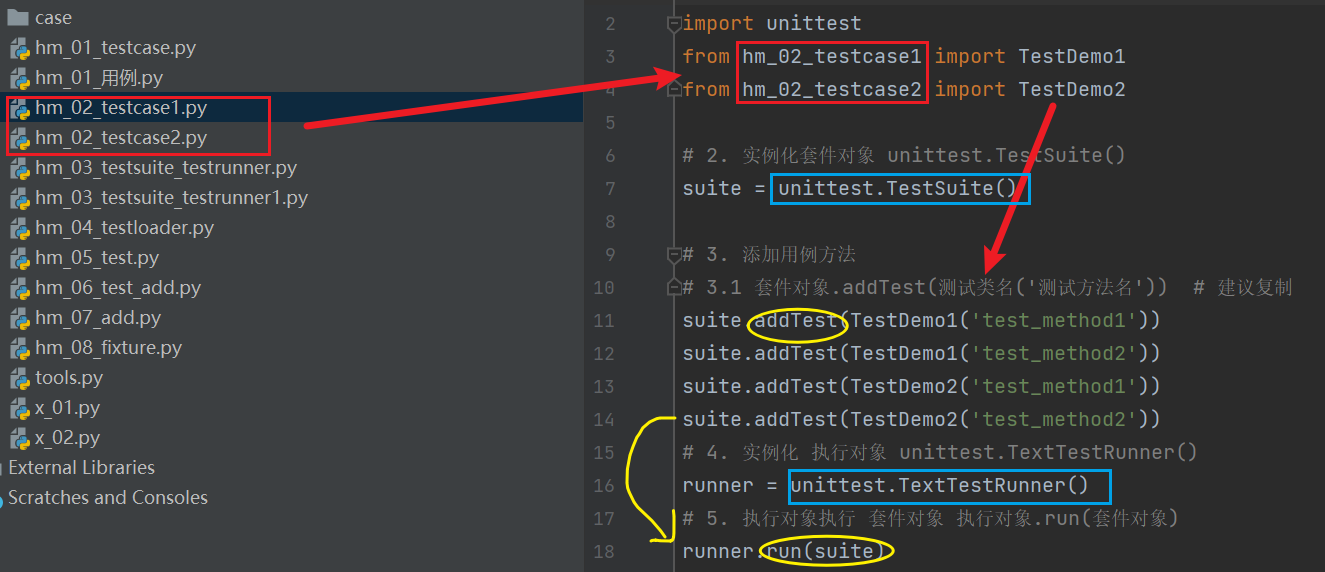
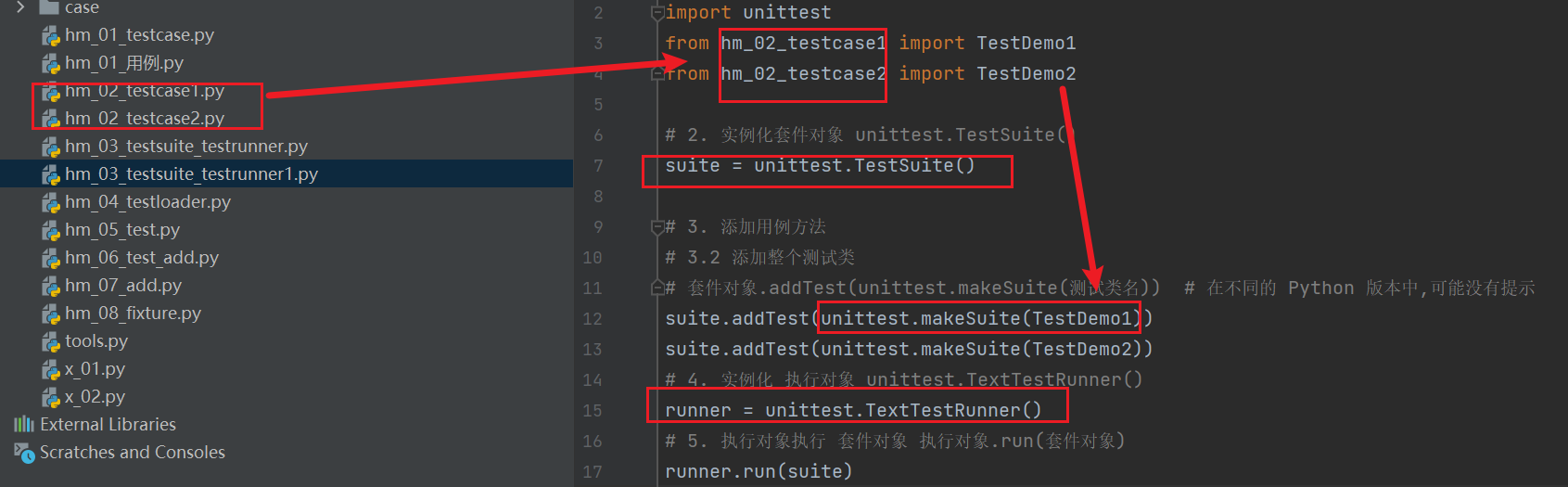
TestSuite和TestRunner
TestSuite(测试套件):将多个用例脚本组合在一起,组装用例
addTest(测试类名('测试方法名'))
addTest(unittest.makeSuite(测试类名))
先实例->添加用例addTest(测试类名('测试方法名'))->执行run
