









 本文介绍了如何使用Python内置的urllib库进行在线翻译,详细讲解了urllib库的基本概念、HTTP请求以及urlopen方法的使用,包括data参数的设置,通过实例演示了如何发送POST请求获取翻译结果并解析。
本文介绍了如何使用Python内置的urllib库进行在线翻译,详细讲解了urllib库的基本概念、HTTP请求以及urlopen方法的使用,包括data参数的设置,通过实例演示了如何发送POST请求获取翻译结果并解析。
介绍
在写爬虫的我们一般使用 Scrapy 和PySpider。pyspider上手更简单,操作更加简便,因为它增加了 WEB 界面,写爬虫迅速,集成了phantomjs,可以用来抓取js渲染的页面。Scrapy自定义程度高,比 PySpider更底层一些,适合学习研究,需要学习的相关知识多,不过自己拿来研究分布式和多线程等等是非常合适的。*** 但是***我在这里所用的是python中***urllib***里的方法。
原因:
在装Scrapy,我们需要装python2.7的版本(因为还没有推出3以上的版本)python2和python3是两个独立的版本(因为python3是python2的大升级,以致python2写的程序python3有小部分运行不得)如果安装两个版本会涉及到优先级的问题,即对于.py文件打开用哪个打开(python2还是python3)
什么是urllib库:
Urllib是python内置的HTTP请求库
包括以下模块
urllib.request 请求模块
urllib.response 响应模块
urllib.error 异常处理模块
urllib.parse url 解析模块
urllib.robotparser 解析模块
使用哪些模块:
在个小程序中我们使用urllib.request 请求模块和urllib.parse url解析模块与json库这三个工具就够了
什么叫HTTP请求:
是指从客户端到服务器端的请求消息。包括:消息首行中,对资源的请求方法、资源的标识符及使用的协议。通俗来讲,我们需要访问网站而我们就是客户端,我们要访问的网站就是访问别人的服务器,也就是服务端。比如我进淘宝,我的电脑会发送信息给淘宝的服务器,告诉淘宝服务器,那么淘宝服务器将数据传输给我,我的浏览器将这些数据进行解释,这时候我们才能看到淘宝页面。类比: 这就好比我拜访朋友,我想去朋友家,先敲门(客户端发送信息给服务器),朋友听到敲门声(服务器收到客户端的请求),朋友打开门(服务器将信息传输给客户端)。因为朋友家有限,能招待的客人有限,服务器也是一样,如果遇到非人类恶意访问(用程序访问比如每秒访问几十次甚至更多),那么会恶意占用服务器内存,那么其他人就访问不了。试想一下如果双十一有人恶意访问淘宝,导致别人访问不了淘宝,按淘宝一秒上万的成交额来算,那么淘宝会损失多少钱,所以对于中大型企业的网站都有检测恶意访问 ip,发现后就将该 ip 拉黑,这个 ip 就无法访问被攻击公司的网站了。
首先我们通过urllib.request里urlopen方法发送请求
这是python官方的urllib.request的解释(引用的重点用斜体加粗表示)
The urllib.request module defines functions and classes which help in opening URLs (mostly HTTP) in a complex world — basic and digest authentication, redirections, cookies and more.
urlopen方法:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
urlopen参数详细介绍:
Open the URL url, which can be either a string or a Request object.
data must be an object specifying additional data to be sent to the server, or None if no such data is needed. See Request for details.
urllib.request module uses HTTP/1.1 and includes Connection:close header in its HTTP requests.
The optional timeout parameter specifies a timeout in seconds for blocking operations like the connection attempt (if not specified, the global default timeout setting will be used). This actually only works for HTTP, HTTPS and FTP connections.
If context is specified, it must be a ssl.SSLContext instance describing the various SSL options. See HTTPSConnection for more details.
The optional cafile and capath parameters specify a set of trusted CA certificates for HTTPS requests. cafile should point to a single file containing a bundle of CA certificates, whereas capath should point to a directory of hashed certificate files. More information can be found in ssl.SSLContext.load_verify_locations().
The cadefault parameter is ignored.