或者addTest(unittest.makeSuite(测试类名))
查看执行结果

TestLoader
测试加载,和TestSuite作用一样,也需要TestRunner来执行
加载更方便
unittest.TestLoader().discover(目录,文件名)
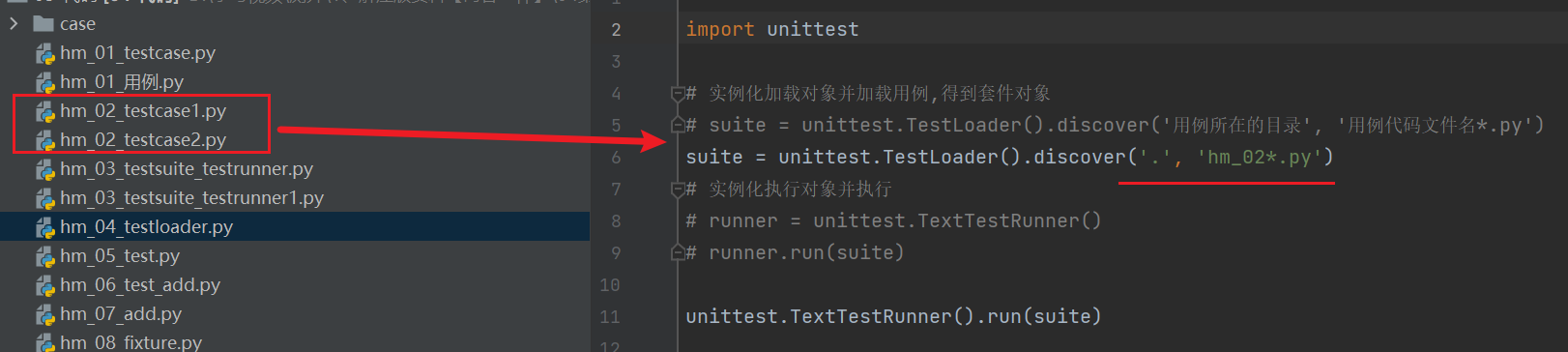
练习
定义一个tools模块,在其中定义一个方法add返回两个数的和
书写用例对add测试:1,1,2;1,2,3;3,4,7;4,5,9...
tools.py
def add(a,b):
return a+btest_case_add.py
import unittest
class TestAdd(unittest.TestCase):
def test_1(self):
if 2 == add(1,1):
print(f'用例{1},{1},{2}通过')
else:
print(f'用例{1},{1},{2}不通过')
def test_2(self):
if 3 == add(1, 2):
print(f'用例 {1}, {2}, {3}通过')
else:
print(f'用例 {1}, {2}, {3}不通过')
def test_3(self):
if 7 == add(3, 4):
print(f'用例 {3}, {4}, {7}通过')
else:
print(f'用例 {3}, {4}, {7}不通过')
def test_4(self):
if 9 == add(4, 5):
print(f'用例 {4}, {5}, {9}通过')
else:
print(f'用例 {4}, {5}, {9}不通过')
test_suite_add.py
import unittest
from test_case_add import TestAdd
suite = unittest.TestSuite() # 实例
suite.addTest(unittest.makeSuite(TestAdd)) # 套件
unittest.TextTestRunner().run(suite) # 运行Fixture
web测试时:
打开浏览器(一次)
打开网页点击登录(每次)
输入用户密码验证码,点击登录(每次,测试方法)
关闭页面(每次)
打开网页点击登录(每次)
输入用户密码验证码,点击登录(每次,测试方法)
关闭页面(每次)
关闭浏览器(一次)
方法级别Fixture
在每个用例执行前后都会自动调用,方法名是固定的
# 前置
def setUp(self):
pass
# 后置
def tearDown(self):
pass
类级别Fixture
在类中所有测试方法前后 会自动调用,只执行一次
@classmethod
def setUpClass(cls):
pass
@classmethod
def tearDownClass(cls):
pass模块级别Fixture
在代码文件执行前后执行一次,在类外部定义函数
def setUpModule():
pass练习
import unittest