虽然urlopen方法有特别多参数,但是比较重要的是url,data,url可以放网址也可以放URL类型的对象,data它要是字节流编码格式的内容,即 bytes 类型,通过 bytes() 方法可以进行转化,另外如果传递了这个 data 参数,它的请求方式就不再是 GET 方式请求,而是 POST。
我们先用一行代码看下效果:
import urllib.request//导入相应的库
url="http://fanyi.youdao.com/"
response=urllib.request.urlopen(url)
print(response)
输出为:
<http.client.HTTPResponse object at 0x0000020629F4E6C8>
要知道urlopen方法返回的是一个对象(这个对象对于爬不同的类型,返回的对象不同,详细见下面引用)。这个对象有具有三个方法:geturl() ,info() ,getcode()
read() , readline() ,readlines() , fileno() , close() 。
For HTTP and HTTPS URLs , this function returns a http.client.HTTPResponse object slightly modified. In addition to the three new methods above, the msg attribute contains the same information as the reason attribute — the reason phrase returned by server — instead of the response headers as it is specified in the documentation for HTTPResponse.
For FTP , file , and data URLs and requests explicitly handled by legacy URLopener and FancyURLopener classes, this function returns a urllib.response.addinfourl object.
根据上面的官方解释我们爬的html的格式,所以他返回的是一个http.client.HTTPResponse 类型的对象。我们使用read()方法来读取返回的对象并将它写入文件中
代码:
import urllib.request
url="http://fanyi.youdao.com/"
request=urllib.request.urlopen(url)
u=request.read().decode()
y=open("youdao.html","wb")
y.write(u)
y.close()
运行后我们就可以获得youdao.html的文件,如果用浏览器打开就可以看到是有道翻译官网了。所以使用urlopen方法可以将网页的代码爬下来。
data讲解:
data must be an object specifying additional data to be sent to the server, or None if no such data is needed. See Request for details.
要知道我们发送请求的时候需要携带一定的信息,比如我们说做的翻译爬虫,我们将要翻译的内容输入Edit里,然后点翻译,于是浏览器就将你输入的内容传送到有道翻译的服务器,在服务器的处理(翻译)再返还给浏览器,浏览器解码后,显示给用户。所以浏览网站的时候是需要发送一定的信息的。我们使用urlopen方法的时候没有输入data的时候默认值是None,但是在发送请求的时候还是会发送信息,只不过这个信息是urllib库默认的。既然我们需要将我要翻译的内容发送给有道翻译服务器,所以我们要自定义data的内容。
我们通过浏览器,捕捉到以下信息:
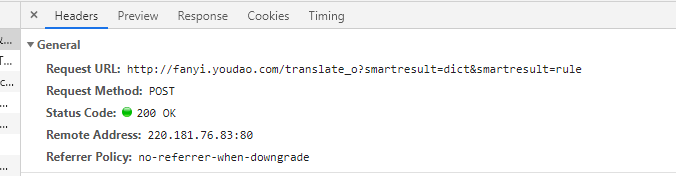 在Request URL:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule 这个才是真正的翻译服务器,所以url存放这个网址,值得注意的是将translate后的_o删掉才是真正有效的网址。
在Request URL:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule 这个才是真正的翻译服务器,所以url存放这个网址,值得注意的是将translate后的_o删掉才是真正有效的网址。
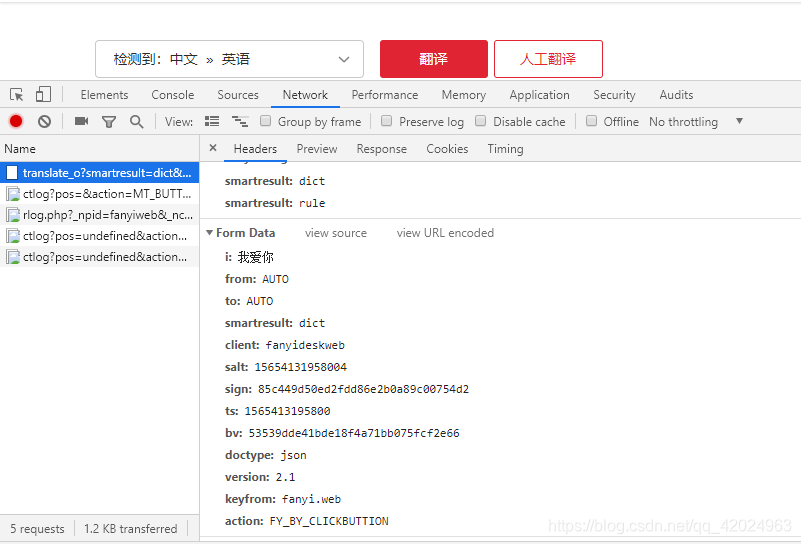
我们从图片可以看到,在form data里面有几行信息,并且他的保存形式很像python里的字典储存模式,所以我们使用字典来储存他们,我要翻译的内容是我爱你,从截图上看,他将我们要翻译的内容保存在i这个key(关键字)中所以我们只要修改i内的内容就可以翻译出我们需要的内容。
data={}
data[i]: '我爱你'
data['from']='AUTO'
data['to']='AUTO'
data['smartresult']='dict'
data['client' ]='fanyideskweb'
data['salt']='15654131958004'
data['sign']='85c449d50ed2fdd86e2b0a89c00754d2'
data['ts']='1565413195800'
data['bv' ]='53539dde41bde18f4a71bb075fcf2e66'