class TestLogin(unittest.TestCase):
# 每次用例前
def setUp(self) -> None:
print('2. 打开网页, 点击登录')
# 每次用例后
def tearDown(self) -> None:
print('4. 关闭网页')
# 用例前一次
@classmethod
def setUpClass(cls) -> None:
print('1. 打开浏览器')
# 用例后一次
@classmethod
def tearDownClass(cls) -> None:
print('5. 关闭浏览器')
# 测试用例
def test_1(self):
print('3. 输入用户名密码验证码1,点击登录 ')
def test_2(self):
print('3. 输入用户名密码验证码2,点击登录 ')
def test_3(self):
print('3. 输入用户名密码验证码3,点击登录 ')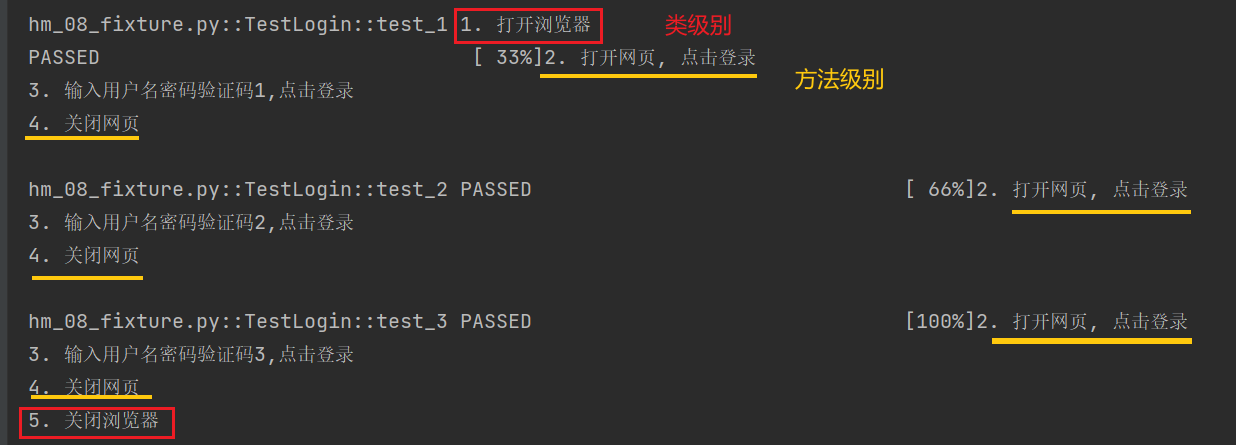
完成对 login 函数的测试

Login.py
def login(username, password):
if username == 'admin' and password == '123456':
return '登陆成功'
else:
return '登录失败'case_Login.py
import unittest
from Login import login
class TestLogin(unittest.TestCase):
# 书写用例
def test_username_password_ok(self):
# 正确的用户名和密码
if login('admin', '123456') == '登陆成功':
print("用例通过")
else:
print("用例不通过")
def test_username_error(self):
# 错误的用户名
if login('root', '123456') == '登陆失败':
print("用例通过")
else:
print("用例不通过")
def test_password_error(self):
# 错误的密码
if login('admin', '123123') == '登陆失败':
print("用例通过")
else:
print("用例不通过")
def test_username_password_error(self):
# 错误的用户名和密码
if login('aaa', '123123') == '登陆失败':
print("用例通过")
else:
print("用例不通过")case_Login_suite.py
import unittest
from case_login import TestLogin
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestLogin))
unittest.TextTestRunner().run(suite)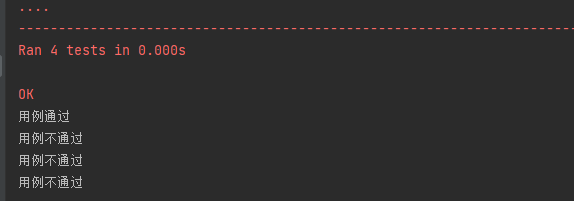
断言
使用代码自动的判断预期结果和实际结果是否相符
提高测试效率;实现自动化测试
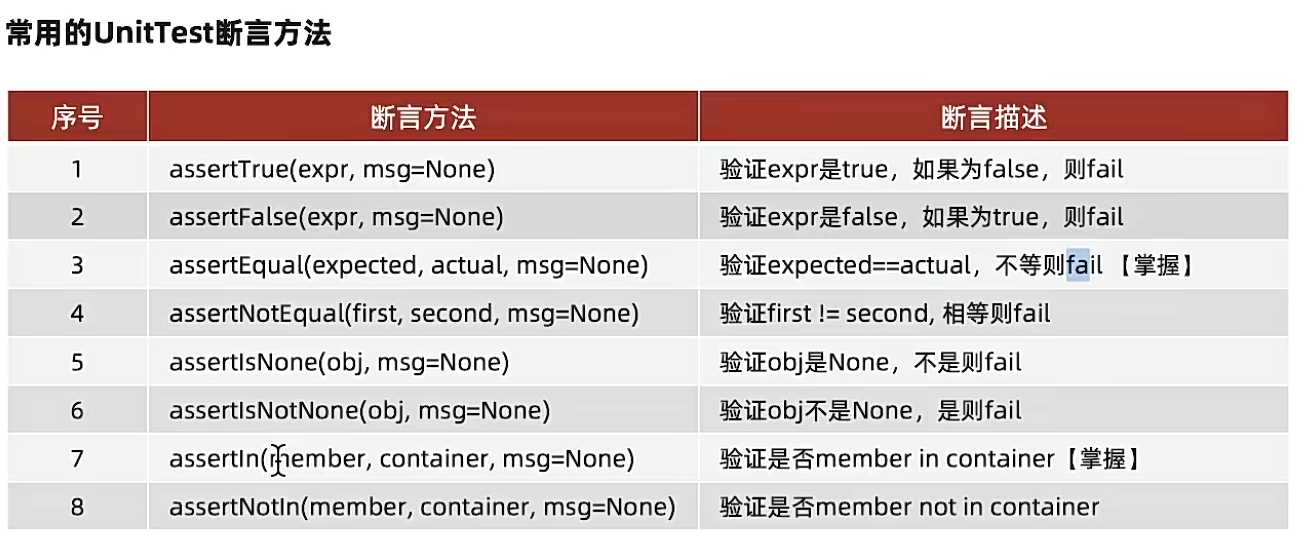
常用断言方法
import unittest
class TestAssert(unittest.TestCase):
# 判断预期结果和实际结果是否相等,如果相等,用例通过,如果不相等,抛出异常,用例不通过
def test_equal_1(self):
self.assertEqual(10, 10) # 用例通过
def test_assert_2(self):
self.assertEqual(10, 11) # 用例不通过
def test_in(self):
# self.assertIn('admin', '欢迎 admin 登录') # 包含 通过
# self.assertIn('admin', '欢迎 adminnnnnnnn 登录') # 包含 通过
# self.assertIn('admin', '欢迎 aaaaaadminnnnnnnn 登录') # 包含 通过
# self.assertIn('admin', '欢迎 adddddmin 登录') # 不包含 不通过
# 判断预期结果是否包含在实际结果中,如果存在,用例通过,如果不存在,抛出异常,用例不通过
self.assertIn('admin', 'admin') # 包含 通过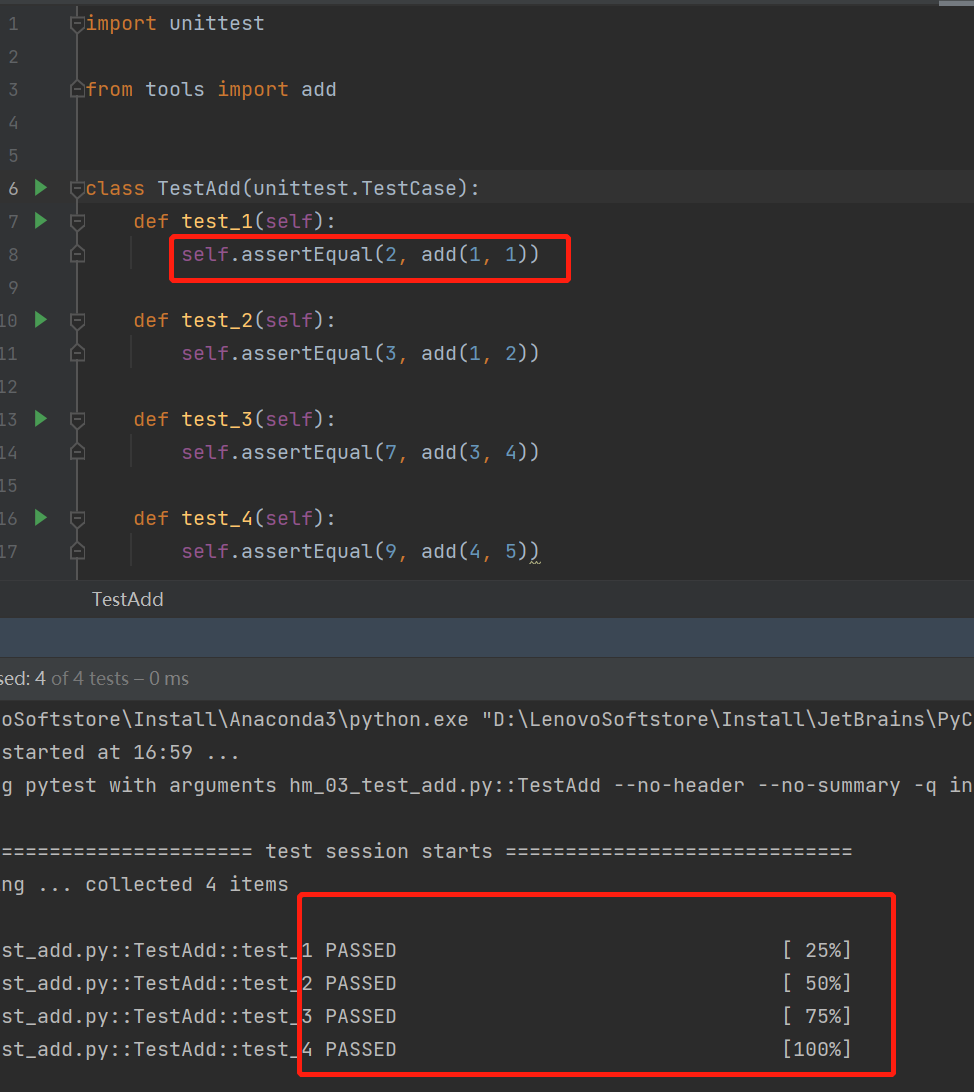
参数化
通过参数的方式来传递数据,从而实现数据和脚本分离。并且可以实现用例的重复执行。(在书写用例方法的时候,测试数据使用变量代替,在执行的时候进行据说传递)
unittest 测试框架,本身不支持参数化,但是可以通过安装unittest扩展插件 parameterized 来实现。
数据格式[(...), (...), (...), (...)]