data['doctype'] ='json'
data['version' ]='2.1'
data['keyfrom']=' fanyi.web'
data['action']='FY_BY_CLICKBUTTION'
这样我们就定义了data的值,值得注意的是,我们的data是byte类型,有两种方式将这些信息转换成byte类型一个是使用urllib中parse模块他的作用就是将组件组合回URL字符串,另一个是用byte()方法。在这里我们使用urlencode方法。
以下是官方的解释:
urllib.parse.urlencode(query, doseq=False, safe=’’, encoding=None, errors=None, quote_via=quote_plus)
Convert a mapping object or a sequence of two-element tuples, which may contain str or bytes objects, to a percent-encoded ASCII text string. If the resultant string is to be used as a data for POST operation with the urlopen() function, then it should be encoded to bytes, otherwise it would result in a TypeError.
这个方法是将可能包含str或bytes对象的映射对象或双元素元组序列转换为百分比编码的ASCII文本字符串。如果生成的字符串用作urlopen()函数的POST操作的数据,那么应该将其编码为字节(这里用encode()方法),否则会导致类型错误。还有一种方法是使用byte方法将数据转化成byte对象。在这里我们使用urlencode方法来转化成byte对象。
代码:
data=urllib.parse.urlencode(data).encode()
response=urllib.request.urlopen(url,data)//将data放入urlopen函数里
这时候urlopen函数输出出来的是
’ {“type”:“ZH_CN2EN”,“errorCode”:0,“elapsedTime”:1,“translateResult”:[[{“src”:"\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0", "tgt":"I love you" }]]}\n’
这时候输出的是 ***str***类型,但是这字符串里是字典类型存储,并且我们可以看到加粗斜体部分是我们要的结果,如果我们转化成字典类型我们可以轻松只将结果取出,这时候我们使用json库下的loads方法
我们来认识一下json.loads方法
json.loads(s, *, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
Deserialize s (a str, bytes or bytearray instance containing a JSON document) to a Python object using this conversion table.
json.loads方法可以将string反序化成python对象,这里可以将str反序化成dict类型,我们用代码运行一下
result=json.loads(html)
输出后的结果变成将str类型变成了dict类型
{‘type’: ‘ZH_CN2EN’, ‘errorCode’: 0, ‘elapsedTime’: 2, ‘translateResult’: [[{‘src’: ‘我爱你’, ‘tgt’: ‘I love you’}]]}
我们就根据字典的访问方法将最后结果取出来就行
以下是全部代码:
import urllib.request
import urllib.parse
import json
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
i=input("输入要翻译的内容:\n")
data={}
data['i']= i
data['from']='AUTO'
data['to']='AUTO'
data['smartresult']='dict'
data['client'] ='fanyideskweb'
data['salt']='15654131958004'
data['sign']='85c449d50ed2fdd86e2b0a89c00754d2'
data['ts']='1565413195800'
data['bv']='53539dde41bde18f4a71bb075fcf2e66'
data['doctype']='json'
data['version']='2.1'
data['keyfrom']='fanyi.web'
data['action']='FY_BY_CLICKBUTTION'
data=urllib.parse.urlencode(data).encode()
response=urllib.request.urlopen(url,data)
html=response.read()
result=json.loads(html)
result=result['translateResult'][0][0]['tgt']
print("翻译结果:\n"+result)

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