装饰器@parameterized.expand(数据)
import unittest
from tools import add # 验证求和这个方法
from parameterized import parameterized
data = [(1, 1, 2), (1, 2, 3), (2, 3, 5), (4, 5, 9)] # 测试数据
class TestAdd(unittest.TestCase):
@parameterized.expand(data)
def test_add(self, a, b, expect):
print(f'a:{a}, b:{b}, expect:{expect}')
self.assertEqual(expect, add(a, b))
if __name__ == '__main__':
unittest.main()
练习

test_read.py
# 读取json文件
import json
def build_add_data():
with open('./data/data.json') as f:
data = json.load(f) # [[], [], []] ---> [(), ()]
return datatools.py
def add(a,b):
return a+btest_case_add.py
import unittest
from tools import add
from parameterized import parameterized
from test_read import build_add_data # 获取json文件数据
class TestAdd(unittest.TestCase):
@parameterized.expand(build_add_data())
def test_add(self,a,b,expect):
print(f'a:{a},b:{b},expect:{expect}')
self.assertEqual(expect,add(a,b))
if __name__ == '__main__':
unittest.main()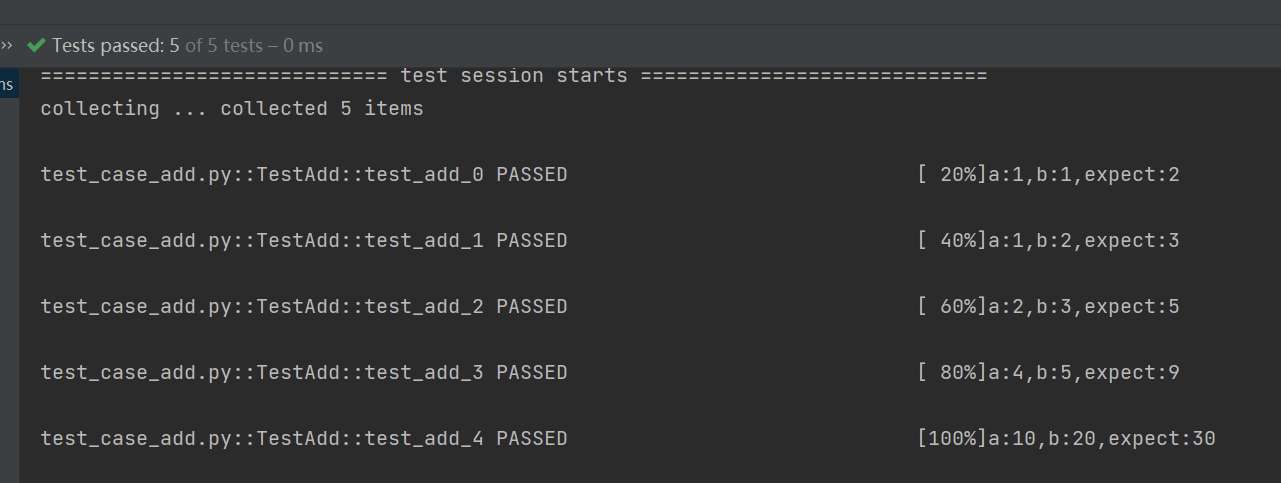
json文件
[
{
"a": 1,
"b": 2,
"expect": 3
},
{
"a": 11,
"b": 22,
"expect": 33
},
{
"a": 12,
"b": 23,
"expect": 35
},
{
"a": 14,
"b": 25,
"expect": 39
}
]读取文件
def build_add_data_1():
with open('../data/add_data_1.json') as f:
data_list = json.load(f) # [{}, {}, {}] ----> [(), ()]
# 改格式
new_list = []
for data in data_list: # data 字典
# 字典中的值,是否都需要
a = data.get('a')
b = data.get('b')
expect = data.get('expect')
new_list.append((a, b, expect))
# 或者直接new_list.append(tuple(data.values()))
return new_list七、测试报告
生成HTML测试报告,使用HTMLTestReport类库,本质是 TestRunner
import unittest
from htmltestreport import HTMLTestReport
from hm_04_pa1 import TestAdd
# 套件
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestAdd))
# 运行对象
# runner = HTMLTestReport(报告的文件路径后缀.html, 报告的标题, 其他的描述信息)
runner = HTMLTestReport('test_add_report.html', '加法用例测试报告', 'xxx')
runner.run(suite)绝对路径
获取当前文件绝对路径;__file__ 特殊的变量,表示当前代码文件名
os.path.abspath()
os.path.dirname()
import os
# __file__ 特殊的变量,表示当前代码文件名
# 获取当前文件绝对路径
path1 = os.path.abspath(__file__)
print(path1)
# 获取文件路径的目录名称
path2 = os.path.dirname(path1)
print(path2)
# BASE_DIR = os.path.dirname(os.path.abspath(__file__))
BASE_DIR = os.path.dirname(__file__)
if __name__ == '__main__':
print(BASE_DIR)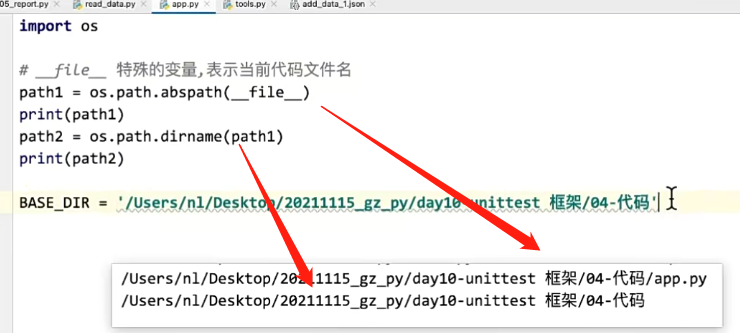
练习

[
{
"desc": "正确的用户名和密码",
"username": "admin",
"password": "123456",
"expect": "登录成功"
},
{
"desc": "错误的用户名",
"username": "root",
"password": "123456",
"expect": "登录失败"
},
{
"desc": "错误的密码",
"username": "admin",
"password": "123123",
"expect": "登录失败"
},
{
"desc": "错误的用户名和密码",
"username": "root",
"password": "123123",
"expect": "登录失败"
}
]登录Login.py
def login(username, password):
if username == 'admin' and password == '123456':
return '登录成功'
else:
return '登录失败'读取文件 login_data_load.py
import json
def LoginLoad():
with open('./data/data.json', encoding='utf-8') as f:
data = json.load(f)
new_data = []
for d in data:
username = d.get('username') # 字典读值
password = d.get('password')
expect = d.get('expect')
new_data.append((username, password, expect))
return new_data
测试用例test_case_login.py
import unittest
from parameterized import parameterized # 参数化
from Login import login # 导入登录模块
from login_data_load import LoginLoad # 加载数据
class TestLogin(unittest.TestCase):
@parameterized.expand(LoginLoad())
def test_login(self, username, password, expect):
print(f'username: {username}, password: {password}, expect: {expect}')
self.assertEqual(expect, login(username, password))
运行用例输出报告 test_login_report.py
import unittest
from htmltestreport import HTMLTestReport
from test_case_login import TestLogin
# 实例化套件
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(TestLogin))
# 执行,输出报告
runner = HTMLTestReport('test_login_report.html', '登录用例测试报告', 'xxx')
runner.run(suite)八、跳过
对于一些未完成的或者不满足测试条件的测试函数和测试类,可以跳过执行(简单来说, 不想执行的测试方法,可以设置为跳过)
两种方法:
直接跳过@unittest.skip('没什么原因,就是不想执行')
条件跳过@unittest.skipIf(条件判断,原因) # True 执行跳过
import unittest
version = 29
class TestSkip(unittest.TestCase):
@unittest.skip('没什么原因,就是不想执行')
def test_1(self):
print('方法一')
@unittest.skipIf(version >= 30, '版本号大于等于 30, 测方法不用执行')
def test_2(self):
print('方法二')
def test_3(self):
print('方法三')
if __name__ == '__main__':
unittest.main()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











